
DualViTok
Collection
Dual Vision Tokenizer
•
2 items
•
Updated
![]()
📄 Paper | 🌐 Project-Page | 📦 Github |
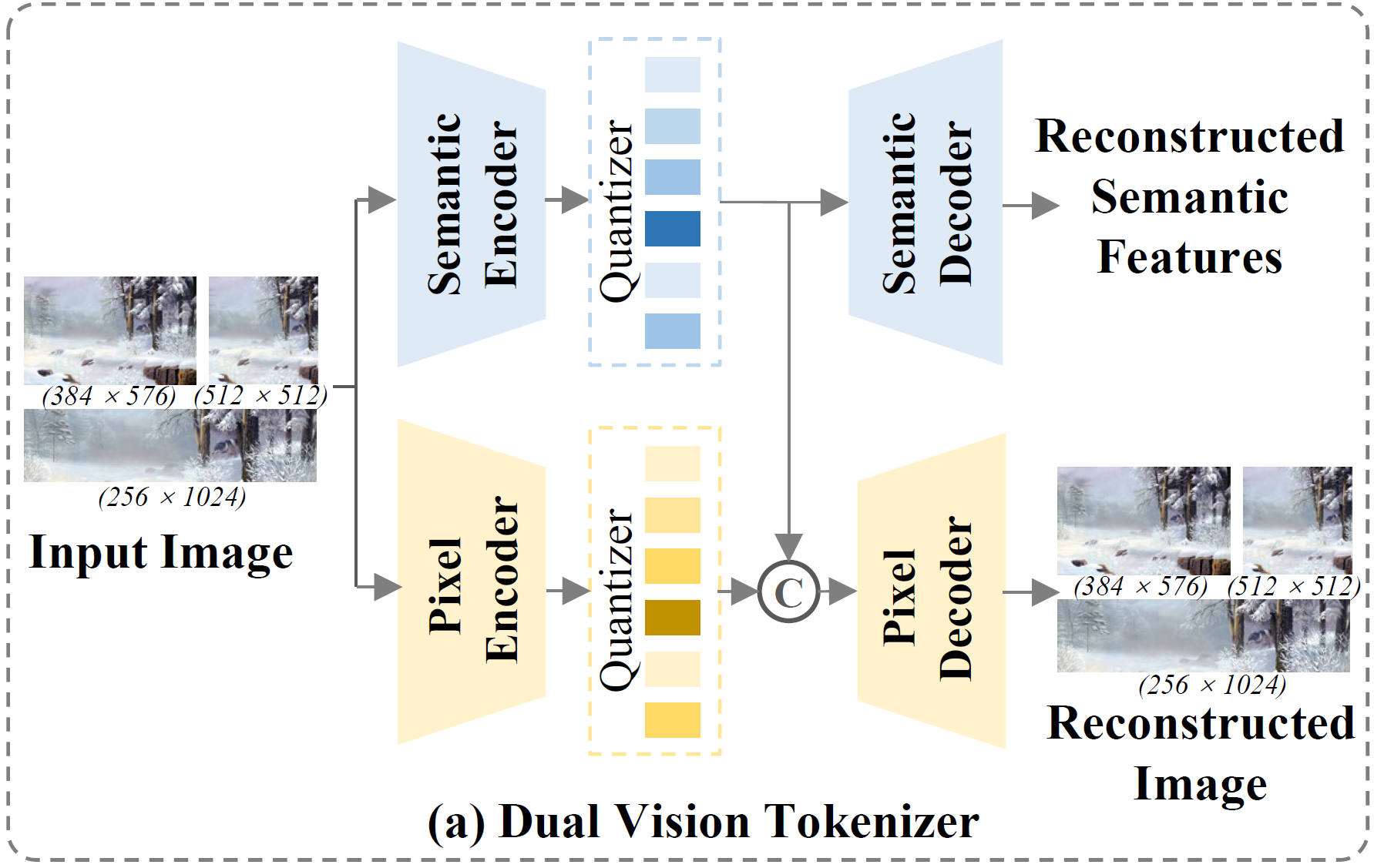
DualViTok, Dual Vision Tokenizer, is a dual-branch vision tokenizer designed to capture both deep semantics and fine-grained textures. It is proposed in ILLUME+. The semantic branch utilizes a pre-trained text-aligned vision encoder for semantic feature extraction, supervised by feature reconstruction loss. In parallel, the pixel branch integrates quantized features from both the semantic encoder and a CNN-based pixel encoder to enhance pixel-level reconstruction. To improve robustness against incorrect token predictions in autoregressive generation, we introduce noise injection during training by randomly perturbing visual tokens. Despite its simplicity, DualViTok is specifically designed for unified models, ensuring both semantic and texture preservation while maintaining robust token decoding.
from PIL import Image
import torch
from transformers import AutoModel, AutoImageProcessor
MODEL_HUB = "ILLUME-MLLM/dualvitok"
model = AutoModel.from_pretrained(MODEL_HUB, trust_remote_code=True).eval().cuda()
processor = AutoImageProcessor.from_pretrained(MODEL_HUB, trust_remote_code=True)
# load the diffusion decoder.
# diffusion_decoder = model.build_sdxl_decoder('ILLUME-MLLM/dualvitok-sdxl-decoder')
# TODO: you need to modify the path here
IMAGE_PATH = "YOUR_IMAGE_PATH"
image = Image.open(IMAGE_PATH)
image = processor(image, return_tensors="pt")["pixel_values"]
image = image.cuda()
with torch.no_grad():
(quant_semantic, diff_semantic, indices_semantic, _), \
(quant_pixel, diff_pixel, indices_pixel) = model.encode(image)
recon = model.decode(quant_semantic, quant_pixel)
# decode from the codes.
# recon = model.decode_code(indices_semantic, indices_pixel)
print(recon.shape)
recon_image = processor.postprocess(recon)["pixel_values"][0]
recon_image.save("recon_image.png")
# diffusion decoder only support 11 resolution. Check here `diffusion_decoder.resolution_group`.
# diffusion_recon = diffusion_decoder(# use vq_indices or vq_embeds
# vq_indices=(indices_semantic, indices_pixel),
# vq_embeds=(quant_semantic, quant_pixel),
# height = height * 2,
# width = width * 2,
# num_inference_steps = 50,
# guidance_scale = 1.5,)
# diffusion_recon.images[0].save("diffusion_recon_image.png")