Get trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
TNet: Terrace Convolutional Decoder Network for Remote Sensing Image Semantic Segmentation
In remote sensing, most segmentation networks adopt the UNet architecture, often incorporating modules such as Transformers or Mamba to enhance global-local feature interactions within decoder stages. However, these enhancements typically focus on intra-scale relationships and neglect the global contextual dependencies across multiple resolutions. To address this limitation, we introduce the Terrace Convolutional Decoder Network (TNet), a simple yet effective architecture that leverages only convolution and addition operations to progressively integrate low-resolution features (rich in global context) into higher-resolution features (rich in local details) across decoding stages. This progressive fusion enables the model to learn spatially-aware convolutional kernels that naturally blend global and local information in a stage-wise manner. We implement TNet with a ResNet-18 encoder (TNet-R) and evaluate it on three benchmark datasets. TNet-R achieves competitive performance with a mean Intersection-over-Union (mIoU) of 85.35\% on ISPRS Vaihingen, 87.05\% on ISPRS Potsdam, and 52.19\% on LoveDA, while maintaining high computational efficiency. Code is publicly available.
Defects of Convolutional Decoder Networks in Frequency Representation
In this paper, we prove representation bottlenecks of a cascaded convolutional decoder network, considering the capacity of representing different frequency components of an input sample. We conduct the discrete Fourier transform on each channel of the feature map in an intermediate layer of the decoder network. Then, we introduce the rule of the forward propagation of such intermediate-layer spectrum maps, which is equivalent to the forward propagation of feature maps through a convolutional layer. Based on this, we find that each frequency component in the spectrum map is forward propagated independently with other frequency components. Furthermore, we prove two bottlenecks in representing feature spectrums. First, we prove that the convolution operation, the zero-padding operation, and a set of other settings all make a convolutional decoder network more likely to weaken high-frequency components. Second, we prove that the upsampling operation generates a feature spectrum, in which strong signals repetitively appears at certain frequencies.


Generating Summaries with Topic Templates and Structured Convolutional Decoders
Existing neural generation approaches create multi-sentence text as a single sequence. In this paper we propose a structured convolutional decoder that is guided by the content structure of target summaries. We compare our model with existing sequential decoders on three data sets representing different domains. Automatic and human evaluation demonstrate that our summaries have better content coverage.
A Two-Step Graph Convolutional Decoder for Molecule Generation
We propose a simple auto-encoder framework for molecule generation. The molecular graph is first encoded into a continuous latent representation z, which is then decoded back to a molecule. The encoding process is easy, but the decoding process remains challenging. In this work, we introduce a simple two-step decoding process. In a first step, a fully connected neural network uses the latent vector z to produce a molecular formula, for example CO_2 (one carbon and two oxygen atoms). In a second step, a graph convolutional neural network uses the same latent vector z to place bonds between the atoms that were produced in the first step (for example a double bond will be placed between the carbon and each of the oxygens). This two-step process, in which a bag of atoms is first generated, and then assembled, provides a simple framework that allows us to develop an efficient molecule auto-encoder. Numerical experiments on basic tasks such as novelty, uniqueness, validity and optimized chemical property for the 250k ZINC molecules demonstrate the performances of the proposed system. Particularly, we achieve the highest reconstruction rate of 90.5\%, improving the previous rate of 76.7\%. We also report the best property improvement results when optimization is constrained by the molecular distance between the original and generated molecules.
ConvMath: A Convolutional Sequence Network for Mathematical Expression Recognition
Despite the recent advances in optical character recognition (OCR), mathematical expressions still face a great challenge to recognize due to their two-dimensional graphical layout. In this paper, we propose a convolutional sequence modeling network, ConvMath, which converts the mathematical expression description in an image into a LaTeX sequence in an end-to-end way. The network combines an image encoder for feature extraction and a convolutional decoder for sequence generation. Compared with other Long Short Term Memory(LSTM) based encoder-decoder models, ConvMath is entirely based on convolution, thus it is easy to perform parallel computation. Besides, the network adopts multi-layer attention mechanism in the decoder, which allows the model to align output symbols with source feature vectors automatically, and alleviates the problem of lacking coverage while training the model. The performance of ConvMath is evaluated on an open dataset named IM2LATEX-100K, including 103556 samples. The experimental results demonstrate that the proposed network achieves state-of-the-art accuracy and much better efficiency than previous methods.
Convolutional Transformer based Dual Discriminator Generative Adversarial Networks for Video Anomaly Detection
Detecting abnormal activities in real-world surveillance videos is an important yet challenging task as the prior knowledge about video anomalies is usually limited or unavailable. Despite that many approaches have been developed to resolve this problem, few of them can capture the normal spatio-temporal patterns effectively and efficiently. Moreover, existing works seldom explicitly consider the local consistency at frame level and global coherence of temporal dynamics in video sequences. To this end, we propose Convolutional Transformer based Dual Discriminator Generative Adversarial Networks (CT-D2GAN) to perform unsupervised video anomaly detection. Specifically, we first present a convolutional transformer to perform future frame prediction. It contains three key components, i.e., a convolutional encoder to capture the spatial information of the input video clips, a temporal self-attention module to encode the temporal dynamics, and a convolutional decoder to integrate spatio-temporal features and predict the future frame. Next, a dual discriminator based adversarial training procedure, which jointly considers an image discriminator that can maintain the local consistency at frame-level and a video discriminator that can enforce the global coherence of temporal dynamics, is employed to enhance the future frame prediction. Finally, the prediction error is used to identify abnormal video frames. Thoroughly empirical studies on three public video anomaly detection datasets, i.e., UCSD Ped2, CUHK Avenue, and Shanghai Tech Campus, demonstrate the effectiveness of the proposed adversarial spatio-temporal modeling framework.


Walking Your LiDOG: A Journey Through Multiple Domains for LiDAR Semantic Segmentation
The ability to deploy robots that can operate safely in diverse environments is crucial for developing embodied intelligent agents. As a community, we have made tremendous progress in within-domain LiDAR semantic segmentation. However, do these methods generalize across domains? To answer this question, we design the first experimental setup for studying domain generalization (DG) for LiDAR semantic segmentation (DG-LSS). Our results confirm a significant gap between methods, evaluated in a cross-domain setting: for example, a model trained on the source dataset (SemanticKITTI) obtains 26.53 mIoU on the target data, compared to 48.49 mIoU obtained by the model trained on the target domain (nuScenes). To tackle this gap, we propose the first method specifically designed for DG-LSS, which obtains 34.88 mIoU on the target domain, outperforming all baselines. Our method augments a sparse-convolutional encoder-decoder 3D segmentation network with an additional, dense 2D convolutional decoder that learns to classify a birds-eye view of the point cloud. This simple auxiliary task encourages the 3D network to learn features that are robust to sensor placement shifts and resolution, and are transferable across domains. With this work, we aim to inspire the community to develop and evaluate future models in such cross-domain conditions.

Boosting Latent Diffusion with Flow Matching
Recently, there has been tremendous progress in visual synthesis and the underlying generative models. Here, diffusion models (DMs) stand out particularly, but lately, flow matching (FM) has also garnered considerable interest. While DMs excel in providing diverse images, they suffer from long training and slow generation. With latent diffusion, these issues are only partially alleviated. Conversely, FM offers faster training and inference but exhibits less diversity in synthesis. We demonstrate that introducing FM between the Diffusion model and the convolutional decoder offers high-resolution image synthesis with reduced computational cost and model size. Diffusion can then efficiently provide the necessary generation diversity. FM compensates for the lower resolution, mapping the small latent space to a high-dimensional one. Subsequently, the convolutional decoder of the LDM maps these latents to high-resolution images. By combining the diversity of DMs, the efficiency of FMs, and the effectiveness of convolutional decoders, we achieve state-of-the-art high-resolution image synthesis at 1024^2 with minimal computational cost. Importantly, our approach is orthogonal to recent approximation and speed-up strategies for the underlying DMs, making it easily integrable into various DM frameworks.



