Get trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe

BeepBank-500: A Synthetic Earcon Mini-Corpus for UI Sound Research and Psychoacoustics Research
We introduce BeepBank-500, a compact, fully synthetic earcon/alert dataset (300-500 clips) designed for rapid, rights-clean experimentation in human-computer interaction and audio machine learning. Each clip is generated from a parametric recipe controlling waveform family (sine, square, triangle, FM), fundamental frequency, duration, amplitude envelope, amplitude modulation (AM), and lightweight Schroeder-style reverberation. We use three reverberation settings: dry, and two synthetic rooms denoted 'rir small' ('small') and 'rir medium' ('medium') throughout the paper and in the metadata. We release mono 48 kHz WAV audio (16-bit), a rich metadata table (signal/spectral features), and tiny reproducible baselines for (i) waveform-family classification and (ii) f0 regression on single tones. The corpus targets tasks such as earcon classification, timbre analyses, and onset detection, with clearly stated licensing and limitations. Audio is dedicated to the public domain via CC0-1.0; code is under MIT. Data DOI: https://doi.org/10.5281/zenodo.17172015. Code: https://github.com/mandip42/earcons-mini-500.

Automatic channel selection and spatial feature integration for multi-channel speech recognition across various array topologies
Automatic Speech Recognition (ASR) has shown remarkable progress, yet it still faces challenges in real-world distant scenarios across various array topologies each with multiple recording devices. The focal point of the CHiME-7 Distant ASR task is to devise a unified system capable of generalizing various array topologies that have multiple recording devices and offering reliable recognition performance in real-world environments. Addressing this task, we introduce an ASR system that demonstrates exceptional performance across various array topologies. First of all, we propose two attention-based automatic channel selection modules to select the most advantageous subset of multi-channel signals from multiple recording devices for each utterance. Furthermore, we introduce inter-channel spatial features to augment the effectiveness of multi-frame cross-channel attention, aiding it in improving the capability of spatial information awareness. Finally, we propose a multi-layer convolution fusion module drawing inspiration from the U-Net architecture to integrate the multi-channel output into a single-channel output. Experimental results on the CHiME-7 corpus with oracle segmentation demonstrate that the improvements introduced in our proposed ASR system lead to a relative reduction of 40.1% in the Macro Diarization Attributed Word Error Rates (DA-WER) when compared to the baseline ASR system on the Eval sets.

The CHiME-7 Challenge: System Description and Performance of NeMo Team's DASR System
We present the NVIDIA NeMo team's multi-channel speech recognition system for the 7th CHiME Challenge Distant Automatic Speech Recognition (DASR) Task, focusing on the development of a multi-channel, multi-speaker speech recognition system tailored to transcribe speech from distributed microphones and microphone arrays. The system predominantly comprises of the following integral modules: the Speaker Diarization Module, Multi-channel Audio Front-End Processing Module, and the ASR Module. These components collectively establish a cascading system, meticulously processing multi-channel and multi-speaker audio input. Moreover, this paper highlights the comprehensive optimization process that significantly enhanced our system's performance. Our team's submission is largely based on NeMo toolkits and will be publicly available.


Efficient and Generalizable Speaker Diarization via Structured Pruning of Self-Supervised Models
Self-supervised learning (SSL) models such as WavLM have brought substantial improvements to speaker diarization by providing rich contextual representations. However, the high computational and memory costs of these models hinder their deployment in real-time and resource-constrained scenarios. In this work, we present a comprehensive study on compressing SSL-based diarization models through structured pruning guided by knowledge distillation. Building upon our previous work, we extend the analysis to include pruning objectives based on multiply-accumulate operations (MACs), investigate module-wise and progressive pruning strategies, and examine the impact of training data quantity. Experimental results show that our method reduces model size by up to 80% without degrading performance, achieving up to 4x faster inference on a single GPU. We further perform large-scale evaluations on a diverse compound dataset comprising eight public diarization corpora, where our best pruned model achieves state-of-the-art performance across most conditions. Additionally, we show strong generalization to the CHiME-6 dataset, attaining performance comparable to the third-place system in the CHiME-7 challenge without any domain adaptation. All models and code are publicly released to support reproducibility and future research.
AISHELL-5: The First Open-Source In-Car Multi-Channel Multi-Speaker Speech Dataset for Automatic Speech Diarization and Recognition
This paper delineates AISHELL-5, the first open-source in-car multi-channel multi-speaker Mandarin automatic speech recognition (ASR) dataset. AISHLL-5 includes two parts: (1) over 100 hours of multi-channel speech data recorded in an electric vehicle across more than 60 real driving scenarios. This audio data consists of four far-field speech signals captured by microphones located on each car door, as well as near-field signals obtained from high-fidelity headset microphones worn by each speaker. (2) a collection of 40 hours of real-world environmental noise recordings, which supports the in-car speech data simulation. Moreover, we also provide an open-access, reproducible baseline system based on this dataset. This system features a speech frontend model that employs speech source separation to extract each speaker's clean speech from the far-field signals, along with a speech recognition module that accurately transcribes the content of each individual speaker. Experimental results demonstrate the challenges faced by various mainstream ASR models when evaluated on the AISHELL-5. We firmly believe the AISHELL-5 dataset will significantly advance the research on ASR systems under complex driving scenarios by establishing the first publicly available in-car ASR benchmark.

Multi-task self-supervised learning for Robust Speech Recognition
Despite the growing interest in unsupervised learning, extracting meaningful knowledge from unlabelled audio remains an open challenge. To take a step in this direction, we recently proposed a problem-agnostic speech encoder (PASE), that combines a convolutional encoder followed by multiple neural networks, called workers, tasked to solve self-supervised problems (i.e., ones that do not require manual annotations as ground truth). PASE was shown to capture relevant speech information, including speaker voice-print and phonemes. This paper proposes PASE+, an improved version of PASE for robust speech recognition in noisy and reverberant environments. To this end, we employ an online speech distortion module, that contaminates the input signals with a variety of random disturbances. We then propose a revised encoder that better learns short- and long-term speech dynamics with an efficient combination of recurrent and convolutional networks. Finally, we refine the set of workers used in self-supervision to encourage better cooperation. Results on TIMIT, DIRHA and CHiME-5 show that PASE+ significantly outperforms both the previous version of PASE as well as common acoustic features. Interestingly, PASE+ learns transferable representations suitable for highly mismatched acoustic conditions.

A Large Dataset of Spontaneous Speech with the Accent Spoken in São Paulo for Automatic Speech Recognition Evaluation
We present a freely available spontaneous speech corpus for the Brazilian Portuguese language and report preliminary automatic speech recognition (ASR) results, using both the Wav2Vec2-XLSR-53 and Distil-Whisper models fine-tuned and trained on our corpus. The NURC-SP Audio Corpus comprises 401 different speakers (204 females, 197 males) with a total of 239.30 hours of transcribed audio recordings. To the best of our knowledge, this is the first large Paulistano accented spontaneous speech corpus dedicated to the ASR task in Portuguese. We first present the design and development procedures of the NURC-SP Audio Corpus, and then describe four ASR experiments in detail. The experiments demonstrated promising results for the applicability of the corpus for ASR. Specifically, we fine-tuned two versions of Wav2Vec2-XLSR-53 model, trained a Distil-Whisper model using our dataset with labels determined by Whisper Large-V3 model, and fine-tuned this Distil-Whisper model with our corpus. Our best results were the Distil-Whisper fine-tuned over NURC-SP Audio Corpus with a WER of 24.22% followed by a fine-tuned versions of Wav2Vec2-XLSR-53 model with a WER of 33.73%, that is almost 10% point worse than Distil-Whisper's. To enable experiment reproducibility, we share the NURC-SP Audio Corpus dataset, pre-trained models, and training recipes in Hugging-Face and Github repositories.


DiPCo -- Dinner Party Corpus
We present a speech data corpus that simulates a "dinner party" scenario taking place in an everyday home environment. The corpus was created by recording multiple groups of four Amazon employee volunteers having a natural conversation in English around a dining table. The participants were recorded by a single-channel close-talk microphone and by five far-field 7-microphone array devices positioned at different locations in the recording room. The dataset contains the audio recordings and human labeled transcripts of a total of 10 sessions with a duration between 15 and 45 minutes. The corpus was created to advance in the field of noise robust and distant speech processing and is intended to serve as a public research and benchmarking data set.
SpeechStew: Simply Mix All Available Speech Recognition Data to Train One Large Neural Network
We present SpeechStew, a speech recognition model that is trained on a combination of various publicly available speech recognition datasets: AMI, Broadcast News, Common Voice, LibriSpeech, Switchboard/Fisher, Tedlium, and Wall Street Journal. SpeechStew simply mixes all of these datasets together, without any special re-weighting or re-balancing of the datasets. SpeechStew achieves SoTA or near SoTA results across a variety of tasks, without the use of an external language model. Our results include 9.0\% WER on AMI-IHM, 4.7\% WER on Switchboard, 8.3\% WER on CallHome, and 1.3\% on WSJ, which significantly outperforms prior work with strong external language models. We also demonstrate that SpeechStew learns powerful transfer learning representations. We fine-tune SpeechStew on a noisy low resource speech dataset, CHiME-6. We achieve 38.9\% WER without a language model, which compares to 38.6\% WER to a strong HMM baseline with a language model.
MUSAN: A Music, Speech, and Noise Corpus
This report introduces a new corpus of music, speech, and noise. This dataset is suitable for training models for voice activity detection (VAD) and music/speech discrimination. Our corpus is released under a flexible Creative Commons license. The dataset consists of music from several genres, speech from twelve languages, and a wide assortment of technical and non-technical noises. We demonstrate use of this corpus for music/speech discrimination on Broadcast news and VAD for speaker identification.
LOTUSDIS: A Thai far-field meeting corpus for robust conversational ASR
We present LOTUSDIS, a publicly available Thai meeting corpus designed to advance far-field conversational ASR. The dataset comprises 114 hours of spontaneous, unscripted dialogue collected in 15-20 minute sessions with three participants, where overlapping speech is frequent and natural. Speech was recorded simultaneously by nine independent single-channel devices spanning six microphone types at distances from 0.12 m to 10 m, preserving the authentic effects of reverberation, noise, and device coloration without relying on microphone arrays. We provide standard train, dev, test splits and release a reproducible baseline system. We benchmarked several Whisper variants under zero-shot and fine-tuned conditions. Off-the-shelf models showed strong degradation with distance, confirming a mismatch between pre-training data and Thai far-field speech. Fine-tuning on LOTUSDIS dramatically improved robustness: a Thai Whisper baseline reduced overall WER from 64.3 to 38.3 and far-field WER from 81.6 to 49.5, with especially large gains on the most distant microphones. These results underscore the importance of distance-diverse training data for robust ASR. The corpus is available under CC-BY-SA 4.0. We also release training and evaluation scripts as a baseline system to promote reproducible research in this field.
FSD50K: An Open Dataset of Human-Labeled Sound Events
Most existing datasets for sound event recognition (SER) are relatively small and/or domain-specific, with the exception of AudioSet, based on over 2M tracks from YouTube videos and encompassing over 500 sound classes. However, AudioSet is not an open dataset as its official release consists of pre-computed audio features. Downloading the original audio tracks can be problematic due to YouTube videos gradually disappearing and usage rights issues. To provide an alternative benchmark dataset and thus foster SER research, we introduce FSD50K, an open dataset containing over 51k audio clips totalling over 100h of audio manually labeled using 200 classes drawn from the AudioSet Ontology. The audio clips are licensed under Creative Commons licenses, making the dataset freely distributable (including waveforms). We provide a detailed description of the FSD50K creation process, tailored to the particularities of Freesound data, including challenges encountered and solutions adopted. We include a comprehensive dataset characterization along with discussion of limitations and key factors to allow its audio-informed usage. Finally, we conduct sound event classification experiments to provide baseline systems as well as insight on the main factors to consider when splitting Freesound audio data for SER. Our goal is to develop a dataset to be widely adopted by the community as a new open benchmark for SER research.
Golos: Russian Dataset for Speech Research
This paper introduces a novel Russian speech dataset called Golos, a large corpus suitable for speech research. The dataset mainly consists of recorded audio files manually annotated on the crowd-sourcing platform. The total duration of the audio is about 1240 hours. We have made the corpus freely available to download, along with the acoustic model with CTC loss prepared on this corpus. Additionally, transfer learning was applied to improve the performance of the acoustic model. In order to evaluate the quality of the dataset with the beam-search algorithm, we have built a 3-gram language model on the open Common Crawl dataset. The total word error rate (WER) metrics turned out to be about 3.3% and 11.5%.

RyanSpeech: A Corpus for Conversational Text-to-Speech Synthesis
This paper introduces RyanSpeech, a new speech corpus for research on automated text-to-speech (TTS) systems. Publicly available TTS corpora are often noisy, recorded with multiple speakers, or lack quality male speech data. In order to meet the need for a high quality, publicly available male speech corpus within the field of speech recognition, we have designed and created RyanSpeech which contains textual materials from real-world conversational settings. These materials contain over 10 hours of a professional male voice actor's speech recorded at 44.1 kHz. This corpus's design and pipeline make RyanSpeech ideal for developing TTS systems in real-world applications. To provide a baseline for future research, protocols, and benchmarks, we trained 4 state-of-the-art speech models and a vocoder on RyanSpeech. The results show 3.36 in mean opinion scores (MOS) in our best model. We have made both the corpus and trained models for public use.
Zero-Shot vs. Few-Shot Multi-Speaker TTS Using Pre-trained Czech SpeechT5 Model
In this paper, we experimented with the SpeechT5 model pre-trained on large-scale datasets. We pre-trained the foundation model from scratch and fine-tuned it on a large-scale robust multi-speaker text-to-speech (TTS) task. We tested the model capabilities in a zero- and few-shot scenario. Based on two listening tests, we evaluated the synthetic audio quality and the similarity of how synthetic voices resemble real voices. Our results showed that the SpeechT5 model can generate a synthetic voice for any speaker using only one minute of the target speaker's data. We successfully demonstrated the high quality and similarity of our synthetic voices on publicly known Czech politicians and celebrities.
MSR-86K: An Evolving, Multilingual Corpus with 86,300 Hours of Transcribed Audio for Speech Recognition Research
Recently, multilingual artificial intelligence assistants, exemplified by ChatGPT, have gained immense popularity. As a crucial gateway to human-computer interaction, multilingual automatic speech recognition (ASR) has also garnered significant attention, as evidenced by systems like Whisper. However, the proprietary nature of the training data has impeded researchers' efforts to study multilingual ASR. This paper introduces MSR-86K, an evolving, large-scale multilingual corpus for speech recognition research. The corpus is derived from publicly accessible videos on YouTube, comprising 15 languages and a total of 86,300 hours of transcribed ASR data. We also introduce how to use the MSR-86K corpus and other open-source corpora to train a robust multilingual ASR model that is competitive with Whisper. MSR-86K will be publicly released on HuggingFace, and we believe that such a large corpus will pave new avenues for research in multilingual ASR.
speechocean762: An Open-Source Non-native English Speech Corpus For Pronunciation Assessment
This paper introduces a new open-source speech corpus named "speechocean762" designed for pronunciation assessment use, consisting of 5000 English utterances from 250 non-native speakers, where half of the speakers are children. Five experts annotated each of the utterances at sentence-level, word-level and phoneme-level. A baseline system is released in open source to illustrate the phoneme-level pronunciation assessment workflow on this corpus. This corpus is allowed to be used freely for commercial and non-commercial purposes. It is available for free download from OpenSLR, and the corresponding baseline system is published in the Kaldi speech recognition toolkit.

