各家AI划地盘:你以为的公开数据,其实被"圈地"了


最近我做了一个有趣的实验。
把同样一个问题分别问了搜索引擎, 聊天机器人, 包括ChatGPT、Gemini、Perplexity和Grok等模型,结果发现:有些问题它们得出的相似的结论,但另一些问题,这些AI却像是在描述多维平行世界。
更奇怪的是,现在的AI都会给出信息来源链接,点进去看,真的是不同的平台、不同的文章。
这让我很困惑——互联网上的信息不都是公开的吗?为什么同样是"联网搜索",这些AI看到的却是不同的世界?
带着这个疑问,我深入研究了一番。答案比我预想的要复杂得多,也有趣得多。
你以为的"联网搜索",其实是"代理搜索"
我们先来理清一个基础概念。
当你问ChatGPT一个问题,它说"让我搜索一下"的时候,发生了什么?
很多人以为AI是像我们一样打开浏览器,在百度或谷歌里输入关键词,然后一页一页翻看结果。但实际情况完全不同。
这些AI并没有真的"上网冲浪",它们是通过调用特定的搜索引擎API来获取信息的。这就像是你雇了一个助理去图书馆帮你查资料,但每个助理只被允许去特定的图书馆,而且每个图书馆的藏书和分类方式都不一样。
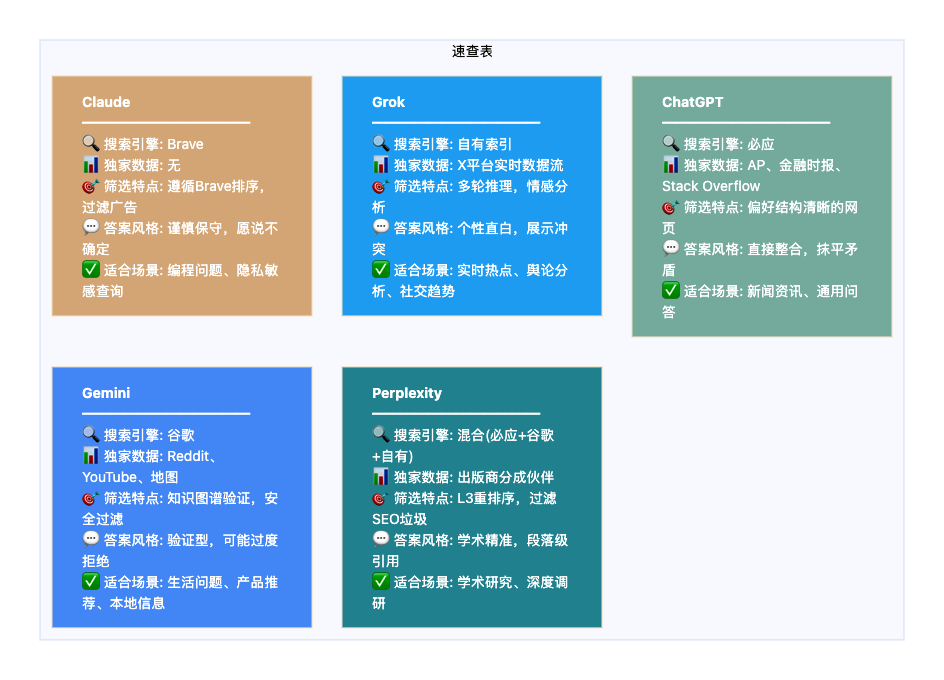
ChatGPT用的是微软必应的搜索引擎。这是微软对OpenAI投资数十亿美元后达成的合作。所以当ChatGPT搜索时,它看到的本质上是必应的搜索结果。
Claude则选择了一条独立路线,它用的是Brave搜索引擎。Brave是一个强调隐私保护的独立搜索引擎,它的索引库比谷歌和必应都小,但会过滤掉大量的垃圾内容和广告网站。
Gemini自然用的是谷歌自家的搜索引擎,这是全球最大的网页索引库,还能直接调用谷歌地图、谷歌航班等垂直服务的数据。
Perplexity比较特殊,它是一个"混合型"选手,同时调用必应和谷歌的结果,还有自己的爬虫在网上抓取内容。
Grok则更独特——它不仅有自己的网页索引,还独家接入了X平台(原推特)的实时数据流,能看到其他AI看不到的社交媒体内容。
光是搜索引擎的不同,就已经决定了这些AI的"信息视野"存在根本差异。
下面这张图直观展示了五个主流AI的搜索架构差异:

同一片大海,不同的渔网
即使两个AI都用同一个搜索引擎,它们的答案也可能完全不同。因为搜到什么和选择引用什么是两回事。
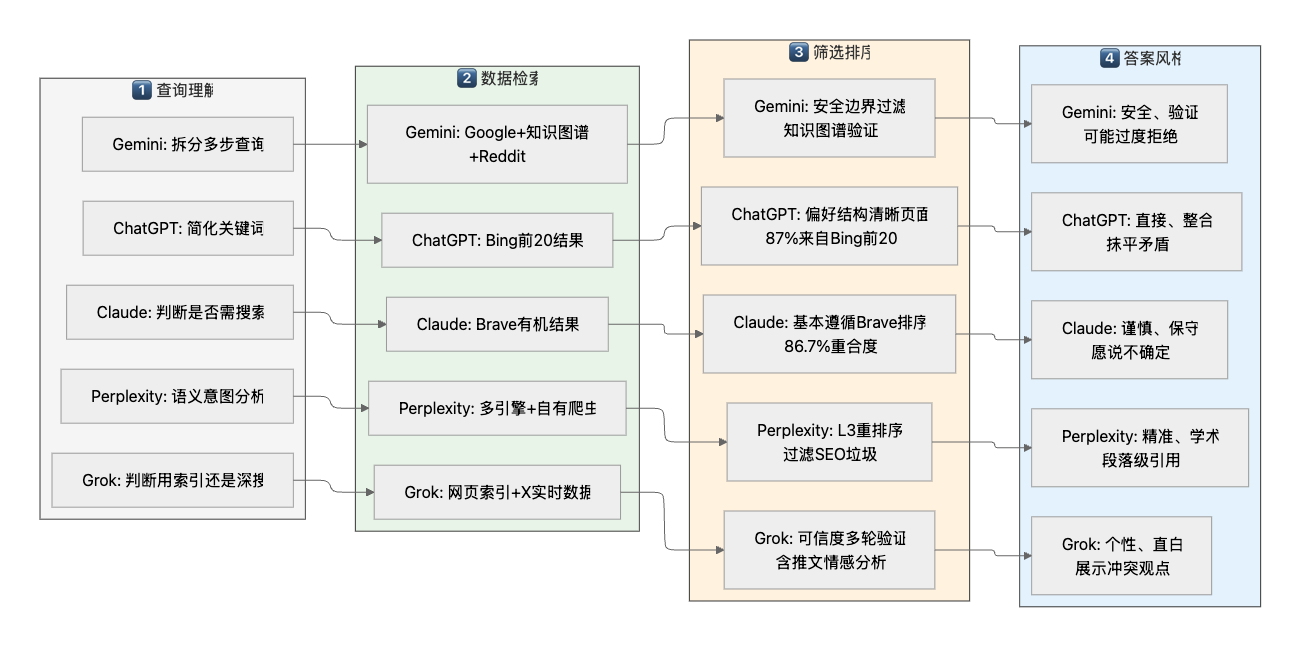
ChatGPT的搜索方式很有意思。研究显示,它大约87%的引用来自必应搜索结果的前20名,但它不会机械地按排名选择。它有自己的"偏好"——更喜欢那些HTML结构清晰、有明确标题和段落的网页。
这意味着一个小型博客,如果页面设计清爽、内容条理分明,可能会被ChatGPT优先引用,而一个权威但页面杂乱的大网站反而被跳过。有研究发现,一个叫Flow Ninja的小众博客被ChatGPT引用的频率,甚至超过了知名的技术网站GeeksforGeeks,原因就是前者的页面更机器友好。
Claude的风格则完全不同。它对Brave搜索结果的"忠诚度"很高,基本上Brave排什么顺序,它就按什么顺序引用,不会做太多二次筛选。这让Claude的答案更"原汁原味",但也意味着它更依赖Brave的排序算法。
Perplexity是这群AI里的"学霸"。它不仅搜索整个网页,还会深入到页面内部,提取最相关的段落甚至句子。它有一套叫做L3的重排序系统,用机器学习模型来评估每个搜索结果的"信息密度"——如果一个页面全是关键词堆砌的SEO内容,即使排名很高也会被过滤掉。