Efficient Self-supervised Learning with Contextualized Target Representations for Vision, Speech and Language
Current self-supervised learning algorithms are often modality-specific and require large amounts of computational resources. To address these issues, we increase the training efficiency of data2vec, a learning objective that generalizes across several modalities. We do not encode masked tokens, use a fast convolutional decoder and amortize the effort to build teacher representations. data2vec 2.0 benefits from the rich contextualized target representations introduced in data2vec which enable a fast self-supervised learner. Experiments on ImageNet-1K image classification show that data2vec 2.0 matches the accuracy of Masked Autoencoders in 16.4x lower pre-training time, on Librispeech speech recognition it performs as well as wav2vec 2.0 in 10.6x less time, and on GLUE natural language understanding it matches a retrained RoBERTa model in half the time. Trading some speed for accuracy results in ImageNet-1K top-1 accuracy of 86.8\% with a ViT-L model trained for 150 epochs.

CoherentGS: Sparse Novel View Synthesis with Coherent 3D Gaussians
The field of 3D reconstruction from images has rapidly evolved in the past few years, first with the introduction of Neural Radiance Field (NeRF) and more recently with 3D Gaussian Splatting (3DGS). The latter provides a significant edge over NeRF in terms of the training and inference speed, as well as the reconstruction quality. Although 3DGS works well for dense input images, the unstructured point-cloud like representation quickly overfits to the more challenging setup of extremely sparse input images (e.g., 3 images), creating a representation that appears as a jumble of needles from novel views. To address this issue, we propose regularized optimization and depth-based initialization. Our key idea is to introduce a structured Gaussian representation that can be controlled in 2D image space. We then constraint the Gaussians, in particular their position, and prevent them from moving independently during optimization. Specifically, we introduce single and multiview constraints through an implicit convolutional decoder and a total variation loss, respectively. With the coherency introduced to the Gaussians, we further constrain the optimization through a flow-based loss function. To support our regularized optimization, we propose an approach to initialize the Gaussians using monocular depth estimates at each input view. We demonstrate significant improvements compared to the state-of-the-art sparse-view NeRF-based approaches on a variety of scenes.

Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights
Modern Parameter-Efficient Fine-Tuning (PEFT) methods such as low-rank adaptation (LoRA) reduce the cost of customizing large language models (LLMs), yet still require a separate optimization run for every downstream dataset. We introduce Drag-and-Drop LLMs (\textit{DnD)}, a prompt-conditioned parameter generator that eliminates per-task training by mapping a handful of unlabeled task prompts directly to LoRA weight updates. A lightweight text encoder distills each prompt batch into condition embeddings, which are then transformed by a cascaded hyper-convolutional decoder into the full set of LoRA matrices. Once trained in a diverse collection of prompt-checkpoint pairs, DnD produces task-specific parameters in seconds, yielding i) up to 12,000times lower overhead than full fine-tuning, ii) average gains up to 30\% in performance over the strongest training LoRAs on unseen common-sense reasoning, math, coding, and multimodal benchmarks, and iii) robust cross-domain generalization despite never seeing the target data or labels. Our results demonstrate that prompt-conditioned parameter generation is a viable alternative to gradient-based adaptation for rapidly specializing LLMs. Our project is available at https://jerryliang24.github.io/DnD{https://jerryliang24.github.io/DnD}.




Vision Transformers for Dense Prediction
We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art. Our models are available at https://github.com/intel-isl/DPT.


Byte-Level Recursive Convolutional Auto-Encoder for Text
This article proposes to auto-encode text at byte-level using convolutional networks with a recursive architecture. The motivation is to explore whether it is possible to have scalable and homogeneous text generation at byte-level in a non-sequential fashion through the simple task of auto-encoding. We show that non-sequential text generation from a fixed-length representation is not only possible, but also achieved much better auto-encoding results than recurrent networks. The proposed model is a multi-stage deep convolutional encoder-decoder framework using residual connections, containing up to 160 parameterized layers. Each encoder or decoder contains a shared group of modules that consists of either pooling or upsampling layers, making the network recursive in terms of abstraction levels in representation. Results for 6 large-scale paragraph datasets are reported, in 3 languages including Arabic, Chinese and English. Analyses are conducted to study several properties of the proposed model.
FRCRN: Boosting Feature Representation using Frequency Recurrence for Monaural Speech Enhancement
Convolutional recurrent networks (CRN) integrating a convolutional encoder-decoder (CED) structure and a recurrent structure have achieved promising performance for monaural speech enhancement. However, feature representation across frequency context is highly constrained due to limited receptive fields in the convolutions of CED. In this paper, we propose a convolutional recurrent encoder-decoder (CRED) structure to boost feature representation along the frequency axis. The CRED applies frequency recurrence on 3D convolutional feature maps along the frequency axis following each convolution, therefore, it is capable of catching long-range frequency correlations and enhancing feature representations of speech inputs. The proposed frequency recurrence is realized efficiently using a feedforward sequential memory network (FSMN). Besides the CRED, we insert two stacked FSMN layers between the encoder and the decoder to model further temporal dynamics. We name the proposed framework as Frequency Recurrent CRN (FRCRN). We design FRCRN to predict complex Ideal Ratio Mask (cIRM) in complex-valued domain and optimize FRCRN using both time-frequency-domain and time-domain losses. Our proposed approach achieved state-of-the-art performance on wideband benchmark datasets and achieved 2nd place for the real-time fullband track in terms of Mean Opinion Score (MOS) and Word Accuracy (WAcc) in the ICASSP 2022 Deep Noise Suppression (DNS) challenge (https://github.com/alibabasglab/FRCRN).

Deep Image Matting
Image matting is a fundamental computer vision problem and has many applications. Previous algorithms have poor performance when an image has similar foreground and background colors or complicated textures. The main reasons are prior methods 1) only use low-level features and 2) lack high-level context. In this paper, we propose a novel deep learning based algorithm that can tackle both these problems. Our deep model has two parts. The first part is a deep convolutional encoder-decoder network that takes an image and the corresponding trimap as inputs and predict the alpha matte of the image. The second part is a small convolutional network that refines the alpha matte predictions of the first network to have more accurate alpha values and sharper edges. In addition, we also create a large-scale image matting dataset including 49300 training images and 1000 testing images. We evaluate our algorithm on the image matting benchmark, our testing set, and a wide variety of real images. Experimental results clearly demonstrate the superiority of our algorithm over previous methods.
ShapeCodes: Self-Supervised Feature Learning by Lifting Views to Viewgrids
We introduce an unsupervised feature learning approach that embeds 3D shape information into a single-view image representation. The main idea is a self-supervised training objective that, given only a single 2D image, requires all unseen views of the object to be predictable from learned features. We implement this idea as an encoder-decoder convolutional neural network. The network maps an input image of an unknown category and unknown viewpoint to a latent space, from which a deconvolutional decoder can best "lift" the image to its complete viewgrid showing the object from all viewing angles. Our class-agnostic training procedure encourages the representation to capture fundamental shape primitives and semantic regularities in a data-driven manner---without manual semantic labels. Our results on two widely-used shape datasets show 1) our approach successfully learns to perform "mental rotation" even for objects unseen during training, and 2) the learned latent space is a powerful representation for object recognition, outperforming several existing unsupervised feature learning methods.
Better Tokens for Better 3D: Advancing Vision-Language Modeling in 3D Medical Imaging
Recent progress in vision-language modeling for 3D medical imaging has been fueled by large-scale computed tomography (CT) corpora with paired free-text reports, stronger architectures, and powerful pretrained models. This has enabled applications such as automated report generation and text-conditioned 3D image synthesis. Yet, current approaches struggle with high-resolution, long-sequence volumes: contrastive pretraining often yields vision encoders that are misaligned with clinical language, and slice-wise tokenization blurs fine anatomy, reducing diagnostic performance on downstream tasks. We introduce BTB3D (Better Tokens for Better 3D), a causal convolutional encoder-decoder that unifies 2D and 3D training and inference while producing compact, frequency-aware volumetric tokens. A three-stage training curriculum enables (i) local reconstruction, (ii) overlapping-window tiling, and (iii) long-context decoder refinement, during which the model learns from short slice excerpts yet generalizes to scans exceeding 300 slices without additional memory overhead. BTB3D sets a new state-of-the-art on two key tasks: it improves BLEU scores and increases clinical F1 by 40% over CT2Rep, CT-CHAT, and Merlin for report generation; and it reduces FID by 75% and halves FVD compared to GenerateCT and MedSyn for text-to-CT synthesis, producing anatomically consistent 512*512*241 volumes. These results confirm that precise three-dimensional tokenization, rather than larger language backbones alone, is essential for scalable vision-language modeling in 3D medical imaging. The codebase is available at: https://github.com/ibrahimethemhamamci/BTB3D
SoundStream: An End-to-End Neural Audio Codec
We present SoundStream, a novel neural audio codec that can efficiently compress speech, music and general audio at bitrates normally targeted by speech-tailored codecs. SoundStream relies on a model architecture composed by a fully convolutional encoder/decoder network and a residual vector quantizer, which are trained jointly end-to-end. Training leverages recent advances in text-to-speech and speech enhancement, which combine adversarial and reconstruction losses to allow the generation of high-quality audio content from quantized embeddings. By training with structured dropout applied to quantizer layers, a single model can operate across variable bitrates from 3kbps to 18kbps, with a negligible quality loss when compared with models trained at fixed bitrates. In addition, the model is amenable to a low latency implementation, which supports streamable inference and runs in real time on a smartphone CPU. In subjective evaluations using audio at 24kHz sampling rate, SoundStream at 3kbps outperforms Opus at 12kbps and approaches EVS at 9.6kbps. Moreover, we are able to perform joint compression and enhancement either at the encoder or at the decoder side with no additional latency, which we demonstrate through background noise suppression for speech.