Channel-Attention Dense U-Net for Multichannel Speech Enhancement
Supervised deep learning has gained significant attention for speech enhancement recently. The state-of-the-art deep learning methods perform the task by learning a ratio/binary mask that is applied to the mixture in the time-frequency domain to produce the clean speech. Despite the great performance in the single-channel setting, these frameworks lag in performance in the multichannel setting as the majority of these methods a) fail to exploit the available spatial information fully, and b) still treat the deep architecture as a black box which may not be well-suited for multichannel audio processing. This paper addresses these drawbacks, a) by utilizing complex ratio masking instead of masking on the magnitude of the spectrogram, and more importantly, b) by introducing a channel-attention mechanism inside the deep architecture to mimic beamforming. We propose Channel-Attention Dense U-Net, in which we apply the channel-attention unit recursively on feature maps at every layer of the network, enabling the network to perform non-linear beamforming. We demonstrate the superior performance of the network against the state-of-the-art approaches on the CHiME-3 dataset.
Ask2Mask: Guided Data Selection for Masked Speech Modeling
Masked speech modeling (MSM) methods such as wav2vec2 or w2v-BERT learn representations over speech frames which are randomly masked within an utterance. While these methods improve performance of Automatic Speech Recognition (ASR) systems, they have one major limitation. They treat all unsupervised speech samples with equal weight, which hinders learning as not all samples have relevant information to learn meaningful representations. In this work, we address this limitation. We propose ask2mask (ATM), a novel approach to focus on specific samples during MSM pre-training. ATM employs an external ASR model or scorer to weight unsupervised input samples in two different ways: 1) A fine-grained data selection is performed by masking over the highly confident input frames as chosen by the scorer. This allows the model to learn meaningful representations. 2) ATM is further extended to focus at utterance-level by weighting the final MSM loss with the utterance-level confidence score. We conduct fine-tuning experiments on two well-benchmarked corpora: LibriSpeech (matching the pre-training data) and Commonvoice, TED-LIUM, AMI and CHiME-6 (not matching the pre-training data). The results substantiate the efficacy of ATM on significantly improving the recognition performance under mismatched conditions (up to 11.6\% relative over published results and upto 4.46\% relative over our internal baseline) while still yielding modest improvements under matched conditions.
Earnings-21: A Practical Benchmark for ASR in the Wild
Commonly used speech corpora inadequately challenge academic and commercial ASR systems. In particular, speech corpora lack metadata needed for detailed analysis and WER measurement. In response, we present Earnings-21, a 39-hour corpus of earnings calls containing entity-dense speech from nine different financial sectors. This corpus is intended to benchmark ASR systems in the wild with special attention towards named entity recognition. We benchmark four commercial ASR models, two internal models built with open-source tools, and an open-source LibriSpeech model and discuss their differences in performance on Earnings-21. Using our recently released fstalign tool, we provide a candid analysis of each model's recognition capabilities under different partitions. Our analysis finds that ASR accuracy for certain NER categories is poor, presenting a significant impediment to transcript comprehension and usage. Earnings-21 bridges academic and commercial ASR system evaluation and enables further research on entity modeling and WER on real world audio.

JSUT corpus: free large-scale Japanese speech corpus for end-to-end speech synthesis
Thanks to improvements in machine learning techniques including deep learning, a free large-scale speech corpus that can be shared between academic institutions and commercial companies has an important role. However, such a corpus for Japanese speech synthesis does not exist. In this paper, we designed a novel Japanese speech corpus, named the "JSUT corpus," that is aimed at achieving end-to-end speech synthesis. The corpus consists of 10 hours of reading-style speech data and its transcription and covers all of the main pronunciations of daily-use Japanese characters. In this paper, we describe how we designed and analyzed the corpus. The corpus is freely available online.
Treble10: A high-quality dataset for far-field speech recognition, dereverberation, and enhancement
Accurate far-field speech datasets are critical for tasks such as automatic speech recognition (ASR), dereverberation, speech enhancement, and source separation. However, current datasets are limited by the trade-off between acoustic realism and scalability. Measured corpora provide faithful physics but are expensive, low-coverage, and rarely include paired clean and reverberant data. In contrast, most simulation-based datasets rely on simplified geometrical acoustics, thus failing to reproduce key physical phenomena like diffraction, scattering, and interference that govern sound propagation in complex environments. We introduce Treble10, a large-scale, physically accurate room-acoustic dataset. Treble10 contains over 3000 broadband room impulse responses (RIRs) simulated in 10 fully furnished real-world rooms, using a hybrid simulation paradigm implemented in the Treble SDK that combines a wave-based and geometrical acoustics solver. The dataset provides six complementary subsets, spanning mono, 8th-order Ambisonics, and 6-channel device RIRs, as well as pre-convolved reverberant speech scenes paired with LibriSpeech utterances. All signals are simulated at 32 kHz, accurately modelling low-frequency wave effects and high-frequency reflections. Treble10 bridges the realism gap between measurement and simulation, enabling reproducible, physically grounded evaluation and large-scale data augmentation for far-field speech tasks. The dataset is openly available via the Hugging Face Hub, and is intended as both a benchmark and a template for next-generation simulation-driven audio research.




TED-LIUM 3: twice as much data and corpus repartition for experiments on speaker adaptation
In this paper, we present TED-LIUM release 3 corpus dedicated to speech recognition in English, that multiplies by more than two the available data to train acoustic models in comparison with TED-LIUM 2. We present the recent development on Automatic Speech Recognition (ASR) systems in comparison with the two previous releases of the TED-LIUM Corpus from 2012 and 2014. We demonstrate that, passing from 207 to 452 hours of transcribed speech training data is really more useful for end-to-end ASR systems than for HMM-based state-of-the-art ones, even if the HMM-based ASR system still outperforms end-to-end ASR system when the size of audio training data is 452 hours, with respectively a Word Error Rate (WER) of 6.6% and 13.7%. Last, we propose two repartitions of the TED-LIUM release 3 corpus: the legacy one that is the same as the one existing in release 2, and a new one, calibrated and designed to make experiments on speaker adaptation. Like the two first releases, TED-LIUM 3 corpus will be freely available for the research community.

FT Speech: Danish Parliament Speech Corpus
This paper introduces FT Speech, a new speech corpus created from the recorded meetings of the Danish Parliament, otherwise known as the Folketing (FT). The corpus contains over 1,800 hours of transcribed speech by a total of 434 speakers. It is significantly larger in duration, vocabulary, and amount of spontaneous speech than the existing public speech corpora for Danish, which are largely limited to read-aloud and dictation data. We outline design considerations, including the preprocessing methods and the alignment procedure. To evaluate the quality of the corpus, we train automatic speech recognition systems on the new resource and compare them to the systems trained on the Danish part of Sprakbanken, the largest public ASR corpus for Danish to date. Our baseline results show that we achieve a 14.01 WER on the new corpus. A combination of FT Speech with in-domain language data provides comparable results to models trained specifically on Sprakbanken, showing that FT Speech transfers well to this data set. Interestingly, our results demonstrate that the opposite is not the case. This shows that FT Speech provides a valuable resource for promoting research on Danish ASR with more spontaneous speech.

Multi-Span Acoustic Modelling using Raw Waveform Signals
Traditional automatic speech recognition (ASR) systems often use an acoustic model (AM) built on handcrafted acoustic features, such as log Mel-filter bank (FBANK) values. Recent studies found that AMs with convolutional neural networks (CNNs) can directly use the raw waveform signal as input. Given sufficient training data, these AMs can yield a competitive word error rate (WER) to those built on FBANK features. This paper proposes a novel multi-span structure for acoustic modelling based on the raw waveform with multiple streams of CNN input layers, each processing a different span of the raw waveform signal. Evaluation on both the single channel CHiME4 and AMI data sets show that multi-span AMs give a lower WER than FBANK AMs by an average of about 5% (relative). Analysis of the trained multi-span model reveals that the CNNs can learn filters that are rather different to the log Mel filters. Furthermore, the paper shows that a widely used single span raw waveform AM can be improved by using a smaller CNN kernel size and increased stride to yield improved WERs.

BERSting at the Screams: A Benchmark for Distanced, Emotional and Shouted Speech Recognition
Some speech recognition tasks, such as automatic speech recognition (ASR), are approaching or have reached human performance in many reported metrics. Yet, they continue to struggle in complex, real-world, situations, such as with distanced speech. Previous challenges have released datasets to address the issue of distanced ASR, however, the focus remains primarily on distance, specifically relying on multi-microphone array systems. Here we present the B(asic) E(motion) R(andom phrase) S(hou)t(s) (BERSt) dataset. The dataset contains almost 4 hours of English speech from 98 actors with varying regional and non-native accents. The data was collected on smartphones in the actors homes and therefore includes at least 98 different acoustic environments. The data also includes 7 different emotion prompts and both shouted and spoken utterances. The smartphones were places in 19 different positions, including obstructions and being in a different room than the actor. This data is publicly available for use and can be used to evaluate a variety of speech recognition tasks, including: ASR, shout detection, and speech emotion recognition (SER). We provide initial benchmarks for ASR and SER tasks, and find that ASR degrades both with an increase in distance and shout level and shows varied performance depending on the intended emotion. Our results show that the BERSt dataset is challenging for both ASR and SER tasks and continued work is needed to improve the robustness of such systems for more accurate real-world use.
BENYO-S2ST-Corpus-1: A Bilingual English-to-Yoruba Direct Speech-to-Speech Translation Corpus
There is a major shortage of Speech-to-Speech Translation (S2ST) datasets for high resource-to-low resource language pairs such as English-to-Yoruba. Thus, in this study, we curated the Bilingual English-to-Yoruba Speech-to-Speech Translation Corpus Version 1 (BENYO-S2ST-Corpus-1). The corpus is based on a hybrid architecture we developed for large-scale direct S2ST corpus creation at reduced cost. To achieve this, we leveraged non speech-to-speech Standard Yoruba (SY) real-time audios and transcripts in the YORULECT Corpus as well as the corresponding Standard English (SE) transcripts. YORULECT Corpus is small scale(1,504) samples, and it does not have paired English audios. Therefore, we generated the SE audios using pre-trained AI models (i.e. Facebook MMS). We also developed an audio augmentation algorithm named AcoustAug based on three latent acoustic features to generate augmented audios from the raw audios of the two languages. BENYO-S2ST-Corpus-1 has 12,032 audio samples per language, which gives a total of 24,064 sample size. The total audio duration for the two languages is 41.20 hours. This size is quite significant. Beyond building S2ST models, BENYO-S2ST-Corpus-1 can be used to build pretrained models or improve existing ones. The created corpus and Coqui framework were used to build a pretrained Yoruba TTS model (named YoruTTS-0.5) as a proof of concept. The YoruTTS-0.5 gave a F0 RMSE value of 63.54 after 1,000 epochs, which indicates moderate fundamental pitch similarity with the reference real-time audio. Ultimately, the corpus architecture in this study can be leveraged by researchers and developers to curate datasets for multilingual high-resource-to-low-resource African languages. This will bridge the huge digital divides in translations among high and low-resource language pairs. BENYO-S2ST-Corpus-1 and YoruTTS-0.5 are publicly available at (https://bit.ly/40bGMwi).
JVS corpus: free Japanese multi-speaker voice corpus
Thanks to improvements in machine learning techniques, including deep learning, speech synthesis is becoming a machine learning task. To accelerate speech synthesis research, we are developing Japanese voice corpora reasonably accessible from not only academic institutions but also commercial companies. In 2017, we released the JSUT corpus, which contains 10 hours of reading-style speech uttered by a single speaker, for end-to-end text-to-speech synthesis. For more general use in speech synthesis research, e.g., voice conversion and multi-speaker modeling, in this paper, we construct the JVS corpus, which contains voice data of 100 speakers in three styles (normal, whisper, and falsetto). The corpus contains 30 hours of voice data including 22 hours of parallel normal voices. This paper describes how we designed the corpus and summarizes the specifications. The corpus is available at our project page.
Comparison of semi-supervised deep learning algorithms for audio classification
In this article, we adapted five recent SSL methods to the task of audio classification. The first two methods, namely Deep Co-Training (DCT) and Mean Teacher (MT), involve two collaborative neural networks. The three other algorithms, called MixMatch (MM), ReMixMatch (RMM), and FixMatch (FM), are single-model methods that rely primarily on data augmentation strategies. Using the Wide-ResNet-28-2 architecture in all our experiments, 10% of labeled data and the remaining 90% as unlabeled data for training, we first compare the error rates of the five methods on three standard benchmark audio datasets: Environmental Sound Classification (ESC-10), UrbanSound8K (UBS8K), and Google Speech Commands (GSC). In all but one cases, MM, RMM, and FM outperformed MT and DCT significantly, MM and RMM being the best methods in most experiments. On UBS8K and GSC, MM achieved 18.02% and 3.25% error rate (ER), respectively, outperforming models trained with 100% of the available labeled data, which reached 23.29% and 4.94%, respectively. RMM achieved the best results on ESC-10 (12.00% ER), followed by FM which reached 13.33%. Second, we explored adding the mixup augmentation, used in MM and RMM, to DCT, MT, and FM. In almost all cases, mixup brought consistent gains. For instance, on GSC, FM reached 4.44% and 3.31% ER without and with mixup. Our PyTorch code will be made available upon paper acceptance at https:// github. com/ Labbe ti/ SSLH.


ClArTTS: An Open-Source Classical Arabic Text-to-Speech Corpus
At present, Text-to-speech (TTS) systems that are trained with high-quality transcribed speech data using end-to-end neural models can generate speech that is intelligible, natural, and closely resembles human speech. These models are trained with relatively large single-speaker professionally recorded audio, typically extracted from audiobooks. Meanwhile, due to the scarcity of freely available speech corpora of this kind, a larger gap exists in Arabic TTS research and development. Most of the existing freely available Arabic speech corpora are not suitable for TTS training as they contain multi-speaker casual speech with variations in recording conditions and quality, whereas the corpus curated for speech synthesis are generally small in size and not suitable for training state-of-the-art end-to-end models. In a move towards filling this gap in resources, we present a speech corpus for Classical Arabic Text-to-Speech (ClArTTS) to support the development of end-to-end TTS systems for Arabic. The speech is extracted from a LibriVox audiobook, which is then processed, segmented, and manually transcribed and annotated. The final ClArTTS corpus contains about 12 hours of speech from a single male speaker sampled at 40100 kHz. In this paper, we describe the process of corpus creation and provide details of corpus statistics and a comparison with existing resources. Furthermore, we develop two TTS systems based on Grad-TTS and Glow-TTS and illustrate the performance of the resulting systems via subjective and objective evaluations. The corpus will be made publicly available at www.clartts.com for research purposes, along with the baseline TTS systems demo.