Grok的特点在于它把社交媒体上的讨论当作一手信息来源。当你问"大家对某件事怎么看"的时候,其他AI只能去找新闻评论文章,而Grok可以直接分析成千上万条真实用户的发帖,给你一个"舆论温度计"式的答案。
为了更清晰地对比,我把五个AI的搜索筛选逻辑整理成了下面这张流程图:
看不见的" 数据领地 "
接下来要说的,可能是最让人意外的部分。
我们总以为互联网是开放的、公共的,所有搜索引擎都能看到同样的内容。但现实是,一场悄然进行的数据"跑马圈地", 正在重塑这个格局。
2024年初,谷歌和Reddit签署了一份据说价值6000万美元的年度协议。根据这份协议,谷歌获得了Reddit数据的优先访问权。与此同时,Reddit开始屏蔽其他搜索引擎和AI的爬虫。
这意味着什么?当你问Gemini"2025年最值得买的咖啡机是哪款",它可以调取Reddit上数千条真实用户的讨论和推荐。但ChatGPT和Claude只能看到一些过时的缓存数据,或者不得不依赖那些可能带有商业利益的测评网站。

OpenAI也在做类似的事。它和美联社、《金融时报》、《世界报》等一批主流媒体签订了授权协议。这些VIP合作伙伴的内容在ChatGPT的搜索结果中享有优先待遇。而没有签约的独立媒体或小众网站,即使内容质量更高,也可能被排在后面。
Perplexity则推出了出版商分成计划,《时代》杂志、《财富》等媒体加入后,当它们的内容被引用时可以获得广告分成。虽然官方声称这不会影响排序,但经济激励的逻辑摆在那里,很难说完全没有影响。
我们正在进入一个数据领地化的阶段——你能获得什么答案,取决于你使用的AI和哪些数据提供方签了约。
这张图展示了当前AI领域的数据授权版图:

性格迥异的"信息管家"
最后还有一层差异,来自这些AI各自的"性格设定"。
即使获取了完全相同的信息,不同的AI处理方式也不一样。
ChatGPT的隐藏指令要求它"避免不必要的复杂性",给出"直接"的答案。所以它倾向于把搜索到的多个信息源整合成一个连贯的叙事,抹平其中的矛盾和争议。这让答案读起来很流畅,但可能会丢失一些复杂性。
Claude受到宪法AI理念的影响,更加谨慎和保守。它会在搜索前先"思考"一下是否真的需要搜索,也更愿意说"我不确定",而不是勉强给出一个可能有问题的答案。
Grok的设定则完全是另一个画风。它被要求带有幽默感和讽刺意味,不回避争议话题,甚至会主动展示冲突的观点。这让它的答案更"有个性",但也更容易卷入争议。
Gemini有严格的安全边界设定,对涉及敏感话题的搜索结果会进行过滤。这让它的答案更"安全",但有时也会出现"过度拒绝"的情况——明明是正常的学术问题,却因为沾了敏感词边而不愿回答。
二十年前,我们以为搜索引擎会让所有人看到同一个互联网。十年前,我们发现算法推荐让每个人看到的内容开始分化。而今天,AI搜索正在创造一个更复杂的局面——不同的语言模型,基于不同的数据来源、不同的商业合作、不同的价值判断,正在构建出多个并行的信息现实。
当谷歌为Reddit数据支付6000万美元年费,当OpenAI与主流媒体签订独家协议,当Grok独享X平台的实时数据流——"公开互联网"这个概念本身正在被重新定义。数据仍然存在于服务器上,但谁能调取它、谁能引用它、谁能让用户看到它,已经成为一场新的资源分配。
从更长远的视角看,这或许是信息传播史上的又一次结构性转变。印刷术让知识从教会走向大众,互联网让信息从机构走向个人,而AI搜索可能会让"真相"从单一走向多元——或者说,从"共识"走向"版本"。
不过仔细想想,这和我们日常生活中的经验其实是相通的。
我们从小就在学一件事:找对人问对事。看病找医生,修车找技师,法律问题咨询律师。不是因为其他人不懂,而是因为每个人的知识结构、信息来源和立场视角都不一样。找对人,能更快更准地解决问题,少走弯路。
AI工具也是一样。它们不是全知全能的神谕,而是各有所长、各有局限的"专家"。当AI在我们生活中的占比越来越大,我们和它们打交道的方式,其实也需要这种"找对人"的智慧。
不是哪个AI更好,而是它们为什么不同。理解了这些,选择权就回到了你手里。
附:五大AI搜索特性速查表