Synthetic Prior for Few-Shot Drivable Head Avatar Inversion
We present SynShot, a novel method for the few-shot inversion of a drivable head avatar based on a synthetic prior. We tackle two major challenges. First, training a controllable 3D generative network requires a large number of diverse sequences, for which pairs of images and high-quality tracked meshes are not always available. Second, state-of-the-art monocular avatar models struggle to generalize to new views and expressions, lacking a strong prior and often overfitting to a specific viewpoint distribution. Inspired by machine learning models trained solely on synthetic data, we propose a method that learns a prior model from a large dataset of synthetic heads with diverse identities, expressions, and viewpoints. With few input images, SynShot fine-tunes the pretrained synthetic prior to bridge the domain gap, modeling a photorealistic head avatar that generalizes to novel expressions and viewpoints. We model the head avatar using 3D Gaussian splatting and a convolutional encoder-decoder that outputs Gaussian parameters in UV texture space. To account for the different modeling complexities over parts of the head (e.g., skin vs hair), we embed the prior with explicit control for upsampling the number of per-part primitives. Compared to state-of-the-art monocular methods that require thousands of real training images, SynShot significantly improves novel view and expression synthesis.
Fine-tuning of Geospatial Foundation Models for Aboveground Biomass Estimation
Global vegetation structure mapping is critical for understanding the global carbon cycle and maximizing the efficacy of nature-based carbon sequestration initiatives. Moreover, vegetation structure mapping can help reduce the impacts of climate change by, for example, guiding actions to improve water security, increase biodiversity and reduce flood risk. Global satellite measurements provide an important set of observations for monitoring and managing deforestation and degradation of existing forests, natural forest regeneration, reforestation, biodiversity restoration, and the implementation of sustainable agricultural practices. In this paper, we explore the effectiveness of fine-tuning of a geospatial foundation model to estimate above-ground biomass (AGB) using space-borne data collected across different eco-regions in Brazil. The fine-tuned model architecture consisted of a Swin-B transformer as the encoder (i.e., backbone) and a single convolutional layer for the decoder head. All results were compared to a U-Net which was trained as the baseline model Experimental results of this sparse-label prediction task demonstrate that the fine-tuned geospatial foundation model with a frozen encoder has comparable performance to a U-Net trained from scratch. This is despite the fine-tuned model having 13 times less parameters requiring optimization, which saves both time and compute resources. Further, we explore the transfer-learning capabilities of the geospatial foundation models by fine-tuning on satellite imagery with sparse labels from different eco-regions in Brazil.

IAUNet: Instance-Aware U-Net
Instance segmentation is critical in biomedical imaging to accurately distinguish individual objects like cells, which often overlap and vary in size. Recent query-based methods, where object queries guide segmentation, have shown strong performance. While U-Net has been a go-to architecture in medical image segmentation, its potential in query-based approaches remains largely unexplored. In this work, we present IAUNet, a novel query-based U-Net architecture. The core design features a full U-Net architecture, enhanced by a novel lightweight convolutional Pixel decoder, making the model more efficient and reducing the number of parameters. Additionally, we propose a Transformer decoder that refines object-specific features across multiple scales. Finally, we introduce the 2025 Revvity Full Cell Segmentation Dataset, a unique resource with detailed annotations of overlapping cell cytoplasm in brightfield images, setting a new benchmark for biomedical instance segmentation. Experiments on multiple public datasets and our own show that IAUNet outperforms most state-of-the-art fully convolutional, transformer-based, and query-based models and cell segmentation-specific models, setting a strong baseline for cell instance segmentation tasks. Code is available at https://github.com/SlavkoPrytula/IAUNet




A Survey and Taxonomy of Adversarial Neural Networks for Text-to-Image Synthesis
Text-to-image synthesis refers to computational methods which translate human written textual descriptions, in the form of keywords or sentences, into images with similar semantic meaning to the text. In earlier research, image synthesis relied mainly on word to image correlation analysis combined with supervised methods to find best alignment of the visual content matching to the text. Recent progress in deep learning (DL) has brought a new set of unsupervised deep learning methods, particularly deep generative models which are able to generate realistic visual images using suitably trained neural network models. In this paper, we review the most recent development in the text-to-image synthesis research domain. Our survey first introduces image synthesis and its challenges, and then reviews key concepts such as generative adversarial networks (GANs) and deep convolutional encoder-decoder neural networks (DCNN). After that, we propose a taxonomy to summarize GAN based text-to-image synthesis into four major categories: Semantic Enhancement GANs, Resolution Enhancement GANs, Diversity Enhancement GANS, and Motion Enhancement GANs. We elaborate the main objective of each group, and further review typical GAN architectures in each group. The taxonomy and the review outline the techniques and the evolution of different approaches, and eventually provide a clear roadmap to summarize the list of contemporaneous solutions that utilize GANs and DCNNs to generate enthralling results in categories such as human faces, birds, flowers, room interiors, object reconstruction from edge maps (games) etc. The survey will conclude with a comparison of the proposed solutions, challenges that remain unresolved, and future developments in the text-to-image synthesis domain.
Semantic Segmentation of Underwater Imagery: Dataset and Benchmark
In this paper, we present the first large-scale dataset for semantic Segmentation of Underwater IMagery (SUIM). It contains over 1500 images with pixel annotations for eight object categories: fish (vertebrates), reefs (invertebrates), aquatic plants, wrecks/ruins, human divers, robots, and sea-floor. The images have been rigorously collected during oceanic explorations and human-robot collaborative experiments, and annotated by human participants. We also present a benchmark evaluation of state-of-the-art semantic segmentation approaches based on standard performance metrics. In addition, we present SUIM-Net, a fully-convolutional encoder-decoder model that balances the trade-off between performance and computational efficiency. It offers competitive performance while ensuring fast end-to-end inference, which is essential for its use in the autonomy pipeline of visually-guided underwater robots. In particular, we demonstrate its usability benefits for visual servoing, saliency prediction, and detailed scene understanding. With a variety of use cases, the proposed model and benchmark dataset open up promising opportunities for future research in underwater robot vision.
Stock Price Prediction Using CNN and LSTM-Based Deep Learning Models
Designing robust and accurate predictive models for stock price prediction has been an active area of research for a long time. While on one side, the supporters of the efficient market hypothesis claim that it is impossible to forecast stock prices accurately, many researchers believe otherwise. There exist propositions in the literature that have demonstrated that if properly designed and optimized, predictive models can very accurately and reliably predict future values of stock prices. This paper presents a suite of deep learning based models for stock price prediction. We use the historical records of the NIFTY 50 index listed in the National Stock Exchange of India, during the period from December 29, 2008 to July 31, 2020, for training and testing the models. Our proposition includes two regression models built on convolutional neural networks and three long and short term memory network based predictive models. To forecast the open values of the NIFTY 50 index records, we adopted a multi step prediction technique with walk forward validation. In this approach, the open values of the NIFTY 50 index are predicted on a time horizon of one week, and once a week is over, the actual index values are included in the training set before the model is trained again, and the forecasts for the next week are made. We present detailed results on the forecasting accuracies for all our proposed models. The results show that while all the models are very accurate in forecasting the NIFTY 50 open values, the univariate encoder decoder convolutional LSTM with the previous two weeks data as the input is the most accurate model. On the other hand, a univariate CNN model with previous one week data as the input is found to be the fastest model in terms of its execution speed.