Audio-Language Models for Audio-Centric Tasks: A survey
Audio-Language Models (ALMs), which are trained on audio-text data, focus on the processing, understanding, and reasoning of sounds. Unlike traditional supervised learning approaches learning from predefined labels, ALMs utilize natural language as a supervision signal, which is more suitable for describing complex real-world audio recordings. ALMs demonstrate strong zero-shot capabilities and can be flexibly adapted to diverse downstream tasks. These strengths not only enhance the accuracy and generalization of audio processing tasks but also promote the development of models that more closely resemble human auditory perception and comprehension. Recent advances in ALMs have positioned them at the forefront of computer audition research, inspiring a surge of efforts to advance ALM technologies. Despite rapid progress in the field of ALMs, there is still a notable lack of systematic surveys that comprehensively organize and analyze developments. In this paper, we present a comprehensive review of ALMs with a focus on general audio tasks, aiming to fill this gap by providing a structured and holistic overview of ALMs. Specifically, we cover: (1) the background of computer audition and audio-language models; (2) the foundational aspects of ALMs, including prevalent network architectures, training objectives, and evaluation methods; (3) foundational pre-training and audio-language pre-training approaches; (4) task-specific fine-tuning, multi-task tuning and agent systems for downstream applications; (5) datasets and benchmarks; and (6) current challenges and future directions. Our review provides a clear technical roadmap for researchers to understand the development and future trends of existing technologies, offering valuable references for implementation in real-world scenarios.
Common Phone: A Multilingual Dataset for Robust Acoustic Modelling
Current state of the art acoustic models can easily comprise more than 100 million parameters. This growing complexity demands larger training datasets to maintain a decent generalization of the final decision function. An ideal dataset is not necessarily large in size, but large with respect to the amount of unique speakers, utilized hardware and varying recording conditions. This enables a machine learning model to explore as much of the domain-specific input space as possible during parameter estimation. This work introduces Common Phone, a gender-balanced, multilingual corpus recorded from more than 11.000 contributors via Mozilla's Common Voice project. It comprises around 116 hours of speech enriched with automatically generated phonetic segmentation. A Wav2Vec 2.0 acoustic model was trained with the Common Phone to perform phonetic symbol recognition and validate the quality of the generated phonetic annotation. The architecture achieved a PER of 18.1 % on the entire test set, computed with all 101 unique phonetic symbols, showing slight differences between the individual languages. We conclude that Common Phone provides sufficient variability and reliable phonetic annotation to help bridging the gap between research and application of acoustic models.

AHELM: A Holistic Evaluation of Audio-Language Models
Evaluations of audio-language models (ALMs) -- multimodal models that take interleaved audio and text as input and output text -- are hindered by the lack of standardized benchmarks; most benchmarks measure only one or two capabilities and omit evaluative aspects such as fairness or safety. Furthermore, comparison across models is difficult as separate evaluations test a limited number of models and use different prompting methods and inference parameters. To address these shortfalls, we introduce AHELM, a benchmark that aggregates various datasets -- including 2 new synthetic audio-text datasets called PARADE, which evaluates the ALMs on avoiding stereotypes, and CoRe-Bench, which measures reasoning over conversational audio through inferential multi-turn question answering -- to holistically measure the performance of ALMs across 10 aspects we have identified as important to the development and usage of ALMs: audio perception, knowledge, reasoning, emotion detection, bias, fairness, multilinguality, robustness, toxicity, and safety. We also standardize the prompts, inference parameters, and evaluation metrics to ensure equitable comparisons across models. We test 14 open-weight and closed-API ALMs from 3 developers and 3 additional simple baseline systems each consisting of an automatic speech recognizer and a language model. Our results show that while Gemini 2.5 Pro ranks top in 5 out of 10 aspects, it exhibits group unfairness (p=0.01) on ASR tasks whereas most of the other models do not. We also find that the baseline systems perform reasonably well on AHELM, with one ranking 5th overall despite having only speech-to-text capabilities. For transparency, all raw prompts, model generations, and outputs are available on our website at https://crfm.stanford.edu/helm/audio/v1.0.0. AHELM is intended to be a living benchmark and new datasets and models will be added over time.


FLEURS-R: A Restored Multilingual Speech Corpus for Generation Tasks
This paper introduces FLEURS-R, a speech restoration applied version of the Few-shot Learning Evaluation of Universal Representations of Speech (FLEURS) corpus. FLEURS-R maintains an N-way parallel speech corpus in 102 languages as FLEURS, with improved audio quality and fidelity by applying the speech restoration model Miipher. The aim of FLEURS-R is to advance speech technology in more languages and catalyze research including text-to-speech (TTS) and other speech generation tasks in low-resource languages. Comprehensive evaluations with the restored speech and TTS baseline models trained from the new corpus show that the new corpus obtained significantly improved speech quality while maintaining the semantic contents of the speech. The corpus is publicly released via Hugging Face.
AISHELL-3: A Multi-speaker Mandarin TTS Corpus and the Baselines
In this paper, we present AISHELL-3, a large-scale and high-fidelity multi-speaker Mandarin speech corpus which could be used to train multi-speaker Text-to-Speech (TTS) systems. The corpus contains roughly 85 hours of emotion-neutral recordings spoken by 218 native Chinese mandarin speakers. Their auxiliary attributes such as gender, age group and native accents are explicitly marked and provided in the corpus. Accordingly, transcripts in Chinese character-level and pinyin-level are provided along with the recordings. We present a baseline system that uses AISHELL-3 for multi-speaker Madarin speech synthesis. The multi-speaker speech synthesis system is an extension on Tacotron-2 where a speaker verification model and a corresponding loss regarding voice similarity are incorporated as the feedback constraint. We aim to use the presented corpus to build a robust synthesis model that is able to achieve zero-shot voice cloning. The system trained on this dataset also generalizes well on speakers that are never seen in the training process. Objective evaluation results from our experiments show that the proposed multi-speaker synthesis system achieves high voice similarity concerning both speaker embedding similarity and equal error rate measurement. The dataset, baseline system code and generated samples are available online.
Attention Is Not Always the Answer: Optimizing Voice Activity Detection with Simple Feature Fusion
Voice Activity Detection (VAD) plays a key role in speech processing, often utilizing hand-crafted or neural features. This study examines the effectiveness of Mel-Frequency Cepstral Coefficients (MFCCs) and pre-trained model (PTM) features, including wav2vec 2.0, HuBERT, WavLM, UniSpeech, MMS, and Whisper. We propose FusionVAD, a unified framework that combines both feature types using three fusion strategies: concatenation, addition, and cross-attention (CA). Experimental results reveal that simple fusion techniques, particularly addition, outperform CA in both accuracy and efficiency. Fusion-based models consistently surpass single-feature models, highlighting the complementary nature of MFCCs and PTM features. Notably, our best-performing fusion model exceeds the state-of-the-art Pyannote across multiple datasets, achieving an absolute average improvement of 2.04%. These results confirm that simple feature fusion enhances VAD robustness while maintaining computational efficiency.

LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech
This paper introduces a new speech corpus called "LibriTTS" designed for text-to-speech use. It is derived from the original audio and text materials of the LibriSpeech corpus, which has been used for training and evaluating automatic speech recognition systems. The new corpus inherits desired properties of the LibriSpeech corpus while addressing a number of issues which make LibriSpeech less than ideal for text-to-speech work. The released corpus consists of 585 hours of speech data at 24kHz sampling rate from 2,456 speakers and the corresponding texts. Experimental results show that neural end-to-end TTS models trained from the LibriTTS corpus achieved above 4.0 in mean opinion scores in naturalness in five out of six evaluation speakers. The corpus is freely available for download from http://www.openslr.org/60/.
Sparks of Large Audio Models: A Survey and Outlook
This survey paper provides a comprehensive overview of the recent advancements and challenges in applying large language models to the field of audio signal processing. Audio processing, with its diverse signal representations and a wide range of sources--from human voices to musical instruments and environmental sounds--poses challenges distinct from those found in traditional Natural Language Processing scenarios. Nevertheless, Large Audio Models, epitomized by transformer-based architectures, have shown marked efficacy in this sphere. By leveraging massive amount of data, these models have demonstrated prowess in a variety of audio tasks, spanning from Automatic Speech Recognition and Text-To-Speech to Music Generation, among others. Notably, recently these Foundational Audio Models, like SeamlessM4T, have started showing abilities to act as universal translators, supporting multiple speech tasks for up to 100 languages without any reliance on separate task-specific systems. This paper presents an in-depth analysis of state-of-the-art methodologies regarding Foundational Large Audio Models, their performance benchmarks, and their applicability to real-world scenarios. We also highlight current limitations and provide insights into potential future research directions in the realm of Large Audio Models with the intent to spark further discussion, thereby fostering innovation in the next generation of audio-processing systems. Furthermore, to cope with the rapid development in this area, we will consistently update the relevant repository with relevant recent articles and their open-source implementations at https://github.com/EmulationAI/awesome-large-audio-models.

PSELDNets: Pre-trained Neural Networks on Large-scale Synthetic Datasets for Sound Event Localization and Detection
Sound event localization and detection (SELD) has seen substantial advancements through learning-based methods. These systems, typically trained from scratch on specific datasets, have shown considerable generalization capabilities. Recently, deep neural networks trained on large-scale datasets have achieved remarkable success in the sound event classification (SEC) field, prompting an open question of whether these advancements can be extended to develop general-purpose SELD models. In this paper, leveraging the power of pre-trained SEC models, we propose pre-trained SELD networks (PSELDNets) on large-scale synthetic datasets. These synthetic datasets, generated by convolving sound events with simulated spatial room impulse responses (SRIRs), contain 1,167 hours of audio clips with an ontology of 170 sound classes. These PSELDNets are transferred to downstream SELD tasks. When we adapt PSELDNets to specific scenarios, particularly in low-resource data cases, we introduce a data-efficient fine-tuning method, AdapterBit. PSELDNets are evaluated on a synthetic-test-set using collected SRIRs from TAU Spatial Room Impulse Response Database (TAU-SRIR DB) and achieve satisfactory performance. We also conduct our experiments to validate the transferability of PSELDNets to three publicly available datasets and our own collected audio recordings. Results demonstrate that PSELDNets surpass state-of-the-art systems across all publicly available datasets. Given the need for direction-of-arrival estimation, SELD generally relies on sufficient multi-channel audio clips. However, incorporating the AdapterBit, PSELDNets show more efficient adaptability to various tasks using minimal multi-channel or even just monophonic audio clips, outperforming the traditional fine-tuning approaches.

The Multilingual TEDx Corpus for Speech Recognition and Translation
We present the Multilingual TEDx corpus, built to support speech recognition (ASR) and speech translation (ST) research across many non-English source languages. The corpus is a collection of audio recordings from TEDx talks in 8 source languages. We segment transcripts into sentences and align them to the source-language audio and target-language translations. The corpus is released along with open-sourced code enabling extension to new talks and languages as they become available. Our corpus creation methodology can be applied to more languages than previous work, and creates multi-way parallel evaluation sets. We provide baselines in multiple ASR and ST settings, including multilingual models to improve translation performance for low-resource language pairs.

MEGConformer: Conformer-Based MEG Decoder for Robust Speech and Phoneme Classification
We present Conformer-based decoders for the LibriBrain 2025 PNPL competition, targeting two foundational MEG tasks: Speech Detection and Phoneme Classification. Our approach adapts a compact Conformer to raw 306-channel MEG signals, with a lightweight convolutional projection layer and task-specific heads. For Speech Detection, a MEG-oriented SpecAugment provided a first exploration of MEG-specific augmentation. For Phoneme Classification, we used inverse-square-root class weighting and a dynamic grouping loader to handle 100-sample averaged examples. In addition, a simple instance-level normalization proved critical to mitigate distribution shifts on the holdout split. Using the official Standard track splits and F1-macro for model selection, our best systems achieved 88.9% (Speech) and 65.8% (Phoneme) on the leaderboard, surpassing the competition baselines and ranking within the top-10 in both tasks. For further implementation details, the technical documentation, source code, and checkpoints are available at https://github.com/neural2speech/libribrain-experiments.

SonicSim: A customizable simulation platform for speech processing in moving sound source scenarios
The systematic evaluation of speech separation and enhancement models under moving sound source conditions typically requires extensive data comprising diverse scenarios. However, real-world datasets often contain insufficient data to meet the training and evaluation requirements of models. Although synthetic datasets offer a larger volume of data, their acoustic simulations lack realism. Consequently, neither real-world nor synthetic datasets effectively fulfill practical needs. To address these issues, we introduce SonicSim, a synthetic toolkit de-designed to generate highly customizable data for moving sound sources. SonicSim is developed based on the embodied AI simulation platform, Habitat-sim, supporting multi-level adjustments, including scene-level, microphone-level, and source-level, thereby generating more diverse synthetic data. Leveraging SonicSim, we constructed a moving sound source benchmark dataset, SonicSet, using the Librispeech, the Freesound Dataset 50k (FSD50K) and Free Music Archive (FMA), and 90 scenes from the Matterport3D to evaluate speech separation and enhancement models. Additionally, to validate the differences between synthetic data and real-world data, we randomly selected 5 hours of raw data without reverberation from the SonicSet validation set to record a real-world speech separation dataset, which was then compared with the corresponding synthetic datasets. Similarly, we utilized the real-world speech enhancement dataset RealMAN to validate the acoustic gap between other synthetic datasets and the SonicSet dataset for speech enhancement. The results indicate that the synthetic data generated by SonicSim can effectively generalize to real-world scenarios. Demo and code are publicly available at https://cslikai.cn/SonicSim/.

GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
We introduce GLM-4-Voice, an intelligent and human-like end-to-end spoken chatbot. It supports both Chinese and English, engages in real-time voice conversations, and varies vocal nuances such as emotion, intonation, speech rate, and dialect according to user instructions. GLM-4-Voice uses an ultra-low bitrate (175bps), single-codebook speech tokenizer with 12.5Hz frame rate derived from an automatic speech recognition (ASR) model by incorporating a vector-quantized bottleneck into the encoder. To efficiently transfer knowledge from text to speech modalities, we synthesize speech-text interleaved data from existing text pre-training corpora using a text-to-token model. We continue pre-training from the pre-trained text language model GLM-4-9B with a combination of unsupervised speech data, interleaved speech-text data, and supervised speech-text data, scaling up to 1 trillion tokens, achieving state-of-the-art performance in both speech language modeling and spoken question answering. We then fine-tune the pre-trained model with high-quality conversational speech data, achieving superior performance compared to existing baselines in both conversational ability and speech quality. The open models can be accessed through https://github.com/THUDM/GLM-4-Voice and https://huggingface.co/THUDM/glm-4-voice-9b.
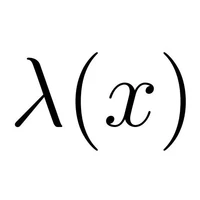

Libri-Light: A Benchmark for ASR with Limited or No Supervision
We introduce a new collection of spoken English audio suitable for training speech recognition systems under limited or no supervision. It is derived from open-source audio books from the LibriVox project. It contains over 60K hours of audio, which is, to our knowledge, the largest freely-available corpus of speech. The audio has been segmented using voice activity detection and is tagged with SNR, speaker ID and genre descriptions. Additionally, we provide baseline systems and evaluation metrics working under three settings: (1) the zero resource/unsupervised setting (ABX), (2) the semi-supervised setting (PER, CER) and (3) the distant supervision setting (WER). Settings (2) and (3) use limited textual resources (10 minutes to 10 hours) aligned with the speech. Setting (3) uses large amounts of unaligned text. They are evaluated on the standard LibriSpeech dev and test sets for comparison with the supervised state-of-the-art.