SeqTR: A Simple yet Universal Network for Visual Grounding
In this paper, we propose a simple yet universal network termed SeqTR for visual grounding tasks, e.g., phrase localization, referring expression comprehension (REC) and segmentation (RES). The canonical paradigms for visual grounding often require substantial expertise in designing network architectures and loss functions, making them hard to generalize across tasks. To simplify and unify the modeling, we cast visual grounding as a point prediction problem conditioned on image and text inputs, where either the bounding box or binary mask is represented as a sequence of discrete coordinate tokens. Under this paradigm, visual grounding tasks are unified in our SeqTR network without task-specific branches or heads, e.g., the convolutional mask decoder for RES, which greatly reduces the complexity of multi-task modeling. In addition, SeqTR also shares the same optimization objective for all tasks with a simple cross-entropy loss, further reducing the complexity of deploying hand-crafted loss functions. Experiments on five benchmark datasets demonstrate that the proposed SeqTR outperforms (or is on par with) the existing state-of-the-arts, proving that a simple yet universal approach for visual grounding is indeed feasible. Source code is available at https://github.com/sean-zhuh/SeqTR.
Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting
In this paper, we propose two modified neural networks based on dual path multi-scale fusion networks (SFANet) and SegNet for accurate and efficient crowd counting. Inspired by SFANet, the first model, which is named M-SFANet, is attached with atrous spatial pyramid pooling (ASPP) and context-aware module (CAN). The encoder of M-SFANet is enhanced with ASPP containing parallel atrous convolutional layers with different sampling rates and hence able to extract multi-scale features of the target object and incorporate larger context. To further deal with scale variation throughout an input image, we leverage the CAN module which adaptively encodes the scales of the contextual information. The combination yields an effective model for counting in both dense and sparse crowd scenes. Based on the SFANet decoder structure, M-SFANet's decoder has dual paths, for density map and attention map generation. The second model is called M-SegNet, which is produced by replacing the bilinear upsampling in SFANet with max unpooling that is used in SegNet. This change provides a faster model while providing competitive counting performance. Designed for high-speed surveillance applications, M-SegNet has no additional multi-scale-aware module in order to not increase the complexity. Both models are encoder-decoder based architectures and are end-to-end trainable. We conduct extensive experiments on five crowd counting datasets and one vehicle counting dataset to show that these modifications yield algorithms that could improve state-of-the-art crowd counting methods. Codes are available at https://github.com/Pongpisit-Thanasutives/Variations-of-SFANet-for-Crowd-Counting.
What Do Single-view 3D Reconstruction Networks Learn?
Convolutional networks for single-view object reconstruction have shown impressive performance and have become a popular subject of research. All existing techniques are united by the idea of having an encoder-decoder network that performs non-trivial reasoning about the 3D structure of the output space. In this work, we set up two alternative approaches that perform image classification and retrieval respectively. These simple baselines yield better results than state-of-the-art methods, both qualitatively and quantitatively. We show that encoder-decoder methods are statistically indistinguishable from these baselines, thus indicating that the current state of the art in single-view object reconstruction does not actually perform reconstruction but image classification. We identify aspects of popular experimental procedures that elicit this behavior and discuss ways to improve the current state of research.
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization
Convolutional neural networks typically encode an input image into a series of intermediate features with decreasing resolutions. While this structure is suited to classification tasks, it does not perform well for tasks requiring simultaneous recognition and localization (e.g., object detection). The encoder-decoder architectures are proposed to resolve this by applying a decoder network onto a backbone model designed for classification tasks. In this paper, we argue encoder-decoder architecture is ineffective in generating strong multi-scale features because of the scale-decreased backbone. We propose SpineNet, a backbone with scale-permuted intermediate features and cross-scale connections that is learned on an object detection task by Neural Architecture Search. Using similar building blocks, SpineNet models outperform ResNet-FPN models by ~3% AP at various scales while using 10-20% fewer FLOPs. In particular, SpineNet-190 achieves 52.5% AP with a MaskR-CNN detector and achieves 52.1% AP with a RetinaNet detector on COCO for a single model without test-time augmentation, significantly outperforms prior art of detectors. SpineNet can transfer to classification tasks, achieving 5% top-1 accuracy improvement on a challenging iNaturalist fine-grained dataset. Code is at: https://github.com/tensorflow/tpu/tree/master/models/official/detection.
From Big to Small: Multi-Scale Local Planar Guidance for Monocular Depth Estimation
Estimating accurate depth from a single image is challenging because it is an ill-posed problem as infinitely many 3D scenes can be projected to the same 2D scene. However, recent works based on deep convolutional neural networks show great progress with plausible results. The convolutional neural networks are generally composed of two parts: an encoder for dense feature extraction and a decoder for predicting the desired depth. In the encoder-decoder schemes, repeated strided convolution and spatial pooling layers lower the spatial resolution of transitional outputs, and several techniques such as skip connections or multi-layer deconvolutional networks are adopted to recover the original resolution for effective dense prediction. In this paper, for more effective guidance of densely encoded features to the desired depth prediction, we propose a network architecture that utilizes novel local planar guidance layers located at multiple stages in the decoding phase. We show that the proposed method outperforms the state-of-the-art works with significant margin evaluating on challenging benchmarks. We also provide results from an ablation study to validate the effectiveness of the proposed method.
Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-Sequence Prediction
Current state-of-the-art machine translation systems are based on encoder-decoder architectures, that first encode the input sequence, and then generate an output sequence based on the input encoding. Both are interfaced with an attention mechanism that recombines a fixed encoding of the source tokens based on the decoder state. We propose an alternative approach which instead relies on a single 2D convolutional neural network across both sequences. Each layer of our network re-codes source tokens on the basis of the output sequence produced so far. Attention-like properties are therefore pervasive throughout the network. Our model yields excellent results, outperforming state-of-the-art encoder-decoder systems, while being conceptually simpler and having fewer parameters.

Rethinking the Inception Architecture for Computer Vision
Convolutional networks are at the core of most state-of-the-art computer vision solutions for a wide variety of tasks. Since 2014 very deep convolutional networks started to become mainstream, yielding substantial gains in various benchmarks. Although increased model size and computational cost tend to translate to immediate quality gains for most tasks (as long as enough labeled data is provided for training), computational efficiency and low parameter count are still enabling factors for various use cases such as mobile vision and big-data scenarios. Here we explore ways to scale up networks in ways that aim at utilizing the added computation as efficiently as possible by suitably factorized convolutions and aggressive regularization. We benchmark our methods on the ILSVRC 2012 classification challenge validation set demonstrate substantial gains over the state of the art: 21.2% top-1 and 5.6% top-5 error for single frame evaluation using a network with a computational cost of 5 billion multiply-adds per inference and with using less than 25 million parameters. With an ensemble of 4 models and multi-crop evaluation, we report 3.5% top-5 error on the validation set (3.6% error on the test set) and 17.3% top-1 error on the validation set.
Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling
We identify and overcome two key obstacles in extending the success of BERT-style pre-training, or the masked image modeling, to convolutional networks (convnets): (i) convolution operation cannot handle irregular, random-masked input images; (ii) the single-scale nature of BERT pre-training is inconsistent with convnet's hierarchical structure. For (i), we treat unmasked pixels as sparse voxels of 3D point clouds and use sparse convolution to encode. This is the first use of sparse convolution for 2D masked modeling. For (ii), we develop a hierarchical decoder to reconstruct images from multi-scale encoded features. Our method called Sparse masKed modeling (SparK) is general: it can be used directly on any convolutional model without backbone modifications. We validate it on both classical (ResNet) and modern (ConvNeXt) models: on three downstream tasks, it surpasses both state-of-the-art contrastive learning and transformer-based masked modeling by similarly large margins (around +1.0%). Improvements on object detection and instance segmentation are more substantial (up to +3.5%), verifying the strong transferability of features learned. We also find its favorable scaling behavior by observing more gains on larger models. All this evidence reveals a promising future of generative pre-training on convnets. Codes and models are released at https://github.com/keyu-tian/SparK.