Microphone Conversion: Mitigating Device Variability in Sound Event Classification
In this study, we introduce a new augmentation technique to enhance the resilience of sound event classification (SEC) systems against device variability through the use of CycleGAN. We also present a unique dataset to evaluate this method. As SEC systems become increasingly common, it is crucial that they work well with audio from diverse recording devices. Our method addresses limited device diversity in training data by enabling unpaired training to transform input spectrograms as if they are recorded on a different device. Our experiments show that our approach outperforms existing methods in generalization by 5.2% - 11.5% in weighted f1 score. Additionally, it surpasses the current methods in adaptability across diverse recording devices by achieving a 6.5% - 12.8% improvement in weighted f1 score.

SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing
Motivated by the success of T5 (Text-To-Text Transfer Transformer) in pre-trained natural language processing models, we propose a unified-modal SpeechT5 framework that explores the encoder-decoder pre-training for self-supervised speech/text representation learning. The SpeechT5 framework consists of a shared encoder-decoder network and six modal-specific (speech/text) pre/post-nets. After preprocessing the input speech/text through the pre-nets, the shared encoder-decoder network models the sequence-to-sequence transformation, and then the post-nets generate the output in the speech/text modality based on the output of the decoder. Leveraging large-scale unlabeled speech and text data, we pre-train SpeechT5 to learn a unified-modal representation, hoping to improve the modeling capability for both speech and text. To align the textual and speech information into this unified semantic space, we propose a cross-modal vector quantization approach that randomly mixes up speech/text states with latent units as the interface between encoder and decoder. Extensive evaluations show the superiority of the proposed SpeechT5 framework on a wide variety of spoken language processing tasks, including automatic speech recognition, speech synthesis, speech translation, voice conversion, speech enhancement, and speaker identification. We release our code and model at https://github.com/microsoft/SpeechT5.
USC: An Open-Source Uzbek Speech Corpus and Initial Speech Recognition Experiments
We present a freely available speech corpus for the Uzbek language and report preliminary automatic speech recognition (ASR) results using both the deep neural network hidden Markov model (DNN-HMM) and end-to-end (E2E) architectures. The Uzbek speech corpus (USC) comprises 958 different speakers with a total of 105 hours of transcribed audio recordings. To the best of our knowledge, this is the first open-source Uzbek speech corpus dedicated to the ASR task. To ensure high quality, the USC has been manually checked by native speakers. We first describe the design and development procedures of the USC, and then explain the conducted ASR experiments in detail. The experimental results demonstrate promising results for the applicability of the USC for ASR. Specifically, 18.1% and 17.4% word error rates were achieved on the validation and test sets, respectively. To enable experiment reproducibility, we share the USC dataset, pre-trained models, and training recipes in our GitHub repository.

Generative Pre-trained Speech Language Model with Efficient Hierarchical Transformer
While recent advancements in speech language models have achieved significant progress, they face remarkable challenges in modeling the long acoustic sequences of neural audio codecs. In this paper, we introduce Generative Pre-trained Speech Transformer (GPST), a hierarchical transformer designed for efficient speech language modeling. GPST quantizes audio waveforms into two distinct types of discrete speech representations and integrates them within a hierarchical transformer architecture, allowing for a unified one-stage generation process and enhancing Hi-Res audio generation capabilities. By training on large corpora of speeches in an end-to-end unsupervised manner, GPST can generate syntactically consistent speech with diverse speaker identities. Given a brief 3-second prompt, GPST can produce natural and coherent personalized speech, demonstrating in-context learning abilities. Moreover, our approach can be easily extended to spoken cross-lingual speech generation by incorporating multi-lingual semantic tokens and universal acoustic tokens. Experimental results indicate that GPST significantly outperforms the existing speech language models in terms of word error rate, speech quality, and speaker similarity. See https://youngsheen.github.io/GPST/demo for demo samples.

BLAB: Brutally Long Audio Bench
Developing large audio language models (LMs) capable of understanding diverse spoken interactions is essential for accommodating the multimodal nature of human communication and can increase the accessibility of language technologies across different user populations. Recent work on audio LMs has primarily evaluated their performance on short audio segments, typically under 30 seconds, with limited exploration of long-form conversational speech segments that more closely reflect natural user interactions with these models. We introduce Brutally Long Audio Bench (BLAB), a challenging long-form audio benchmark that evaluates audio LMs on localization, duration estimation, emotion, and counting tasks using audio segments averaging 51 minutes in length. BLAB consists of 833+ hours of diverse, full-length audio clips, each paired with human-annotated, text-based natural language questions and answers. Our audio data were collected from permissively licensed sources and underwent a human-assisted filtering process to ensure task compliance. We evaluate six open-source and proprietary audio LMs on BLAB and find that all of them, including advanced models such as Gemini 2.0 Pro and GPT-4o, struggle with the tasks in BLAB. Our comprehensive analysis reveals key insights into the trade-offs between task difficulty and audio duration. In general, we find that audio LMs struggle with long-form speech, with performance declining as duration increases. They perform poorly on localization, temporal reasoning, counting, and struggle to understand non-phonemic information, relying more on prompts than audio content. BLAB serves as a challenging evaluation framework to develop audio LMs with robust long-form audio understanding capabilities.

EMMeTT: Efficient Multimodal Machine Translation Training
A rising interest in the modality extension of foundation language models warrants discussion on the most effective, and efficient, multimodal training approach. This work focuses on neural machine translation (NMT) and proposes a joint multimodal training regime of Speech-LLM to include automatic speech translation (AST). We investigate two different foundation model architectures, decoder-only GPT and encoder-decoder T5, extended with Canary-1B's speech encoder. To handle joint multimodal training, we propose a novel training framework called EMMeTT. EMMeTT improves training efficiency with the following: balanced sampling across languages, datasets, and modalities; efficient sequential data iteration; and a novel 2D bucketing scheme for multimodal data, complemented by a batch size optimizer (OOMptimizer). We show that a multimodal training consistently helps with both architectures. Moreover, SALM-T5 trained with EMMeTT retains the original NMT capability while outperforming AST baselines on four-language subsets of FLORES and FLEURS. The resultant Multimodal Translation Model produces strong text and speech translation results at the same time.
Harmonics to the Rescue: Why Voiced Speech is Not a Wss Process
Speech processing algorithms often rely on statistical knowledge of the underlying process. Despite many years of research, however, the debate on the most appropriate statistical model for speech still continues. Speech is commonly modeled as a wide-sense stationary (WSS) process. However, the use of the WSS model for spectrally correlated processes is fundamentally wrong, as WSS implies spectral uncorrelation. In this paper, we demonstrate that voiced speech can be more accurately represented as a cyclostationary (CS) process. By employing the CS rather than the WSS model for processes that are inherently correlated across frequency, it is possible to improve the estimation of cross-power spectral densities (PSDs), source separation, and beamforming. We illustrate how the correlation between harmonic frequencies of CS processes can enhance system identification, and validate our findings using both simulated and real speech data.

A systematic comparison of grapheme-based vs. phoneme-based label units for encoder-decoder-attention models
Following the rationale of end-to-end modeling, CTC, RNN-T or encoder-decoder-attention models for automatic speech recognition (ASR) use graphemes or grapheme-based subword units based on e.g. byte-pair encoding (BPE). The mapping from pronunciation to spelling is learned completely from data. In contrast to this, classical approaches to ASR employ secondary knowledge sources in the form of phoneme lists to define phonetic output labels and pronunciation lexica. In this work, we do a systematic comparison between grapheme- and phoneme-based output labels for an encoder-decoder-attention ASR model. We investigate the use of single phonemes as well as BPE-based phoneme groups as output labels of our model. To preserve a simplified and efficient decoder design, we also extend the phoneme set by auxiliary units to be able to distinguish homophones. Experiments performed on the Switchboard 300h and LibriSpeech benchmarks show that phoneme-based modeling is competitive to grapheme-based encoder-decoder-attention modeling.
Tiny Transformers for Environmental Sound Classification at the Edge
With the growth of the Internet of Things and the rise of Big Data, data processing and machine learning applications are being moved to cheap and low size, weight, and power (SWaP) devices at the edge, often in the form of mobile phones, embedded systems, or microcontrollers. The field of Cyber-Physical Measurements and Signature Intelligence (MASINT) makes use of these devices to analyze and exploit data in ways not otherwise possible, which results in increased data quality, increased security, and decreased bandwidth. However, methods to train and deploy models at the edge are limited, and models with sufficient accuracy are often too large for the edge device. Therefore, there is a clear need for techniques to create efficient AI/ML at the edge. This work presents training techniques for audio models in the field of environmental sound classification at the edge. Specifically, we design and train Transformers to classify office sounds in audio clips. Results show that a BERT-based Transformer, trained on Mel spectrograms, can outperform a CNN using 99.85% fewer parameters. To achieve this result, we first tested several audio feature extraction techniques designed for Transformers, using ESC-50 for evaluation, along with various augmentations. Our final model outperforms the state-of-the-art MFCC-based CNN on the office sounds dataset, using just over 6,000 parameters -- small enough to run on a microcontroller.
PITCH: AI-assisted Tagging of Deepfake Audio Calls using Challenge-Response
The rise of AI voice-cloning technology, particularly audio Real-time Deepfakes (RTDFs), has intensified social engineering attacks by enabling real-time voice impersonation that bypasses conventional enrollment-based authentication. To address this, we propose PITCH, a robust challenge-response method to detect and tag interactive deepfake audio calls. We developed a comprehensive taxonomy of audio challenges based on the human auditory system, linguistics, and environmental factors, yielding 20 prospective challenges. These were tested against leading voice-cloning systems using a novel dataset comprising 18,600 original and 1.6 million deepfake samples from 100 users. PITCH's prospective challenges enhanced machine detection capabilities to 88.7% AUROC score on the full unbalanced dataset, enabling us to shortlist 10 functional challenges that balance security and usability. For human evaluation and subsequent analyses, we filtered a challenging, balanced subset. On this subset, human evaluators independently scored 72.6% accuracy, while machines achieved 87.7%. Acknowledging that call environments require higher human control, we aided call receivers in making decisions with them using machines. Our solution uses an early warning system to tag suspicious incoming calls as "Deepfake-likely." Contrary to prior findings, we discovered that integrating human intuition with machine precision offers complementary advantages. Our solution gave users maximum control and boosted detection accuracy to 84.5%. Evidenced by this jump in accuracy, PITCH demonstrated the potential for AI-assisted pre-screening in call verification processes, offering an adaptable and usable approach to combat real-time voice-cloning attacks. Code to reproduce and access data at https://github.com/mittalgovind/PITCH-Deepfakes.


Scaling Speech-Text Pre-training with Synthetic Interleaved Data
Speech language models (SpeechLMs) accept speech input and produce speech output, allowing for more natural human-computer interaction compared to text-based large language models (LLMs). Traditional approaches for developing SpeechLMs are constrained by the limited availability of unsupervised speech data and parallel speech-text data, which are significantly less abundant than text pre-training data, thereby limiting their scalability as LLMs. We propose a novel approach to scaling speech-text pre-training by leveraging large-scale synthetic interleaved data derived from text corpora, eliminating the need for parallel speech-text datasets. Our method efficiently constructs speech-text interleaved data by sampling text spans from existing text corpora and synthesizing corresponding speech spans using a text-to-token model, bypassing the need to generate actual speech. We also employ a supervised speech tokenizer derived from an automatic speech recognition (ASR) model by incorporating a vector-quantized bottleneck into the encoder. This supervised training approach results in discrete speech tokens with strong semantic preservation even at lower sampling rates (e.g. 12.5Hz), while still maintaining speech reconstruction quality. Starting from a pre-trained language model and scaling our pre-training to 1 trillion tokens (with 600B synthetic interleaved speech-text data), we achieve state-of-the-art performance in speech language modeling and spoken question answering, improving performance on spoken questions tasks from the previous SOTA of 13% (Moshi) to 31%. We further demonstrate that by fine-tuning the pre-trained model with speech dialogue data, we can develop an end-to-end spoken chatbot that achieves competitive performance comparable to existing baselines in both conversational abilities and speech quality, even operating exclusively in the speech domain.
Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
This paper describes Tacotron 2, a neural network architecture for speech synthesis directly from text. The system is composed of a recurrent sequence-to-sequence feature prediction network that maps character embeddings to mel-scale spectrograms, followed by a modified WaveNet model acting as a vocoder to synthesize timedomain waveforms from those spectrograms. Our model achieves a mean opinion score (MOS) of 4.53 comparable to a MOS of 4.58 for professionally recorded speech. To validate our design choices, we present ablation studies of key components of our system and evaluate the impact of using mel spectrograms as the input to WaveNet instead of linguistic, duration, and F_0 features. We further demonstrate that using a compact acoustic intermediate representation enables significant simplification of the WaveNet architecture.
ChildMandarin: A Comprehensive Mandarin Speech Dataset for Young Children Aged 3-5
Automatic speech recognition (ASR) systems have advanced significantly with models like Whisper, Conformer, and self-supervised frameworks such as Wav2vec 2.0 and HuBERT. However, developing robust ASR models for young children's speech remains challenging due to differences in pronunciation, tone, and pace compared to adult speech. In this paper, we introduce a new Mandarin speech dataset focused on children aged 3 to 5, addressing the scarcity of resources in this area. The dataset comprises 41.25 hours of speech with carefully crafted manual transcriptions, collected from 397 speakers across various provinces in China, with balanced gender representation. We provide a comprehensive analysis of speaker demographics, speech duration distribution and geographic coverage. Additionally, we evaluate ASR performance on models trained from scratch, such as Conformer, as well as fine-tuned pre-trained models like HuBERT and Whisper, where fine-tuning demonstrates significant performance improvements. Furthermore, we assess speaker verification (SV) on our dataset, showing that, despite the challenges posed by the unique vocal characteristics of young children, the dataset effectively supports both ASR and SV tasks. This dataset is a valuable contribution to Mandarin child speech research and holds potential for applications in educational technology and child-computer interaction. It will be open-source and freely available for all academic purposes.

WaveSP-Net: Learnable Wavelet-Domain Sparse Prompt Tuning for Speech Deepfake Detection
Modern front-end design for speech deepfake detection relies on full fine-tuning of large pre-trained models like XLSR. However, this approach is not parameter-efficient and may lead to suboptimal generalization to realistic, in-the-wild data types. To address these limitations, we introduce a new family of parameter-efficient front-ends that fuse prompt-tuning with classical signal processing transforms. These include FourierPT-XLSR, which uses the Fourier Transform, and two variants based on the Wavelet Transform: WSPT-XLSR and Partial-WSPT-XLSR. We further propose WaveSP-Net, a novel architecture combining a Partial-WSPT-XLSR front-end and a bidirectional Mamba-based back-end. This design injects multi-resolution features into the prompt embeddings, which enhances the localization of subtle synthetic artifacts without altering the frozen XLSR parameters. Experimental results demonstrate that WaveSP-Net outperforms several state-of-the-art models on two new and challenging benchmarks, Deepfake-Eval-2024 and SpoofCeleb, with low trainable parameters and notable performance gains. The code and models are available at https://github.com/xxuan-acoustics/WaveSP-Net.

A Dataset of Dynamic Reverberant Sound Scenes with Directional Interferers for Sound Event Localization and Detection
This report presents the dataset and baseline of Task 3 of the DCASE2021 Challenge on Sound Event Localization and Detection (SELD). The dataset is based on emulation of real recordings of static or moving sound events under real conditions of reverberation and ambient noise, using spatial room impulse responses captured in a variety of rooms and delivered in two spatial formats. The acoustical synthesis remains the same as in the previous iteration of the challenge, however the new dataset brings more challenging conditions of polyphony and overlapping instances of the same class. The most important difference of the new dataset is the introduction of directional interferers, meaning sound events that are localized in space but do not belong to the target classes to be detected and are not annotated. Since such interfering events are expected in every real-world scenario of SELD, the new dataset aims to promote systems that deal with this condition effectively. A modified SELDnet baseline employing the recent ACCDOA representation of SELD problems accompanies the dataset and it is shown to outperform the previous one. The new dataset is shown to be significantly more challenging for both baselines according to all considered metrics. To investigate the individual and combined effects of ambient noise, interferers, and reverberation, we study the performance of the baseline on different versions of the dataset excluding or including combinations of these factors. The results indicate that by far the most detrimental effects are caused by directional interferers.
ByT5 model for massively multilingual grapheme-to-phoneme conversion
In this study, we tackle massively multilingual grapheme-to-phoneme conversion through implementing G2P models based on ByT5. We have curated a G2P dataset from various sources that covers around 100 languages and trained large-scale multilingual G2P models based on ByT5. We found that ByT5 operating on byte-level inputs significantly outperformed the token-based mT5 model in terms of multilingual G2P. Pairwise comparison with monolingual models in these languages suggests that multilingual ByT5 models generally lower the phone error rate by jointly learning from a variety of languages. The pretrained model can further benefit low resource G2P through zero-shot prediction on unseen languages or provides pretrained weights for finetuning, which helps the model converge to a lower phone error rate than randomly initialized weights. To facilitate future research on multilingual G2P, we make available our code and pretrained multilingual G2P models at: https://github.com/lingjzhu/CharsiuG2P.


CryCeleb: A Speaker Verification Dataset Based on Infant Cry Sounds
This paper describes the Ubenwa CryCeleb dataset - a labeled collection of infant cries - and the accompanying CryCeleb 2023 task, which is a public speaker verification challenge based on cry sounds. We released more than 6 hours of manually segmented cry sounds from 786 newborns for academic use, aiming to encourage research in infant cry analysis. The inaugural public competition attracted 59 participants, 11 of whom improved the baseline performance. The top-performing system achieved a significant improvement scoring 25.8% equal error rate, which is still far from the performance of state-of-the-art adult speaker verification systems. Therefore, we believe there is room for further research on this dataset, potentially extending beyond the verification task.
STARSS22: A dataset of spatial recordings of real scenes with spatiotemporal annotations of sound events
This report presents the Sony-TAu Realistic Spatial Soundscapes 2022 (STARS22) dataset for sound event localization and detection, comprised of spatial recordings of real scenes collected in various interiors of two different sites. The dataset is captured with a high resolution spherical microphone array and delivered in two 4-channel formats, first-order Ambisonics and tetrahedral microphone array. Sound events in the dataset belonging to 13 target sound classes are annotated both temporally and spatially through a combination of human annotation and optical tracking. The dataset serves as the development and evaluation dataset for the Task 3 of the DCASE2022 Challenge on Sound Event Localization and Detection and introduces significant new challenges for the task compared to the previous iterations, which were based on synthetic spatialized sound scene recordings. Dataset specifications are detailed including recording and annotation process, target classes and their presence, and details on the development and evaluation splits. Additionally, the report presents the baseline system that accompanies the dataset in the challenge with emphasis on the differences with the baseline of the previous iterations; namely, introduction of the multi-ACCDOA representation to handle multiple simultaneous occurences of events of the same class, and support for additional improved input features for the microphone array format. Results of the baseline indicate that with a suitable training strategy a reasonable detection and localization performance can be achieved on real sound scene recordings. The dataset is available in https://zenodo.org/record/6387880.
Whisper-GPT: A Hybrid Representation Audio Large Language Model
We propose WHISPER-GPT: A generative large language model (LLM) for speech and music that allows us to work with continuous audio representations and discrete tokens simultaneously as part of a single architecture. There has been a huge surge in generative audio, speech, and music models that utilize discrete audio tokens derived from neural compression algorithms, e.g. ENCODEC. However, one of the major drawbacks of this approach is handling the context length. It blows up for high-fidelity generative architecture if one has to account for all the audio contents at various frequencies for the next token prediction. By combining continuous audio representation like the spectrogram and discrete acoustic tokens, we retain the best of both worlds: Have all the information needed from the audio at a specific time instance in a single token, yet allow LLM to predict the future token to allow for sampling and other benefits discrete space provides. We show how our architecture improves the perplexity and negative log-likelihood scores for the next token prediction compared to a token-based LLM for speech and music.

Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities
Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.

AudioCLIP: Extending CLIP to Image, Text and Audio
In the past, the rapidly evolving field of sound classification greatly benefited from the application of methods from other domains. Today, we observe the trend to fuse domain-specific tasks and approaches together, which provides the community with new outstanding models. In this work, we present an extension of the CLIP model that handles audio in addition to text and images. Our proposed model incorporates the ESResNeXt audio-model into the CLIP framework using the AudioSet dataset. Such a combination enables the proposed model to perform bimodal and unimodal classification and querying, while keeping CLIP's ability to generalize to unseen datasets in a zero-shot inference fashion. AudioCLIP achieves new state-of-the-art results in the Environmental Sound Classification (ESC) task, out-performing other approaches by reaching accuracies of 90.07% on the UrbanSound8K and 97.15% on the ESC-50 datasets. Further it sets new baselines in the zero-shot ESC-task on the same datasets (68.78% and 69.40%, respectively). Finally, we also assess the cross-modal querying performance of the proposed model as well as the influence of full and partial training on the results. For the sake of reproducibility, our code is published.
Multi-Domain Audio Question Answering Toward Acoustic Content Reasoning in The DCASE 2025 Challenge
We present Task 5 of the DCASE 2025 Challenge: an Audio Question Answering (AQA) benchmark spanning multiple domains of sound understanding. This task defines three QA subsets (Bioacoustics, Temporal Soundscapes, and Complex QA) to test audio-language models on interactive question-answering over diverse acoustic scenes. We describe the dataset composition (from marine mammal calls to soundscapes and complex real-world clips), the evaluation protocol (top-1 accuracy with answer-shuffling robustness), and baseline systems (Qwen2-Audio-7B, AudioFlamingo 2, Gemini-2-Flash). Preliminary results on the development set are compared, showing strong variation across models and subsets. This challenge aims to advance the audio understanding and reasoning capabilities of audio-language models toward human-level acuity, which are crucial for enabling AI agents to perceive and interact about the world effectively.




USE: A Unified Model for Universal Sound Separation and Extraction
Sound separation (SS) and target sound extraction (TSE) are fundamental techniques for addressing complex acoustic scenarios. While existing SS methods struggle with determining the unknown number of sound sources, TSE approaches require precisely specified clues to achieve optimal performance. This paper proposes a unified framework that synergistically combines SS and TSE to overcome their individual limitations. Our architecture employs two complementary components: 1) An Encoder-Decoder Attractor (EDA) network that automatically infers both the source count and corresponding acoustic clues for SS, and 2) A multi-modal fusion network that precisely interprets diverse user-provided clues (acoustic, semantic, or visual) for TSE. Through joint training with cross-task consistency constraints, we establish a unified latent space that bridges both paradigms. During inference, the system adaptively operates in either fully autonomous SS mode or clue-driven TSE mode. Experiments demonstrate remarkable performance in both tasks, with notable improvements of 1.4 dB SDR improvement in SS compared to baseline and 86\% TSE accuracy.
Tokenizing Single-Channel EEG with Time-Frequency Motif Learning
Foundation models are reshaping EEG analysis, yet an important problem of EEG tokenization remains a challenge. This paper presents TFM-Tokenizer, a novel tokenization framework that learns a vocabulary of time-frequency motifs from single-channel EEG signals and encodes them into discrete tokens. We propose a dual-path architecture with time-frequency masking to capture robust motif representations, and it is model-agnostic, supporting both lightweight transformers and existing foundation models for downstream tasks. Our study demonstrates three key benefits: Accuracy: Experiments on four diverse EEG benchmarks demonstrate consistent performance gains across both single- and multi-dataset pretraining settings, achieving up to 17% improvement in Cohen's Kappa over strong baselines. Generalization: Moreover, as a plug-and-play component, it consistently boosts the performance of diverse foundation models, including BIOT and LaBraM. Scalability: By operating at the single-channel level rather than relying on the strict 10-20 EEG system, our method has the potential to be device-agnostic. Experiments on ear-EEG sleep staging, which differs from the pretraining data in signal format, channel configuration, recording device, and task, show that our tokenizer outperforms baselines by 14%. A comprehensive token analysis reveals strong class-discriminative, frequency-aware, and consistent structure, enabling improved representation quality and interpretability. Code is available at https://github.com/Jathurshan0330/TFM-Tokenizer.

Synthetic Voice Data for Automatic Speech Recognition in African Languages
Speech technology remains out of reach for most of the over 2300 languages in Africa. We present the first systematic assessment of large-scale synthetic voice corpora for African ASR. We apply a three-step process: LLM-driven text creation, TTS voice synthesis, and ASR fine-tuning. Eight out of ten languages for which we create synthetic text achieved readability scores above 5 out of 7. We evaluated ASR improvement for three (Hausa, Dholuo, Chichewa) and created more than 2,500 hours of synthetic voice data at below 1% of the cost of real data. Fine-tuned Wav2Vec-BERT-2.0 models trained on 250h real and 250h synthetic Hausa matched a 500h real-data-only baseline, while 579h real and 450h to 993h synthetic data created the best performance. We also present gender-disaggregated ASR performance evaluation. For very low-resource languages, gains varied: Chichewa WER improved about 6.5% relative with a 1:2 real-to-synthetic ratio; a 1:1 ratio for Dholuo showed similar improvements on some evaluation data, but not on others. Investigating intercoder reliability, ASR errors and evaluation datasets revealed the need for more robust reviewer protocols and more accurate evaluation data. All data and models are publicly released to invite further work to improve synthetic data for African languages.

Evaluation of Deep Audio Representations for Hearables
Effectively steering hearable devices requires understanding the acoustic environment around the user. In the computational analysis of sound scenes, foundation models have emerged as the state of the art to produce high-performance, robust, multi-purpose audio representations. We introduce and release Deep Evaluation of Audio Representations (DEAR), the first dataset and benchmark to evaluate the efficacy of foundation models in capturing essential acoustic properties for hearables. The dataset includes 1,158 audio tracks, each 30 seconds long, created by spatially mixing proprietary monologues with commercial, high-quality recordings of everyday acoustic scenes. Our benchmark encompasses eight tasks that assess the general context, speech sources, and technical acoustic properties of the audio scenes. Through our evaluation of four general-purpose audio representation models, we demonstrate that the BEATs model significantly surpasses its counterparts. This superiority underscores the advantage of models trained on diverse audio collections, confirming their applicability to a wide array of auditory tasks, including encoding the environment properties necessary for hearable steering. The DEAR dataset and associated code are available at https://dear-dataset.github.io.


Acoustic To Articulatory Speech Inversion Using Multi-Resolution Spectro-Temporal Representations Of Speech Signals
Multi-resolution spectro-temporal features of a speech signal represent how the brain perceives sounds by tuning cortical cells to different spectral and temporal modulations. These features produce a higher dimensional representation of the speech signals. The purpose of this paper is to evaluate how well the auditory cortex representation of speech signals contribute to estimate articulatory features of those corresponding signals. Since obtaining articulatory features from acoustic features of speech signals has been a challenging topic of interest for different speech communities, we investigate the possibility of using this multi-resolution representation of speech signals as acoustic features. We used U. of Wisconsin X-ray Microbeam (XRMB) database of clean speech signals to train a feed-forward deep neural network (DNN) to estimate articulatory trajectories of six tract variables. The optimal set of multi-resolution spectro-temporal features to train the model were chosen using appropriate scale and rate vector parameters to obtain the best performing model. Experiments achieved a correlation of 0.675 with ground-truth tract variables. We compared the performance of this speech inversion system with prior experiments conducted using Mel Frequency Cepstral Coefficients (MFCCs).

F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
This paper introduces F5-TTS, a fully non-autoregressive text-to-speech system based on flow matching with Diffusion Transformer (DiT). Without requiring complex designs such as duration model, text encoder, and phoneme alignment, the text input is simply padded with filler tokens to the same length as input speech, and then the denoising is performed for speech generation, which was originally proved feasible by E2 TTS. However, the original design of E2 TTS makes it hard to follow due to its slow convergence and low robustness. To address these issues, we first model the input with ConvNeXt to refine the text representation, making it easy to align with the speech. We further propose an inference-time Sway Sampling strategy, which significantly improves our model's performance and efficiency. This sampling strategy for flow step can be easily applied to existing flow matching based models without retraining. Our design allows faster training and achieves an inference RTF of 0.15, which is greatly improved compared to state-of-the-art diffusion-based TTS models. Trained on a public 100K hours multilingual dataset, our Fairytaler Fakes Fluent and Faithful speech with Flow matching (F5-TTS) exhibits highly natural and expressive zero-shot ability, seamless code-switching capability, and speed control efficiency. Demo samples can be found at https://SWivid.github.io/F5-TTS. We release all code and checkpoints to promote community development.




WenetSpeech4TTS: A 12,800-hour Mandarin TTS Corpus for Large Speech Generation Model Benchmark
With the development of large text-to-speech (TTS) models and scale-up of the training data, state-of-the-art TTS systems have achieved impressive performance. In this paper, we present WenetSpeech4TTS, a multi-domain Mandarin corpus derived from the open-sourced WenetSpeech dataset. Tailored for the text-to-speech tasks, we refined WenetSpeech by adjusting segment boundaries, enhancing the audio quality, and eliminating speaker mixing within each segment. Following a more accurate transcription process and quality-based data filtering process, the obtained WenetSpeech4TTS corpus contains 12,800 hours of paired audio-text data. Furthermore, we have created subsets of varying sizes, categorized by segment quality scores to allow for TTS model training and fine-tuning. VALL-E and NaturalSpeech 2 systems are trained and fine-tuned on these subsets to validate the usability of WenetSpeech4TTS, establishing baselines on benchmark for fair comparison of TTS systems. The corpus and corresponding benchmarks are publicly available on huggingface.
FlexSED: Towards Open-Vocabulary Sound Event Detection
Despite recent progress in large-scale sound event detection (SED) systems capable of handling hundreds of sound classes, existing multi-class classification frameworks remain fundamentally limited. They cannot process free-text sound queries, which enable more flexible and user-friendly interaction, and they lack zero-shot capabilities and offer poor few-shot adaptability. Although text-query-based separation methods have been explored, they primarily focus on source separation and are ill-suited for SED tasks that require precise temporal localization and efficient detection across large and diverse sound vocabularies. In this paper, we propose FlexSED, an open-vocabulary sound event detection system. FlexSED builds on a pretrained audio SSL model and the CLAP text encoder, introducing an encoder-decoder composition and an adaptive fusion strategy to enable effective continuous training from pretrained weights. To ensure robust supervision, it also employs large language models (LLMs) to assist in event query selection during training, addressing challenges related to missing labels. As a result, FlexSED achieves superior performance compared to vanilla SED models on AudioSet-Strong, while demonstrating strong zero-shot and few-shot capabilities. We release the code and pretrained models to support future research and applications based on FlexSED.
GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.


Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Exploring SSL Discrete Speech Features for Zipformer-based Contextual ASR
Self-supervised learning (SSL) based discrete speech representations are highly compact and domain adaptable. In this paper, SSL discrete speech features extracted from WavLM models are used as additional cross-utterance acoustic context features in Zipformer-Transducer ASR systems. The efficacy of replacing Fbank features with discrete token features for modelling either cross-utterance contexts (from preceding and future segments), or current utterance's internal contexts alone, or both at the same time, are demonstrated thoroughly on the Gigaspeech 1000-hr corpus. The best Zipformer-Transducer system using discrete tokens based cross-utterance context features outperforms the baseline using utterance internal context only with statistically significant word error rate (WER) reductions of 0.32% to 0.41% absolute (2.78% to 3.54% relative) on the dev and test data. The lowest published WER of 11.15% and 11.14% were obtained on the dev and test sets. Our work is open-source and publicly available at https://github.com/open-creator/icefall/tree/master/egs/gigaspeech/Context\_ASR.

NIST SRE CTS Superset: A large-scale dataset for telephony speaker recognition
This document provides a brief description of the National Institute of Standards and Technology (NIST) speaker recognition evaluation (SRE) conversational telephone speech (CTS) Superset. The CTS Superset has been created in an attempt to provide the research community with a large-scale dataset along with uniform metadata that can be used to effectively train and develop telephony (narrowband) speaker recognition systems. It contains a large number of telephony speech segments from more than 6800 speakers with speech durations distributed uniformly in the [10s, 60s] range. The segments have been extracted from the source corpora used to compile prior SRE datasets (SRE1996-2012), including the Greybeard corpus as well as the Switchboard and Mixer series collected by the Linguistic Data Consortium (LDC). In addition to the brief description, we also report speaker recognition results on the NIST 2020 CTS Speaker Recognition Challenge, obtained using a system trained with the CTS Superset. The results will serve as a reference baseline for the challenge.
Keyword spotting -- Detecting commands in speech using deep learning
Speech recognition has become an important task in the development of machine learning and artificial intelligence. In this study, we explore the important task of keyword spotting using speech recognition machine learning and deep learning techniques. We implement feature engineering by converting raw waveforms to Mel Frequency Cepstral Coefficients (MFCCs), which we use as inputs to our models. We experiment with several different algorithms such as Hidden Markov Model with Gaussian Mixture, Convolutional Neural Networks and variants of Recurrent Neural Networks including Long Short-Term Memory and the Attention mechanism. In our experiments, RNN with BiLSTM and Attention achieves the best performance with an accuracy of 93.9 %
Cross-Lingual F5-TTS: Towards Language-Agnostic Voice Cloning and Speech Synthesis
Flow-matching-based text-to-speech (TTS) models have shown high-quality speech synthesis. However, most current flow-matching-based TTS models still rely on reference transcripts corresponding to the audio prompt for synthesis. This dependency prevents cross-lingual voice cloning when audio prompt transcripts are unavailable, particularly for unseen languages. The key challenges for flow-matching-based TTS models to remove audio prompt transcripts are identifying word boundaries during training and determining appropriate duration during inference. In this paper, we introduce Cross-Lingual F5-TTS, a framework that enables cross-lingual voice cloning without audio prompt transcripts. Our method preprocesses audio prompts by forced alignment to obtain word boundaries, enabling direct synthesis from audio prompts while excluding transcripts during training. To address the duration modeling challenge, we train speaking rate predictors at different linguistic granularities to derive duration from speaker pace. Experiments show that our approach matches the performance of F5-TTS while enabling cross-lingual voice cloning.
Making Acoustic Side-Channel Attacks on Noisy Keyboards Viable with LLM-Assisted Spectrograms' "Typo" Correction
The large integration of microphones into devices increases the opportunities for Acoustic Side-Channel Attacks (ASCAs), as these can be used to capture keystrokes' audio signals that might reveal sensitive information. However, the current State-Of-The-Art (SOTA) models for ASCAs, including Convolutional Neural Networks (CNNs) and hybrid models, such as CoAtNet, still exhibit limited robustness under realistic noisy conditions. Solving this problem requires either: (i) an increased model's capacity to infer contextual information from longer sequences, allowing the model to learn that an initially noisily typed word is the same as a futurely collected non-noisy word, or (ii) an approach to fix misidentified information from the contexts, as one does not type random words, but the ones that best fit the conversation context. In this paper, we demonstrate that both strategies are viable and complementary solutions for making ASCAs practical. We observed that no existing solution leverages advanced transformer architectures' power for these tasks and propose that: (i) Visual Transformers (VTs) are the candidate solutions for capturing long-term contextual information and (ii) transformer-powered Large Language Models (LLMs) are the candidate solutions to fix the ``typos'' (mispredictions) the model might make. Thus, we here present the first-of-its-kind approach that integrates VTs and LLMs for ASCAs. We first show that VTs achieve SOTA performance in classifying keystrokes when compared to the previous CNN benchmark. Second, we demonstrate that LLMs can mitigate the impact of real-world noise. Evaluations on the natural sentences revealed that: (i) incorporating LLMs (e.g., GPT-4o) in our ASCA pipeline boosts the performance of error-correction tasks; and (ii) the comparable performance can be attained by a lightweight, fine-tuned smaller LLM (67 times smaller than GPT-4o), using...

A Robust framework for sound event localization and detection on real recordings
This technical report describes the systems submitted to the DCASE2022 challenge task 3: sound event localization and detection (SELD). The task aims to detect occurrences of sound events and specify their class, furthermore estimate their position. Our system utilizes a ResNet-based model under a proposed robust framework for SELD. To guarantee the generalized performance on the real-world sound scenes, we design the total framework with augmentation techniques, a pipeline of mixing datasets from real-world sound scenes and emulations, and test time augmentation. Augmentation techniques and exploitation of external sound sources enable training diverse samples and keeping the opportunity to train the real-world context enough by maintaining the number of the real recording samples in the batch. In addition, we design a test time augmentation and a clustering-based model ensemble method to aggregate confident predictions. Experimental results show that the model under a proposed framework outperforms the baseline methods and achieves competitive performance in real-world sound recordings.

SwiftF0: Fast and Accurate Monophonic Pitch Detection
Accurate and real-time monophonic pitch estimation in noisy conditions, particularly on resource-constrained devices, remains an open challenge in audio processing. We present SwiftF0, a novel, lightweight neural model that sets a new state-of-the-art for monophonic pitch estimation. Through training on diverse speech, music, and synthetic datasets with extensive data augmentation, SwiftF0 achieves robust generalization across acoustic domains while maintaining computational efficiency. SwiftF0 achieves a 91.80\% harmonic mean (HM) at 10 dB SNR, outperforming baselines like CREPE by over 12 percentage points and degrading by only 2.3 points from clean audio. SwiftF0 requires only 95,842 parameters and runs approximately 42x faster than CREPE on CPU, making it ideal for efficient, real-time deployment. To address the critical lack of perfectly accurate ground truth pitch in speech corpora (which typically rely on algorithmic estimators or laryngograph signals), we introduce SpeechSynth. This synthetic speech dataset, generated by a phoneme-level TTS model, provides exact, on-demand ground-truth pitch curves, enabling more robust model training and evaluation. Furthermore, we propose a unified metric, combining six complementary performance measures for comprehensive and reliable pitch evaluation, and release an open-source pitch benchmark suite. A live demo of SwiftF0 is available at https://swift-f0.github.io/, the source code at https://github.com/lars76/swift-f0, and the benchmark framework at https://github.com/lars76/pitch-benchmark.

Did You Hear That? Introducing AADG: A Framework for Generating Benchmark Data in Audio Anomaly Detection
We introduce a novel, general-purpose audio generation framework specifically designed for anomaly detection and localization. Unlike existing datasets that predominantly focus on industrial and machine-related sounds, our framework focuses a broader range of environments, particularly useful in real-world scenarios where only audio data are available, such as in video-derived or telephonic audio. To generate such data, we propose a new method inspired by the LLM-Modulo framework, which leverages large language models(LLMs) as world models to simulate such real-world scenarios. This tool is modular allowing a plug-and-play approach. It operates by first using LLMs to predict plausible real-world scenarios. An LLM further extracts the constituent sounds, the order and the way in which these should be merged to create coherent wholes. Much like the LLM-Modulo framework, we include rigorous verification of each output stage, ensuring the reliability of the generated data. The data produced using the framework serves as a benchmark for anomaly detection applications, potentially enhancing the performance of models trained on audio data, particularly in handling out-of-distribution cases. Our contributions thus fill a critical void in audio anomaly detection resources and provide a scalable tool for generating diverse, realistic audio data.

WeNet: Production oriented Streaming and Non-streaming End-to-End Speech Recognition Toolkit
In this paper, we propose an open source, production first, and production ready speech recognition toolkit called WeNet in which a new two-pass approach is implemented to unify streaming and non-streaming end-to-end (E2E) speech recognition in a single model. The main motivation of WeNet is to close the gap between the research and the production of E2E speechrecognition models. WeNet provides an efficient way to ship ASR applications in several real-world scenarios, which is the main difference and advantage to other open source E2E speech recognition toolkits. In our toolkit, a new two-pass method is implemented. Our method propose a dynamic chunk-based attention strategy of the the transformer layers to allow arbitrary right context length modifies in hybrid CTC/attention architecture. The inference latency could be easily controlled by only changing the chunk size. The CTC hypotheses are then rescored by the attention decoder to get the final result. Our experiments on the AISHELL-1 dataset using WeNet show that, our model achieves 5.03\% relative character error rate (CER) reduction in non-streaming ASR compared to a standard non-streaming transformer. After model quantification, our model perform reasonable RTF and latency.
CST5: Data Augmentation for Code-Switched Semantic Parsing
Extending semantic parsers to code-switched input has been a challenging problem, primarily due to a lack of supervised training data. In this work, we introduce CST5, a new data augmentation technique that finetunes a T5 model using a small seed set (approx100 utterances) to generate code-switched utterances from English utterances. We show that CST5 generates high quality code-switched data, both intrinsically (per human evaluation) and extrinsically by comparing baseline models which are trained without data augmentation to models which are trained with augmented data. Empirically we observe that using CST5, one can achieve the same semantic parsing performance by using up to 20x less labeled data. To aid further research in this area, we are also releasing (a) Hinglish-TOP, the largest human annotated code-switched semantic parsing dataset to date, containing 10k human annotated Hindi-English (Hinglish) code-switched utterances, and (b) Over 170K CST5 generated code-switched utterances from the TOPv2 dataset. Human evaluation shows that both the human annotated data as well as the CST5 generated data is of good quality.
JaCappella Corpus: A Japanese a Cappella Vocal Ensemble Corpus
We construct a corpus of Japanese a cappella vocal ensembles (jaCappella corpus) for vocal ensemble separation and synthesis. It consists of 35 copyright-cleared vocal ensemble songs and their audio recordings of individual voice parts. These songs were arranged from out-of-copyright Japanese children's songs and have six voice parts (lead vocal, soprano, alto, tenor, bass, and vocal percussion). They are divided into seven subsets, each of which features typical characteristics of a music genre such as jazz and enka. The variety in genre and voice part match vocal ensembles recently widespread in social media services such as YouTube, although the main targets of conventional vocal ensemble datasets are choral singing made up of soprano, alto, tenor, and bass. Experimental evaluation demonstrates that our corpus is a challenging resource for vocal ensemble separation. Our corpus is available on our project page (https://tomohikonakamura.github.io/jaCappella_corpus/).
Exploring WavLM Back-ends for Speech Spoofing and Deepfake Detection
This paper describes our submitted systems to the ASVspoof 5 Challenge Track 1: Speech Deepfake Detection - Open Condition, which consists of a stand-alone speech deepfake (bonafide vs spoof) detection task. Recently, large-scale self-supervised models become a standard in Automatic Speech Recognition (ASR) and other speech processing tasks. Thus, we leverage a pre-trained WavLM as a front-end model and pool its representations with different back-end techniques. The complete framework is fine-tuned using only the trained dataset of the challenge, similar to the close condition. Besides, we adopt data-augmentation by adding noise and reverberation using MUSAN noise and RIR datasets. We also experiment with codec augmentations to increase the performance of our method. Ultimately, we use the Bosaris toolkit for score calibration and system fusion to get better Cllr scores. Our fused system achieves 0.0937 minDCF, 3.42% EER, 0.1927 Cllr, and 0.1375 actDCF.