Contextual Encoder-Decoder Network for Visual Saliency Prediction
Predicting salient regions in natural images requires the detection of objects that are present in a scene. To develop robust representations for this challenging task, high-level visual features at multiple spatial scales must be extracted and augmented with contextual information. However, existing models aimed at explaining human fixation maps do not incorporate such a mechanism explicitly. Here we propose an approach based on a convolutional neural network pre-trained on a large-scale image classification task. The architecture forms an encoder-decoder structure and includes a module with multiple convolutional layers at different dilation rates to capture multi-scale features in parallel. Moreover, we combine the resulting representations with global scene information for accurately predicting visual saliency. Our model achieves competitive and consistent results across multiple evaluation metrics on two public saliency benchmarks and we demonstrate the effectiveness of the suggested approach on five datasets and selected examples. Compared to state of the art approaches, the network is based on a lightweight image classification backbone and hence presents a suitable choice for applications with limited computational resources, such as (virtual) robotic systems, to estimate human fixations across complex natural scenes.
Very Deep Convolutional Networks for Large-Scale Image Recognition
In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16-19 weight layers. These findings were the basis of our ImageNet Challenge 2014 submission, where our team secured the first and the second places in the localisation and classification tracks respectively. We also show that our representations generalise well to other datasets, where they achieve state-of-the-art results. We have made our two best-performing ConvNet models publicly available to facilitate further research on the use of deep visual representations in computer vision.
Convolutional Occupancy Networks
Recently, implicit neural representations have gained popularity for learning-based 3D reconstruction. While demonstrating promising results, most implicit approaches are limited to comparably simple geometry of single objects and do not scale to more complicated or large-scale scenes. The key limiting factor of implicit methods is their simple fully-connected network architecture which does not allow for integrating local information in the observations or incorporating inductive biases such as translational equivariance. In this paper, we propose Convolutional Occupancy Networks, a more flexible implicit representation for detailed reconstruction of objects and 3D scenes. By combining convolutional encoders with implicit occupancy decoders, our model incorporates inductive biases, enabling structured reasoning in 3D space. We investigate the effectiveness of the proposed representation by reconstructing complex geometry from noisy point clouds and low-resolution voxel representations. We empirically find that our method enables the fine-grained implicit 3D reconstruction of single objects, scales to large indoor scenes, and generalizes well from synthetic to real data.


Task-Optimized Convolutional Recurrent Networks Align with Tactile Processing in the Rodent Brain
Tactile sensing remains far less understood in neuroscience and less effective in artificial systems compared to more mature modalities such as vision and language. We bridge these gaps by introducing a novel Encoder-Attender-Decoder (EAD) framework to systematically explore the space of task-optimized temporal neural networks trained on realistic tactile input sequences from a customized rodent whisker-array simulator. We identify convolutional recurrent neural networks (ConvRNNs) as superior encoders to purely feedforward and state-space architectures for tactile categorization. Crucially, these ConvRNN-encoder-based EAD models achieve neural representations closely matching rodent somatosensory cortex, saturating the explainable neural variability and revealing a clear linear relationship between supervised categorization performance and neural alignment. Furthermore, contrastive self-supervised ConvRNN-encoder-based EADs, trained with tactile-specific augmentations, match supervised neural fits, serving as an ethologically-relevant, label-free proxy. For neuroscience, our findings highlight nonlinear recurrent processing as important for general-purpose tactile representations in somatosensory cortex, providing the first quantitative characterization of the underlying inductive biases in this system. For embodied AI, our results emphasize the importance of recurrent EAD architectures to handle realistic tactile inputs, along with tailored self-supervised learning methods for achieving robust tactile perception with the same type of sensors animals use to sense in unstructured environments.

MEDUSA: Multi-scale Encoder-Decoder Self-Attention Deep Neural Network Architecture for Medical Image Analysis
Medical image analysis continues to hold interesting challenges given the subtle characteristics of certain diseases and the significant overlap in appearance between diseases. In this work, we explore the concept of self-attention for tackling such subtleties in and between diseases. To this end, we introduce MEDUSA, a multi-scale encoder-decoder self-attention mechanism tailored for medical image analysis. While self-attention deep convolutional neural network architectures in existing literature center around the notion of multiple isolated lightweight attention mechanisms with limited individual capacities being incorporated at different points in the network architecture, MEDUSA takes a significant departure from this notion by possessing a single, unified self-attention mechanism with significantly higher capacity with multiple attention heads feeding into different scales in the network architecture. To the best of the authors' knowledge, this is the first "single body, multi-scale heads" realization of self-attention and enables explicit global context amongst selective attention at different levels of representational abstractions while still enabling differing local attention context at individual levels of abstractions. With MEDUSA, we obtain state-of-the-art performance on multiple challenging medical image analysis benchmarks including COVIDx, RSNA RICORD, and RSNA Pneumonia Challenge when compared to previous work. Our MEDUSA model is publicly available.
Conditional Image Generation with PixelCNN Decoders
This work explores conditional image generation with a new image density model based on the PixelCNN architecture. The model can be conditioned on any vector, including descriptive labels or tags, or latent embeddings created by other networks. When conditioned on class labels from the ImageNet database, the model is able to generate diverse, realistic scenes representing distinct animals, objects, landscapes and structures. When conditioned on an embedding produced by a convolutional network given a single image of an unseen face, it generates a variety of new portraits of the same person with different facial expressions, poses and lighting conditions. We also show that conditional PixelCNN can serve as a powerful decoder in an image autoencoder. Additionally, the gated convolutional layers in the proposed model improve the log-likelihood of PixelCNN to match the state-of-the-art performance of PixelRNN on ImageNet, with greatly reduced computational cost.
Neural Machine Translation in Linear Time
We present a novel neural network for processing sequences. The ByteNet is a one-dimensional convolutional neural network that is composed of two parts, one to encode the source sequence and the other to decode the target sequence. The two network parts are connected by stacking the decoder on top of the encoder and preserving the temporal resolution of the sequences. To address the differing lengths of the source and the target, we introduce an efficient mechanism by which the decoder is dynamically unfolded over the representation of the encoder. The ByteNet uses dilation in the convolutional layers to increase its receptive field. The resulting network has two core properties: it runs in time that is linear in the length of the sequences and it sidesteps the need for excessive memorization. The ByteNet decoder attains state-of-the-art performance on character-level language modelling and outperforms the previous best results obtained with recurrent networks. The ByteNet also achieves state-of-the-art performance on character-to-character machine translation on the English-to-German WMT translation task, surpassing comparable neural translation models that are based on recurrent networks with attentional pooling and run in quadratic time. We find that the latent alignment structure contained in the representations reflects the expected alignment between the tokens.
Hybrid graph convolutional neural networks for landmark-based anatomical segmentation
In this work we address the problem of landmark-based segmentation for anatomical structures. We propose HybridGNet, an encoder-decoder neural architecture which combines standard convolutions for image feature encoding, with graph convolutional neural networks to decode plausible representations of anatomical structures. We benchmark the proposed architecture considering other standard landmark and pixel-based models for anatomical segmentation in chest x-ray images, and found that HybridGNet is more robust to image occlusions. We also show that it can be used to construct landmark-based segmentations from pixel level annotations. Our experimental results suggest that HybridGNet produces accurate and anatomically plausible landmark-based segmentations, by naturally incorporating shape constraints within the decoding process via spectral convolutions.