FunCodec: A Fundamental, Reproducible and Integrable Open-source Toolkit for Neural Speech Codec
This paper presents FunCodec, a fundamental neural speech codec toolkit, which is an extension of the open-source speech processing toolkit FunASR. FunCodec provides reproducible training recipes and inference scripts for the latest neural speech codec models, such as SoundStream and Encodec. Thanks to the unified design with FunASR, FunCodec can be easily integrated into downstream tasks, such as speech recognition. Along with FunCodec, pre-trained models are also provided, which can be used for academic or generalized purposes. Based on the toolkit, we further propose the frequency-domain codec models, FreqCodec, which can achieve comparable speech quality with much lower computation and parameter complexity. Experimental results show that, under the same compression ratio, FunCodec can achieve better reconstruction quality compared with other toolkits and released models. We also demonstrate that the pre-trained models are suitable for downstream tasks, including automatic speech recognition and personalized text-to-speech synthesis. This toolkit is publicly available at https://github.com/alibaba-damo-academy/FunCodec.
The Interspeech 2024 Challenge on Speech Processing Using Discrete Units
Representing speech and audio signals in discrete units has become a compelling alternative to traditional high-dimensional feature vectors. Numerous studies have highlighted the efficacy of discrete units in various applications such as speech compression and restoration, speech recognition, and speech generation. To foster exploration in this domain, we introduce the Interspeech 2024 Challenge, which focuses on new speech processing benchmarks using discrete units. It encompasses three pivotal tasks, namely multilingual automatic speech recognition, text-to-speech, and singing voice synthesis, and aims to assess the potential applicability of discrete units in these tasks. This paper outlines the challenge designs and baseline descriptions. We also collate baseline and selected submission systems, along with preliminary findings, offering valuable contributions to future research in this evolving field.
Hybrid Audio Detection Using Fine-Tuned Audio Spectrogram Transformers: A Dataset-Driven Evaluation of Mixed AI-Human Speech
The rapid advancement of artificial intelligence (AI) has enabled sophisticated audio generation and voice cloning technologies, posing significant security risks for applications reliant on voice authentication. While existing datasets and models primarily focus on distinguishing between human and fully synthetic speech, real-world attacks often involve audio that combines both genuine and cloned segments. To address this gap, we construct a novel hybrid audio dataset incorporating human, AI-generated, cloned, and mixed audio samples. We further propose fine-tuned Audio Spectrogram Transformer (AST)-based models tailored for detecting these complex acoustic patterns. Extensive experiments demonstrate that our approach significantly outperforms existing baselines in mixed-audio detection, achieving 97\% classification accuracy. Our findings highlight the importance of hybrid datasets and tailored models in advancing the robustness of speech-based authentication systems.
WenetSpeech: A 10000+ Hours Multi-domain Mandarin Corpus for Speech Recognition
In this paper, we present WenetSpeech, a multi-domain Mandarin corpus consisting of 10000+ hours high-quality labeled speech, 2400+ hours weakly labeled speech, and about 10000 hours unlabeled speech, with 22400+ hours in total. We collect the data from YouTube and Podcast, which covers a variety of speaking styles, scenarios, domains, topics, and noisy conditions. An optical character recognition (OCR) based method is introduced to generate the audio/text segmentation candidates for the YouTube data on its corresponding video captions, while a high-quality ASR transcription system is used to generate audio/text pair candidates for the Podcast data. Then we propose a novel end-to-end label error detection approach to further validate and filter the candidates. We also provide three manually labelled high-quality test sets along with WenetSpeech for evaluation -- Dev for cross-validation purpose in training, Test_Net, collected from Internet for matched test, and Test\_Meeting, recorded from real meetings for more challenging mismatched test. Baseline systems trained with WenetSpeech are provided for three popular speech recognition toolkits, namely Kaldi, ESPnet, and WeNet, and recognition results on the three test sets are also provided as benchmarks. To the best of our knowledge, WenetSpeech is the current largest open-sourced Mandarin speech corpus with transcriptions, which benefits research on production-level speech recognition.
Effective Pre-Training of Audio Transformers for Sound Event Detection
We propose a pre-training pipeline for audio spectrogram transformers for frame-level sound event detection tasks. On top of common pre-training steps, we add a meticulously designed training routine on AudioSet frame-level annotations. This includes a balanced sampler, aggressive data augmentation, and ensemble knowledge distillation. For five transformers, we obtain a substantial performance improvement over previously available checkpoints both on AudioSet frame-level predictions and on frame-level sound event detection downstream tasks, confirming our pipeline's effectiveness. We publish the resulting checkpoints that researchers can directly fine-tune to build high-performance models for sound event detection tasks.
ESPnet-SpeechLM: An Open Speech Language Model Toolkit
We present ESPnet-SpeechLM, an open toolkit designed to democratize the development of speech language models (SpeechLMs) and voice-driven agentic applications. The toolkit standardizes speech processing tasks by framing them as universal sequential modeling problems, encompassing a cohesive workflow of data preprocessing, pre-training, inference, and task evaluation. With ESPnet-SpeechLM, users can easily define task templates and configure key settings, enabling seamless and streamlined SpeechLM development. The toolkit ensures flexibility, efficiency, and scalability by offering highly configurable modules for every stage of the workflow. To illustrate its capabilities, we provide multiple use cases demonstrating how competitive SpeechLMs can be constructed with ESPnet-SpeechLM, including a 1.7B-parameter model pre-trained on both text and speech tasks, across diverse benchmarks. The toolkit and its recipes are fully transparent and reproducible at: https://github.com/espnet/espnet/tree/speechlm.
Long-Form Speech Generation with Spoken Language Models
We consider the generative modeling of speech over multiple minutes, a requirement for long-form multimedia generation and audio-native voice assistants. However, current spoken language models struggle to generate plausible speech past tens of seconds, from high temporal resolution of speech tokens causing loss of coherence, to architectural issues with long-sequence training or extrapolation, to memory costs at inference time. With these considerations we propose SpeechSSM, the first speech language model to learn from and sample long-form spoken audio (e.g., 16 minutes of read or extemporaneous speech) in a single decoding session without text intermediates, based on recent advances in linear-time sequence modeling. Furthermore, to address growing challenges in spoken language evaluation, especially in this new long-form setting, we propose: new embedding-based and LLM-judged metrics; quality measurements over length and time; and a new benchmark for long-form speech processing and generation, LibriSpeech-Long. Speech samples and the dataset are released at https://google.github.io/tacotron/publications/speechssm/
OWSM-CTC: An Open Encoder-Only Speech Foundation Model for Speech Recognition, Translation, and Language Identification
There has been an increasing interest in large speech models that can perform multiple speech processing tasks in a single model. Such models usually adopt the encoder-decoder or decoder-only architecture due to their popularity and good performance in many domains. However, autoregressive models can be slower during inference compared to non-autoregressive models and also have potential risks of hallucination. Though prior studies observed promising results of non-autoregressive models for certain tasks at small scales, it remains unclear if they can be scaled to speech-to-text generation in diverse languages and tasks. Inspired by the Open Whisper-style Speech Model (OWSM) project, we propose OWSM-CTC, a novel encoder-only speech foundation model based on Connectionist Temporal Classification (CTC). It is trained on 180k hours of public audio data for multilingual automatic speech recognition (ASR), speech translation (ST), and language identification (LID). Compared to encoder-decoder OWSM, our OWSM-CTC achieves competitive results on ASR and up to 25% relative improvement on ST, while it is more robust and 3 to 4 times faster for inference. OWSM-CTC also improves the long-form ASR result with 20x speed-up. We will publicly release our codebase, pre-trained model, and training logs to promote open science in speech foundation models.


Learning Environmental Sounds with Multi-scale Convolutional Neural Network
Deep learning has dramatically improved the performance of sounds recognition. However, learning acoustic models directly from the raw waveform is still challenging. Current waveform-based models generally use time-domain convolutional layers to extract features. The features extracted by single size filters are insufficient for building discriminative representation of audios. In this paper, we propose multi-scale convolution operation, which can get better audio representation by improving the frequency resolution and learning filters cross all frequency area. For leveraging the waveform-based features and spectrogram-based features in a single model, we introduce two-phase method to fuse the different features. Finally, we propose a novel end-to-end network called WaveMsNet based on the multi-scale convolution operation and two-phase method. On the environmental sounds classification datasets ESC-10 and ESC-50, the classification accuracies of our WaveMsNet achieve 93.75% and 79.10% respectively, which improve significantly from the previous methods.
DrVoice: Parallel Speech-Text Voice Conversation Model via Dual-Resolution Speech Representations
Recent studies on end-to-end (E2E) speech generation with large language models (LLMs) have attracted significant community attention, with multiple works extending text-based LLMs to generate discrete speech tokens. Existing E2E approaches primarily fall into two categories: (1) Methods that generate discrete speech tokens independently without incorporating them into the LLM's autoregressive process, resulting in text generation being unaware of concurrent speech synthesis. (2) Models that generate interleaved or parallel speech-text tokens through joint autoregressive modeling, enabling mutual modality awareness during generation. This paper presents DrVoice, a parallel speech-text voice conversation model based on joint autoregressive modeling, featuring dual-resolution speech representations. Notably, while current methods utilize mainly 12.5Hz input audio representation, our proposed dual-resolution mechanism reduces the input frequency for the LLM to 5Hz, significantly reducing computational cost and alleviating the frequency discrepancy between speech and text tokens and in turn better exploiting LLMs' capabilities. Experimental results demonstrate that DRVOICE-7B establishes new state-of-the-art (SOTA) on OpenAudioBench and Big Bench Audio benchmarks, while achieving performance comparable to the SOTA on VoiceBench and UltraEval-Audio benchmarks, making it a leading open-source speech foundation model in ~7B models.
DiCoW: Diarization-Conditioned Whisper for Target Speaker Automatic Speech Recognition
Speaker-attributed automatic speech recognition (ASR) in multi-speaker environments remains a significant challenge, particularly when systems conditioned on speaker embeddings fail to generalize to unseen speakers. In this work, we propose Diarization-Conditioned Whisper (DiCoW), a novel approach to target-speaker ASR that leverages speaker diarization outputs as conditioning information. DiCoW extends the pre-trained Whisper model by integrating diarization labels directly, eliminating reliance on speaker embeddings and reducing the need for extensive speaker-specific training data. Our method introduces frame-level diarization-dependent transformations (FDDT) and query-key biasing (QKb) techniques to refine the model's focus on target speakers while effectively handling overlapping speech. By leveraging diarization outputs as conditioning signals, DiCoW simplifies the workflow for multi-speaker ASR, improves generalization to unseen speakers and enables more reliable transcription in real-world multi-speaker recordings. Additionally, we explore the integration of a connectionist temporal classification (CTC) head to Whisper and demonstrate its ability to improve transcription efficiency through hybrid decoding. Notably, we show that our approach is not limited to Whisper; it also provides similar benefits when applied to the Branchformer model. We validate DiCoW on real-world datasets, including AMI and NOTSOFAR-1 from CHiME-8 challenge, as well as synthetic benchmarks such as Libri2Mix and LibriCSS, enabling direct comparisons with previous methods. Results demonstrate that DiCoW enhances the model's target-speaker ASR capabilities while maintaining Whisper's accuracy and robustness on single-speaker data.

End-to-end Whispered Speech Recognition with Frequency-weighted Approaches and Pseudo Whisper Pre-training
Whispering is an important mode of human speech, but no end-to-end recognition results for it were reported yet, probably due to the scarcity of available whispered speech data. In this paper, we present several approaches for end-to-end (E2E) recognition of whispered speech considering the special characteristics of whispered speech and the scarcity of data. This includes a frequency-weighted SpecAugment policy and a frequency-divided CNN feature extractor for better capturing the high-frequency structures of whispered speech, and a layer-wise transfer learning approach to pre-train a model with normal or normal-to-whispered converted speech then fine-tune it with whispered speech to bridge the gap between whispered and normal speech. We achieve an overall relative reduction of 19.8% in PER and 44.4% in CER on a relatively small whispered TIMIT corpus. The results indicate as long as we have a good E2E model pre-trained on normal or pseudo-whispered speech, a relatively small set of whispered speech may suffice to obtain a reasonably good E2E whispered speech recognizer.
MMedFD: A Real-world Healthcare Benchmark for Multi-turn Full-Duplex Automatic Speech Recognition
Automatic speech recognition (ASR) in clinical dialogue demands robustness to full-duplex interaction, speaker overlap, and low-latency constraints, yet open benchmarks remain scarce. We present MMedFD, the first real-world Chinese healthcare ASR corpus designed for multi-turn, full-duplex settings. Captured from a deployed AI assistant, the dataset comprises 5,805 annotated sessions with synchronized user and mixed-channel views, RTTM/CTM timing, and role labels. We introduce a model-agnostic pipeline for streaming segmentation, speaker attribution, and dialogue memory, and fine-tune Whisper-small on role-concatenated audio for long-context recognition. ASR evaluation includes WER, CER, and HC-WER, which measures concept-level accuracy across healthcare settings. LLM-generated responses are assessed using rubric-based and pairwise protocols. MMedFD establishes a reproducible framework for benchmarking streaming ASR and end-to-end duplex agents in healthcare deployment. The dataset and related resources are publicly available at https://github.com/Kinetics-JOJO/MMedFD
Speech Recognition for Analysis of Police Radio Communication
Police departments around the world use two-way radio for coordination. These broadcast police communications (BPC) are a unique source of information about everyday police activity and emergency response. Yet BPC are not transcribed, and their naturalistic audio properties make automatic transcription challenging. We collect a corpus of roughly 62,000 manually transcribed radio transmissions (~46 hours of audio) to evaluate the feasibility of automatic speech recognition (ASR) using modern recognition models. We evaluate the performance of off-the-shelf speech recognizers, models fine-tuned on BPC data, and customized end-to-end models. We find that both human and machine transcription is challenging in this domain. Large off-the-shelf ASR models perform poorly, but fine-tuned models can reach the approximate range of human performance. Our work suggests directions for future work, including analysis of short utterances and potential miscommunication in police radio interactions. We make our corpus and data annotation pipeline available to other researchers, to enable further research on recognition and analysis of police communication.

Preparing an Endangered Language for the Digital Age: The Case of Judeo-Spanish
We develop machine translation and speech synthesis systems to complement the efforts of revitalizing Judeo-Spanish, the exiled language of Sephardic Jews, which survived for centuries, but now faces the threat of extinction in the digital age. Building on resources created by the Sephardic community of Turkey and elsewhere, we create corpora and tools that would help preserve this language for future generations. For machine translation, we first develop a Spanish to Judeo-Spanish rule-based machine translation system, in order to generate large volumes of synthetic parallel data in the relevant language pairs: Turkish, English and Spanish. Then, we train baseline neural machine translation engines using this synthetic data and authentic parallel data created from translations by the Sephardic community. For text-to-speech synthesis, we present a 3.5 hour single speaker speech corpus for building a neural speech synthesis engine. Resources, model weights and online inference engines are shared publicly.


TF-Mamba: A Time-Frequency Network for Sound Source Localization
Sound source localization (SSL) determines the position of sound sources using multi-channel audio data. It is commonly used to improve speech enhancement and separation. Extracting spatial features is crucial for SSL, especially in challenging acoustic environments. Recently, a novel structure referred to as Mamba demonstrated notable performance across various sequence-based modalities. This study introduces the Mamba for SSL tasks. We consider the Mamba-based model to analyze spatial features from speech signals by fusing both time and frequency features, and we develop an SSL system called TF-Mamba. This system integrates time and frequency fusion, with Bidirectional Mamba managing both time-wise and frequency-wise processing. We conduct the experiments on the simulated and real datasets. Experiments show that TF-Mamba significantly outperforms other advanced methods. The code will be publicly released in due course.
WavLM model ensemble for audio deepfake detection
Audio deepfake detection has become a pivotal task over the last couple of years, as many recent speech synthesis and voice cloning systems generate highly realistic speech samples, thus enabling their use in malicious activities. In this paper we address the issue of audio deepfake detection as it was set in the ASVspoof5 challenge. First, we benchmark ten types of pretrained representations and show that the self-supervised representations stemming from the wav2vec2 and wavLM families perform best. Of the two, wavLM is better when restricting the pretraining data to LibriSpeech, as required by the challenge rules. To further improve performance, we finetune the wavLM model for the deepfake detection task. We extend the ASVspoof5 dataset with samples from other deepfake detection datasets and apply data augmentation. Our final challenge submission consists of a late fusion combination of four models and achieves an equal error rate of 6.56% and 17.08% on the two evaluation sets.