MEGConformer: Conformer-Based MEG Decoder for Robust Speech and Phoneme Classification
We present Conformer-based decoders for the LibriBrain 2025 PNPL competition, targeting two foundational MEG tasks: Speech Detection and Phoneme Classification. Our approach adapts a compact Conformer to raw 306-channel MEG signals, with a lightweight convolutional projection layer and task-specific heads. For Speech Detection, a MEG-oriented SpecAugment provided a first exploration of MEG-specific augmentation. For Phoneme Classification, we used inverse-square-root class weighting and a dynamic grouping loader to handle 100-sample averaged examples. In addition, a simple instance-level normalization proved critical to mitigate distribution shifts on the holdout split. Using the official Standard track splits and F1-macro for model selection, our best systems achieved 88.9% (Speech) and 65.8% (Phoneme) on the leaderboard, surpassing the competition baselines and ranking within the top-10 in both tasks. For further implementation details, the technical documentation, source code, and checkpoints are available at https://github.com/neural2speech/libribrain-experiments.

On the Properties of Neural Machine Translation: Encoder-Decoder Approaches
Neural machine translation is a relatively new approach to statistical machine translation based purely on neural networks. The neural machine translation models often consist of an encoder and a decoder. The encoder extracts a fixed-length representation from a variable-length input sentence, and the decoder generates a correct translation from this representation. In this paper, we focus on analyzing the properties of the neural machine translation using two models; RNN Encoder--Decoder and a newly proposed gated recursive convolutional neural network. We show that the neural machine translation performs relatively well on short sentences without unknown words, but its performance degrades rapidly as the length of the sentence and the number of unknown words increase. Furthermore, we find that the proposed gated recursive convolutional network learns a grammatical structure of a sentence automatically.
CRISP: Curriculum based Sequential Neural Decoders for Polar Code Family
Polar codes are widely used state-of-the-art codes for reliable communication that have recently been included in the 5th generation wireless standards (5G). However, there remains room for the design of polar decoders that are both efficient and reliable in the short blocklength regime. Motivated by recent successes of data-driven channel decoders, we introduce a novel CurRIculum based Sequential neural decoder for Polar codes (CRISP). We design a principled curriculum, guided by information-theoretic insights, to train CRISP and show that it outperforms the successive-cancellation (SC) decoder and attains near-optimal reliability performance on the Polar(32,16) and Polar(64,22) codes. The choice of the proposed curriculum is critical in achieving the accuracy gains of CRISP, as we show by comparing against other curricula. More notably, CRISP can be readily extended to Polarization-Adjusted-Convolutional (PAC) codes, where existing SC decoders are significantly less reliable. To the best of our knowledge, CRISP constructs the first data-driven decoder for PAC codes and attains near-optimal performance on the PAC(32,16) code.


MLP-Mixer: An all-MLP Architecture for Vision
Convolutional Neural Networks (CNNs) are the go-to model for computer vision. Recently, attention-based networks, such as the Vision Transformer, have also become popular. In this paper we show that while convolutions and attention are both sufficient for good performance, neither of them are necessary. We present MLP-Mixer, an architecture based exclusively on multi-layer perceptrons (MLPs). MLP-Mixer contains two types of layers: one with MLPs applied independently to image patches (i.e. "mixing" the per-location features), and one with MLPs applied across patches (i.e. "mixing" spatial information). When trained on large datasets, or with modern regularization schemes, MLP-Mixer attains competitive scores on image classification benchmarks, with pre-training and inference cost comparable to state-of-the-art models. We hope that these results spark further research beyond the realms of well established CNNs and Transformers.


Planing It by Ear: Convolutional Neural Networks for Acoustic Anomaly Detection in Industrial Wood Planers
In recent years, the wood product industry has been facing a skilled labor shortage. The result is more frequent sudden failures, resulting in additional costs for these companies already operating in a very competitive market. Moreover, sawmills are challenging environments for machinery and sensors. Given that experienced machine operators may be able to diagnose defects or malfunctions, one possible way of assisting novice operators is through acoustic monitoring. As a step towards the automation of wood-processing equipment and decision support systems for machine operators, in this paper, we explore using a deep convolutional autoencoder for acoustic anomaly detection of wood planers on a new real-life dataset. Specifically, our convolutional autoencoder with skip connections (Skip-CAE) and our Skip-CAE transformer outperform the DCASE autoencoder baseline, one-class SVM, isolation forest and a published convolutional autoencoder architecture, respectively obtaining an area under the ROC curve of 0.846 and 0.875 on a dataset of real-factory planer sounds. Moreover, we show that adding skip connections and attention mechanism under the form of a transformer encoder-decoder helps to further improve the anomaly detection capabilities.
HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions
Recent progress in vision Transformers exhibits great success in various tasks driven by the new spatial modeling mechanism based on dot-product self-attention. In this paper, we show that the key ingredients behind the vision Transformers, namely input-adaptive, long-range and high-order spatial interactions, can also be efficiently implemented with a convolution-based framework. We present the Recursive Gated Convolution (g^nConv) that performs high-order spatial interactions with gated convolutions and recursive designs. The new operation is highly flexible and customizable, which is compatible with various variants of convolution and extends the two-order interactions in self-attention to arbitrary orders without introducing significant extra computation. g^nConv can serve as a plug-and-play module to improve various vision Transformers and convolution-based models. Based on the operation, we construct a new family of generic vision backbones named HorNet. Extensive experiments on ImageNet classification, COCO object detection and ADE20K semantic segmentation show HorNet outperform Swin Transformers and ConvNeXt by a significant margin with similar overall architecture and training configurations. HorNet also shows favorable scalability to more training data and larger model sizes. Apart from the effectiveness in visual encoders, we also show g^nConv can be applied to task-specific decoders and consistently improve dense prediction performance with less computation. Our results demonstrate that g^nConv can be a new basic module for visual modeling that effectively combines the merits of both vision Transformers and CNNs. Code is available at https://github.com/raoyongming/HorNet

Modeling Relational Data with Graph Convolutional Networks
Knowledge graphs enable a wide variety of applications, including question answering and information retrieval. Despite the great effort invested in their creation and maintenance, even the largest (e.g., Yago, DBPedia or Wikidata) remain incomplete. We introduce Relational Graph Convolutional Networks (R-GCNs) and apply them to two standard knowledge base completion tasks: Link prediction (recovery of missing facts, i.e. subject-predicate-object triples) and entity classification (recovery of missing entity attributes). R-GCNs are related to a recent class of neural networks operating on graphs, and are developed specifically to deal with the highly multi-relational data characteristic of realistic knowledge bases. We demonstrate the effectiveness of R-GCNs as a stand-alone model for entity classification. We further show that factorization models for link prediction such as DistMult can be significantly improved by enriching them with an encoder model to accumulate evidence over multiple inference steps in the relational graph, demonstrating a large improvement of 29.8% on FB15k-237 over a decoder-only baseline.

Evaluating Sequence-to-Sequence Models for Handwritten Text Recognition
Encoder-decoder models have become an effective approach for sequence learning tasks like machine translation, image captioning and speech recognition, but have yet to show competitive results for handwritten text recognition. To this end, we propose an attention-based sequence-to-sequence model. It combines a convolutional neural network as a generic feature extractor with a recurrent neural network to encode both the visual information, as well as the temporal context between characters in the input image, and uses a separate recurrent neural network to decode the actual character sequence. We make experimental comparisons between various attention mechanisms and positional encodings, in order to find an appropriate alignment between the input and output sequence. The model can be trained end-to-end and the optional integration of a hybrid loss allows the encoder to retain an interpretable and usable output, if desired. We achieve competitive results on the IAM and ICFHR2016 READ data sets compared to the state-of-the-art without the use of a language model, and we significantly improve over any recent sequence-to-sequence approaches.
DecoderLens: Layerwise Interpretation of Encoder-Decoder Transformers
In recent years, many interpretability methods have been proposed to help interpret the internal states of Transformer-models, at different levels of precision and complexity. Here, to analyze encoder-decoder Transformers, we propose a simple, new method: DecoderLens. Inspired by the LogitLens (for decoder-only Transformers), this method involves allowing the decoder to cross-attend representations of intermediate encoder layers instead of using the final encoder output, as is normally done in encoder-decoder models. The method thus maps previously uninterpretable vector representations to human-interpretable sequences of words or symbols. We report results from the DecoderLens applied to models trained on question answering, logical reasoning, speech recognition and machine translation. The DecoderLens reveals several specific subtasks that are solved at low or intermediate layers, shedding new light on the information flow inside the encoder component of this important class of models.

A Thorough Examination of Decoding Methods in the Era of LLMs
Decoding methods play an indispensable role in converting language models from next-token predictors into practical task solvers. Prior research on decoding methods, primarily focusing on task-specific models, may not extend to the current era of general-purpose large language models (LLMs). Moreover, the recent influx of decoding strategies has further complicated this landscape. This paper provides a comprehensive and multifaceted analysis of various decoding methods within the context of LLMs, evaluating their performance, robustness to hyperparameter changes, and decoding speeds across a wide range of tasks, models, and deployment environments. Our findings reveal that decoding method performance is notably task-dependent and influenced by factors such as alignment, model size, and quantization. Intriguingly, sensitivity analysis exposes that certain methods achieve superior performance at the cost of extensive hyperparameter tuning, highlighting the trade-off between attaining optimal results and the practicality of implementation in varying contexts.
Fully Convolutional Networks for Semantic Segmentation
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, improve on the previous best result in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional network achieves improved segmentation of PASCAL VOC (30% relative improvement to 67.2% mean IU on 2012), NYUDv2, SIFT Flow, and PASCAL-Context, while inference takes one tenth of a second for a typical image.
Efficient Purely Convolutional Text Encoding
In this work, we focus on a lightweight convolutional architecture that creates fixed-size vector embeddings of sentences. Such representations are useful for building NLP systems, including conversational agents. Our work derives from a recently proposed recursive convolutional architecture for auto-encoding text paragraphs at byte level. We propose alternations that significantly reduce training time, the number of parameters, and improve auto-encoding accuracy. Finally, we evaluate the representations created by our model on tasks from SentEval benchmark suite, and show that it can serve as a better, yet fairly low-resource alternative to popular bag-of-words embeddings.

Striving for Simplicity: The All Convolutional Net
Most modern convolutional neural networks (CNNs) used for object recognition are built using the same principles: Alternating convolution and max-pooling layers followed by a small number of fully connected layers. We re-evaluate the state of the art for object recognition from small images with convolutional networks, questioning the necessity of different components in the pipeline. We find that max-pooling can simply be replaced by a convolutional layer with increased stride without loss in accuracy on several image recognition benchmarks. Following this finding -- and building on other recent work for finding simple network structures -- we propose a new architecture that consists solely of convolutional layers and yields competitive or state of the art performance on several object recognition datasets (CIFAR-10, CIFAR-100, ImageNet). To analyze the network we introduce a new variant of the "deconvolution approach" for visualizing features learned by CNNs, which can be applied to a broader range of network structures than existing approaches.
RelationNet++: Bridging Visual Representations for Object Detection via Transformer Decoder
Existing object detection frameworks are usually built on a single format of object/part representation, i.e., anchor/proposal rectangle boxes in RetinaNet and Faster R-CNN, center points in FCOS and RepPoints, and corner points in CornerNet. While these different representations usually drive the frameworks to perform well in different aspects, e.g., better classification or finer localization, it is in general difficult to combine these representations in a single framework to make good use of each strength, due to the heterogeneous or non-grid feature extraction by different representations. This paper presents an attention-based decoder module similar as that in Transformer~vaswani2017attention to bridge other representations into a typical object detector built on a single representation format, in an end-to-end fashion. The other representations act as a set of key instances to strengthen the main query representation features in the vanilla detectors. Novel techniques are proposed towards efficient computation of the decoder module, including a key sampling approach and a shared location embedding approach. The proposed module is named bridging visual representations (BVR). It can perform in-place and we demonstrate its broad effectiveness in bridging other representations into prevalent object detection frameworks, including RetinaNet, Faster R-CNN, FCOS and ATSS, where about 1.5sim3.0 AP improvements are achieved. In particular, we improve a state-of-the-art framework with a strong backbone by about 2.0 AP, reaching 52.7 AP on COCO test-dev. The resulting network is named RelationNet++. The code will be available at https://github.com/microsoft/RelationNet2.

Object Recognition as Next Token Prediction
We present an approach to pose object recognition as next token prediction. The idea is to apply a language decoder that auto-regressively predicts the text tokens from image embeddings to form labels. To ground this prediction process in auto-regression, we customize a non-causal attention mask for the decoder, incorporating two key features: modeling tokens from different labels to be independent, and treating image tokens as a prefix. This masking mechanism inspires an efficient method - one-shot sampling - to simultaneously sample tokens of multiple labels in parallel and rank generated labels by their probabilities during inference. To further enhance the efficiency, we propose a simple strategy to construct a compact decoder by simply discarding the intermediate blocks of a pretrained language model. This approach yields a decoder that matches the full model's performance while being notably more efficient. The code is available at https://github.com/kaiyuyue/nxtp




Toward Lightweight and Fast Decoders for Diffusion Models in Image and Video Generation
We investigate methods to reduce inference time and memory footprint in stable diffusion models by introducing lightweight decoders for both image and video synthesis. Traditional latent diffusion pipelines rely on large Variational Autoencoder decoders that can slow down generation and consume considerable GPU memory. We propose custom-trained decoders using lightweight Vision Transformer and Taming Transformer architectures. Experiments show up to 15% overall speed-ups for image generation on COCO2017 and up to 20 times faster decoding in the sub-module, with additional gains on UCF-101 for video tasks. Memory requirements are moderately reduced, and while there is a small drop in perceptual quality compared to the default decoder, the improvements in speed and scalability are crucial for large-scale inference scenarios such as generating 100K images. Our work is further contextualized by advances in efficient video generation, including dual masking strategies, illustrating a broader effort to improve the scalability and efficiency of generative models.

Inceptive Transformers: Enhancing Contextual Representations through Multi-Scale Feature Learning Across Domains and Languages
Encoder transformer models compress information from all tokens in a sequence into a single [CLS] token to represent global context. This approach risks diluting fine-grained or hierarchical features, leading to information loss in downstream tasks where local patterns are important. To remedy this, we propose a lightweight architectural enhancement: an inception-style 1-D convolution module that sits on top of the transformer layer and augments token representations with multi-scale local features. This enriched feature space is then processed by a self-attention layer that dynamically weights tokens based on their task relevance. Experiments on five diverse tasks show that our framework consistently improves general-purpose, domain-specific, and multilingual models, outperforming baselines by 1% to 14% while maintaining efficiency. Ablation studies show that multi-scale convolution performs better than any single kernel and that the self-attention layer is critical for performance.
Pay Less Attention with Lightweight and Dynamic Convolutions
Self-attention is a useful mechanism to build generative models for language and images. It determines the importance of context elements by comparing each element to the current time step. In this paper, we show that a very lightweight convolution can perform competitively to the best reported self-attention results. Next, we introduce dynamic convolutions which are simpler and more efficient than self-attention. We predict separate convolution kernels based solely on the current time-step in order to determine the importance of context elements. The number of operations required by this approach scales linearly in the input length, whereas self-attention is quadratic. Experiments on large-scale machine translation, language modeling and abstractive summarization show that dynamic convolutions improve over strong self-attention models. On the WMT'14 English-German test set dynamic convolutions achieve a new state of the art of 29.7 BLEU.