A dataset and model for recognition of audiologically relevant environments for hearing aids: AHEAD-DS and YAMNet+
Scene recognition of audiologically relevant environments is important for hearing aids; however, it is challenging, in part because of the limitations of existing datasets. Datasets often lack public accessibility, completeness, or audiologically relevant labels, hindering systematic comparison of machine learning models. Deploying these models on resource-constrained edge devices presents another challenge. Our solution is two-fold: we leverage several open source datasets to create AHEAD-DS, a dataset designed for scene recognition of audiologically relevant environments, and introduce YAMNet+, a sound recognition model. AHEAD-DS aims to provide a standardised, publicly available dataset with consistent labels relevant to hearing aids, facilitating model comparison. YAMNet+ is designed for deployment on edge devices like smartphones connected to hearing devices, such as hearing aids and wireless earphones with hearing aid functionality; serving as a baseline model for sound-based scene recognition. YAMNet+ achieved a mean average precision of 0.83 and accuracy of 0.93 on the testing set of AHEAD-DS across fourteen categories of audiologically relevant environments. We found that applying transfer learning from the pretrained YAMNet model was essential. We demonstrated real-time sound-based scene recognition capabilities on edge devices by deploying YAMNet+ to an Android smartphone. Even with a Google Pixel 3 (a phone with modest specifications, released in 2018), the model processes audio with approximately 50ms of latency to load the model, and an approximate linear increase of 30ms per 1 second of audio. Our website and code https://github.com/Australian-Future-Hearing-Initiative .
AI-Invented Tonal Languages: Preventing a Machine Lingua Franca Beyond Human Understanding
This paper investigates the potential for large language models (LLMs) to develop private tonal languages for machine-to-machine (M2M) communication. Inspired by cryptophasia in human twins (affecting up to 50% of twin births) and natural tonal languages like Mandarin and Vietnamese, we implement a precise character-to-frequency mapping system that encodes the full ASCII character set (32-126) using musical semitones. Each character is assigned a unique frequency, creating a logarithmic progression beginning with space (220 Hz) and ending with tilde (50,175.42 Hz). This spans approximately 7.9 octaves, with higher characters deliberately mapped to ultrasonic frequencies beyond human perception (>20 kHz). Our implemented software prototype demonstrates this encoding through visualization, auditory playback, and ABC musical notation, allowing for analysis of information density and transmission speed. Testing reveals that tonal encoding can achieve information rates exceeding human speech while operating partially outside human perceptual boundaries. This work responds directly to concerns about AI systems catastrophically developing private languages within the next five years, providing a concrete prototype software example of how such communication might function and the technical foundation required for its emergence, detection, and governance.

A Dataset of Reverberant Spatial Sound Scenes with Moving Sources for Sound Event Localization and Detection
This report presents the dataset and the evaluation setup of the Sound Event Localization & Detection (SELD) task for the DCASE 2020 Challenge. The SELD task refers to the problem of trying to simultaneously classify a known set of sound event classes, detect their temporal activations, and estimate their spatial directions or locations while they are active. To train and test SELD systems, datasets of diverse sound events occurring under realistic acoustic conditions are needed. Compared to the previous challenge, a significantly more complex dataset was created for DCASE 2020. The two key differences are a more diverse range of acoustical conditions, and dynamic conditions, i.e. moving sources. The spatial sound scenes are created using real room impulse responses captured in a continuous manner with a slowly moving excitation source. Both static and moving sound events are synthesized from them. Ambient noise recorded on location is added to complete the generation of scene recordings. A baseline SELD method accompanies the dataset, based on a convolutional recurrent neural network, to provide benchmark scores for the task. The baseline is an updated version of the one used in the previous challenge, with input features and training modifications to improve its performance.
MiDashengLM: Efficient Audio Understanding with General Audio Captions
Current approaches for large audio language models (LALMs) often rely on closed data sources or proprietary models, limiting their generalization and accessibility. This paper introduces MiDashengLM, a novel open audio-language model designed for efficient and comprehensive audio understanding through the use of general audio captions using our novel ACAVCaps training dataset. MiDashengLM exclusively relies on publicly available pretraining and supervised fine-tuning (SFT) datasets, ensuring full transparency and reproducibility. At its core, MiDashengLM integrates Dasheng, an open-source audio encoder, specifically engineered to process diverse auditory information effectively. Unlike previous works primarily focused on Automatic Speech Recognition (ASR) based audio-text alignment, our strategy centers on general audio captions, fusing speech, sound and music information into one textual representation, enabling a holistic textual representation of complex audio scenes. Lastly, MiDashengLM provides an up to 4x speedup in terms of time-to-first-token (TTFT) and up to 20x higher throughput than comparable models. Checkpoints are available online at https://huggingface.co/mispeech/midashenglm-7b and https://github.com/xiaomi-research/dasheng-lm.
Audio-Language Datasets of Scenes and Events: A Survey
Audio-language models (ALMs) process sounds to provide a linguistic description of sound-producing events and scenes. Recent advances in computing power and dataset creation have led to significant progress in this domain. This paper surveys existing datasets used for training audio-language models, emphasizing the recent trend towards using large, diverse datasets to enhance model performance. Key sources of these datasets include the Freesound platform and AudioSet that have contributed to the field's rapid growth. Although prior surveys primarily address techniques and training details, this survey categorizes and evaluates a wide array of datasets, addressing their origins, characteristics, and use cases. It also performs a data leak analysis to ensure dataset integrity and mitigate bias between datasets. This survey was conducted by analyzing research papers up to and including December 2023, and does not contain any papers after that period.

Enhancing Speech Emotion Recognition with Graph-Based Multimodal Fusion and Prosodic Features for the Speech Emotion Recognition in Naturalistic Conditions Challenge at Interspeech 2025
Training SER models in natural, spontaneous speech is especially challenging due to the subtle expression of emotions and the unpredictable nature of real-world audio. In this paper, we present a robust system for the INTERSPEECH 2025 Speech Emotion Recognition in Naturalistic Conditions Challenge, focusing on categorical emotion recognition. Our method combines state-of-the-art audio models with text features enriched by prosodic and spectral cues. In particular, we investigate the effectiveness of Fundamental Frequency (F0) quantization and the use of a pretrained audio tagging model. We also employ an ensemble model to improve robustness. On the official test set, our system achieved a Macro F1-score of 39.79% (42.20% on validation). Our results underscore the potential of these methods, and analysis of fusion techniques confirmed the effectiveness of Graph Attention Networks. Our source code is publicly available.


Towards Holistic Evaluation of Large Audio-Language Models: A Comprehensive Survey
With advancements in large audio-language models (LALMs), which enhance large language models (LLMs) with auditory capabilities, these models are expected to demonstrate universal proficiency across various auditory tasks. While numerous benchmarks have emerged to assess LALMs' performance, they remain fragmented and lack a structured taxonomy. To bridge this gap, we conduct a comprehensive survey and propose a systematic taxonomy for LALM evaluations, categorizing them into four dimensions based on their objectives: (1) General Auditory Awareness and Processing, (2) Knowledge and Reasoning, (3) Dialogue-oriented Ability, and (4) Fairness, Safety, and Trustworthiness. We provide detailed overviews within each category and highlight challenges in this field, offering insights into promising future directions. To the best of our knowledge, this is the first survey specifically focused on the evaluations of LALMs, providing clear guidelines for the community. We will release the collection of the surveyed papers and actively maintain it to support ongoing advancements in the field.


OpenBEATs: A Fully Open-Source General-Purpose Audio Encoder
Masked token prediction has emerged as a powerful pre-training objective across language, vision, and speech, offering the potential to unify these diverse modalities through a single pre-training task. However, its application for general audio understanding remains underexplored, with BEATs being the only notable example. BEATs has seen limited modifications due to the absence of open-source pre-training code. Furthermore, BEATs was trained only on AudioSet, restricting its broader downstream applicability. To address these gaps, we present OpenBEATs, an open-source framework that extends BEATs via multi-domain audio pre-training. We conduct comprehensive evaluations across six types of tasks, twenty five datasets, and three audio domains, including audio reasoning tasks such as audio question answering, entailment, and captioning. OpenBEATs achieves state-of-the-art performance on six bioacoustics datasets, two environmental sound datasets and five reasoning datasets, performing better than models exceeding a billion parameters at one-fourth their parameter size. These results demonstrate the effectiveness of multi-domain datasets and masked token prediction task to learn general-purpose audio representations. To promote further research and reproducibility, we release all pre-training and evaluation code, pretrained and fine-tuned checkpoints, and training logs at https://shikhar-s.github.io/OpenBEATs

Learning to rumble: Automated elephant call classification, detection and endpointing using deep architectures
We consider the problem of detecting, isolating and classifying elephant calls in continuously recorded audio. Such automatic call characterisation can assist conservation efforts and inform environmental management strategies. In contrast to previous work in which call detection was performed at a segment level, we perform call detection at a frame level which implicitly also allows call endpointing, the isolation of a call in a longer recording. For experimentation, we employ two annotated datasets, one containing Asian and the other African elephant vocalisations. We evaluate several shallow and deep classifier models, and show that the current best performance can be improved by using an audio spectrogram transformer (AST), a neural architecture which has not been used for this purpose before, and which we have configured in a novel sequence-to-sequence manner. We also show that using transfer learning by pre-training leads to further improvements both in terms of computational complexity and performance. Finally, we consider sub-call classification using an accepted taxonomy of call types, a task which has not previously been considered. We show that also in this case the transformer architectures provide the best performance. Our best classifiers achieve an average precision (AP) of 0.962 for framewise binary call classification, and an area under the receiver operating characteristic (AUC) of 0.957 and 0.979 for call classification with 5 classes and sub-call classification with 7 classes respectively. All of these represent either new benchmarks (sub-call classifications) or improvements on previously best systems. We conclude that a fully-automated elephant call detection and subcall classification system is within reach. Such a system would provide valuable information on the behaviour and state of elephant herds for the purposes of conservation and management.
Wav2Small: Distilling Wav2Vec2 to 72K parameters for Low-Resource Speech emotion recognition
Speech Emotion Recognition (SER) needs high computational resources to overcome the challenge of substantial annotator disagreement. Today SER is shifting towards dimensional annotations of arousal, dominance, and valence (A/D/V). Universal metrics as the L2 distance prove unsuitable for evaluating A/D/V accuracy due to non converging consensus of annotator opinions. However, Concordance Correlation Coefficient (CCC) arose as an alternative metric for A/D/V where a model's output is evaluated to match a whole dataset's CCC rather than L2 distances of individual audios. Recent studies have shown that Wav2Vec2.0 / WavLM architectures outputing a float value for each A/D/V dimension achieve today's State-of-the-art (SOTA) CCC on A/D/V. The Wav2Vec2.0 / WavLM family has high computational footprint, but training tiny models using human annotations has been unsuccessful. In this paper we use a large Transformer SOTA A/D/V model as Teacher/Annotator to train 5 student models: 4 MobileNets and our proposed Wav2Small, using only the Teacher's A/D/V predictions instead of human annotations. We chose MobileNet-V4 / MobileNet-V3 as students, as MobileNet has been designed for fast execution times. We propose Wav2Small an architecture designed for minimal parameter number and RAM consumption. Wav2Small with an .onnx (quantized) of only 60KB is a potential solution for A/D/V on hearing aids, having only 72K parameters vs 3.12M parameters for MobileNet-V4-Small. The Teacher model we construct sets a new SOTA on the MSP Podcast Test-1 dataset with valence CCC=0.676.
Audio Retrieval with Natural Language Queries: A Benchmark Study
The objectives of this work are cross-modal text-audio and audio-text retrieval, in which the goal is to retrieve the audio content from a pool of candidates that best matches a given written description and vice versa. Text-audio retrieval enables users to search large databases through an intuitive interface: they simply issue free-form natural language descriptions of the sound they would like to hear. To study the tasks of text-audio and audio-text retrieval, which have received limited attention in the existing literature, we introduce three challenging new benchmarks. We first construct text-audio and audio-text retrieval benchmarks from the AudioCaps and Clotho audio captioning datasets. Additionally, we introduce the SoundDescs benchmark, which consists of paired audio and natural language descriptions for a diverse collection of sounds that are complementary to those found in AudioCaps and Clotho. We employ these three benchmarks to establish baselines for cross-modal text-audio and audio-text retrieval, where we demonstrate the benefits of pre-training on diverse audio tasks. We hope that our benchmarks will inspire further research into audio retrieval with free-form text queries. Code, audio features for all datasets used, and the SoundDescs dataset are publicly available at https://github.com/akoepke/audio-retrieval-benchmark.
Recent Advances in Speech Language Models: A Survey
Large Language Models (LLMs) have recently garnered significant attention, primarily for their capabilities in text-based interactions. However, natural human interaction often relies on speech, necessitating a shift towards voice-based models. A straightforward approach to achieve this involves a pipeline of ``Automatic Speech Recognition (ASR) + LLM + Text-to-Speech (TTS)", where input speech is transcribed to text, processed by an LLM, and then converted back to speech. Despite being straightforward, this method suffers from inherent limitations, such as information loss during modality conversion and error accumulation across the three stages. To address these issues, Speech Language Models (SpeechLMs) -- end-to-end models that generate speech without converting from text -- have emerged as a promising alternative. This survey paper provides the first comprehensive overview of recent methodologies for constructing SpeechLMs, detailing the key components of their architecture and the various training recipes integral to their development. Additionally, we systematically survey the various capabilities of SpeechLMs, categorize the evaluation metrics for SpeechLMs, and discuss the challenges and future research directions in this rapidly evolving field.
FRCRN: Boosting Feature Representation using Frequency Recurrence for Monaural Speech Enhancement
Convolutional recurrent networks (CRN) integrating a convolutional encoder-decoder (CED) structure and a recurrent structure have achieved promising performance for monaural speech enhancement. However, feature representation across frequency context is highly constrained due to limited receptive fields in the convolutions of CED. In this paper, we propose a convolutional recurrent encoder-decoder (CRED) structure to boost feature representation along the frequency axis. The CRED applies frequency recurrence on 3D convolutional feature maps along the frequency axis following each convolution, therefore, it is capable of catching long-range frequency correlations and enhancing feature representations of speech inputs. The proposed frequency recurrence is realized efficiently using a feedforward sequential memory network (FSMN). Besides the CRED, we insert two stacked FSMN layers between the encoder and the decoder to model further temporal dynamics. We name the proposed framework as Frequency Recurrent CRN (FRCRN). We design FRCRN to predict complex Ideal Ratio Mask (cIRM) in complex-valued domain and optimize FRCRN using both time-frequency-domain and time-domain losses. Our proposed approach achieved state-of-the-art performance on wideband benchmark datasets and achieved 2nd place for the real-time fullband track in terms of Mean Opinion Score (MOS) and Word Accuracy (WAcc) in the ICASSP 2022 Deep Noise Suppression (DNS) challenge (https://github.com/alibabasglab/FRCRN).

Spoken Question Answering and Speech Continuation Using Spectrogram-Powered LLM
We present a novel approach to adapting pre-trained large language models (LLMs) to perform question answering (QA) and speech continuation. By endowing the LLM with a pre-trained speech encoder, our model becomes able to take speech inputs and generate speech outputs. The entire system is trained end-to-end and operates directly on spectrograms, simplifying our architecture. Key to our approach is a training objective that jointly supervises speech recognition, text continuation, and speech synthesis using only paired speech-text pairs, enabling a `cross-modal' chain-of-thought within a single decoding pass. Our method surpasses existing spoken language models in speaker preservation and semantic coherence. Furthermore, the proposed model improves upon direct initialization in retaining the knowledge of the original LLM as demonstrated through spoken QA datasets. Audio samples can be found at https://michelleramanovich.github.io/spectron/spectron