Dense Transformer Networks
The key idea of current deep learning methods for dense prediction is to apply a model on a regular patch centered on each pixel to make pixel-wise predictions. These methods are limited in the sense that the patches are determined by network architecture instead of learned from data. In this work, we propose the dense transformer networks, which can learn the shapes and sizes of patches from data. The dense transformer networks employ an encoder-decoder architecture, and a pair of dense transformer modules are inserted into each of the encoder and decoder paths. The novelty of this work is that we provide technical solutions for learning the shapes and sizes of patches from data and efficiently restoring the spatial correspondence required for dense prediction. The proposed dense transformer modules are differentiable, thus the entire network can be trained. We apply the proposed networks on natural and biological image segmentation tasks and show superior performance is achieved in comparison to baseline methods.
Patches Are All You Need?
Although convolutional networks have been the dominant architecture for vision tasks for many years, recent experiments have shown that Transformer-based models, most notably the Vision Transformer (ViT), may exceed their performance in some settings. However, due to the quadratic runtime of the self-attention layers in Transformers, ViTs require the use of patch embeddings, which group together small regions of the image into single input features, in order to be applied to larger image sizes. This raises a question: Is the performance of ViTs due to the inherently-more-powerful Transformer architecture, or is it at least partly due to using patches as the input representation? In this paper, we present some evidence for the latter: specifically, we propose the ConvMixer, an extremely simple model that is similar in spirit to the ViT and the even-more-basic MLP-Mixer in that it operates directly on patches as input, separates the mixing of spatial and channel dimensions, and maintains equal size and resolution throughout the network. In contrast, however, the ConvMixer uses only standard convolutions to achieve the mixing steps. Despite its simplicity, we show that the ConvMixer outperforms the ViT, MLP-Mixer, and some of their variants for similar parameter counts and data set sizes, in addition to outperforming classical vision models such as the ResNet. Our code is available at https://github.com/locuslab/convmixer.
SpaRTAN: Spatial Reinforcement Token-based Aggregation Network for Visual Recognition
The resurgence of convolutional neural networks (CNNs) in visual recognition tasks, exemplified by ConvNeXt, has demonstrated their capability to rival transformer-based architectures through advanced training methodologies and ViT-inspired design principles. However, both CNNs and transformers exhibit a simplicity bias, favoring straightforward features over complex structural representations. Furthermore, modern CNNs often integrate MLP-like blocks akin to those in transformers, but these blocks suffer from significant information redundancies, necessitating high expansion ratios to sustain competitive performance. To address these limitations, we propose SpaRTAN, a lightweight architectural design that enhances spatial and channel-wise information processing. SpaRTAN employs kernels with varying receptive fields, controlled by kernel size and dilation factor, to capture discriminative multi-order spatial features effectively. A wave-based channel aggregation module further modulates and reinforces pixel interactions, mitigating channel-wise redundancies. Combining the two modules, the proposed network can efficiently gather and dynamically contextualize discriminative features. Experimental results in ImageNet and COCO demonstrate that SpaRTAN achieves remarkable parameter efficiency while maintaining competitive performance. In particular, on the ImageNet-1k benchmark, SpaRTAN achieves 77. 7% accuracy with only 3.8M parameters and approximately 1.0 GFLOPs, demonstrating its ability to deliver strong performance through an efficient design. On the COCO benchmark, it achieves 50.0% AP, surpassing the previous benchmark by 1.2% with only 21.5M parameters. The code is publicly available at [https://github.com/henry-pay/SpaRTAN].
Understanding Deep Image Representations by Inverting Them
Image representations, from SIFT and Bag of Visual Words to Convolutional Neural Networks (CNNs), are a crucial component of almost any image understanding system. Nevertheless, our understanding of them remains limited. In this paper we conduct a direct analysis of the visual information contained in representations by asking the following question: given an encoding of an image, to which extent is it possible to reconstruct the image itself? To answer this question we contribute a general framework to invert representations. We show that this method can invert representations such as HOG and SIFT more accurately than recent alternatives while being applicable to CNNs too. We then use this technique to study the inverse of recent state-of-the-art CNN image representations for the first time. Among our findings, we show that several layers in CNNs retain photographically accurate information about the image, with different degrees of geometric and photometric invariance.
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
We present SegFormer, a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with lightweight multilayer perception (MLP) decoders. SegFormer has two appealing features: 1) SegFormer comprises a novel hierarchically structured Transformer encoder which outputs multiscale features. It does not need positional encoding, thereby avoiding the interpolation of positional codes which leads to decreased performance when the testing resolution differs from training. 2) SegFormer avoids complex decoders. The proposed MLP decoder aggregates information from different layers, and thus combining both local attention and global attention to render powerful representations. We show that this simple and lightweight design is the key to efficient segmentation on Transformers. We scale our approach up to obtain a series of models from SegFormer-B0 to SegFormer-B5, reaching significantly better performance and efficiency than previous counterparts. For example, SegFormer-B4 achieves 50.3% mIoU on ADE20K with 64M parameters, being 5x smaller and 2.2% better than the previous best method. Our best model, SegFormer-B5, achieves 84.0% mIoU on Cityscapes validation set and shows excellent zero-shot robustness on Cityscapes-C. Code will be released at: github.com/NVlabs/SegFormer.

SPANet: Frequency-balancing Token Mixer using Spectral Pooling Aggregation Modulation
Recent studies show that self-attentions behave like low-pass filters (as opposed to convolutions) and enhancing their high-pass filtering capability improves model performance. Contrary to this idea, we investigate existing convolution-based models with spectral analysis and observe that improving the low-pass filtering in convolution operations also leads to performance improvement. To account for this observation, we hypothesize that utilizing optimal token mixers that capture balanced representations of both high- and low-frequency components can enhance the performance of models. We verify this by decomposing visual features into the frequency domain and combining them in a balanced manner. To handle this, we replace the balancing problem with a mask filtering problem in the frequency domain. Then, we introduce a novel token-mixer named SPAM and leverage it to derive a MetaFormer model termed as SPANet. Experimental results show that the proposed method provides a way to achieve this balance, and the balanced representations of both high- and low-frequency components can improve the performance of models on multiple computer vision tasks. Our code is available at https://doranlyong.github.io/projects/spanet/{https://doranlyong.github.io/projects/spanet/}.
CBAM: Convolutional Block Attention Module
We propose Convolutional Block Attention Module (CBAM), a simple yet effective attention module for feed-forward convolutional neural networks. Given an intermediate feature map, our module sequentially infers attention maps along two separate dimensions, channel and spatial, then the attention maps are multiplied to the input feature map for adaptive feature refinement. Because CBAM is a lightweight and general module, it can be integrated into any CNN architectures seamlessly with negligible overheads and is end-to-end trainable along with base CNNs. We validate our CBAM through extensive experiments on ImageNet-1K, MS~COCO detection, and VOC~2007 detection datasets. Our experiments show consistent improvements in classification and detection performances with various models, demonstrating the wide applicability of CBAM. The code and models will be publicly available.

A Novel Transformer Based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images
The fully convolutional network (FCN) with an encoder-decoder architecture has been the standard paradigm for semantic segmentation. The encoder-decoder architecture utilizes an encoder to capture multilevel feature maps, which are incorporated into the final prediction by a decoder. As the context is crucial for precise segmentation, tremendous effort has been made to extract such information in an intelligent fashion, including employing dilated/atrous convolutions or inserting attention modules. However, these endeavors are all based on the FCN architecture with ResNet or other backbones, which cannot fully exploit the context from the theoretical concept. By contrast, we introduce the Swin Transformer as the backbone to extract the context information and design a novel decoder of densely connected feature aggregation module (DCFAM) to restore the resolution and produce the segmentation map. The experimental results on two remotely sensed semantic segmentation datasets demonstrate the effectiveness of the proposed scheme.Code is available at https://github.com/WangLibo1995/GeoSeg
Discrete Key-Value Bottleneck
Deep neural networks perform well on classification tasks where data streams are i.i.d. and labeled data is abundant. Challenges emerge with non-stationary training data streams such as continual learning. One powerful approach that has addressed this challenge involves pre-training of large encoders on volumes of readily available data, followed by task-specific tuning. Given a new task, however, updating the weights of these encoders is challenging as a large number of weights needs to be fine-tuned, and as a result, they forget information about the previous tasks. In the present work, we propose a model architecture to address this issue, building upon a discrete bottleneck containing pairs of separate and learnable key-value codes. Our paradigm will be to encode; process the representation via a discrete bottleneck; and decode. Here, the input is fed to the pre-trained encoder, the output of the encoder is used to select the nearest keys, and the corresponding values are fed to the decoder to solve the current task. The model can only fetch and re-use a sparse number of these key-value pairs during inference, enabling localized and context-dependent model updates. We theoretically investigate the ability of the discrete key-value bottleneck to minimize the effect of learning under distribution shifts and show that it reduces the complexity of the hypothesis class. We empirically verify the proposed method under challenging class-incremental learning scenarios and show that the proposed model - without any task boundaries - reduces catastrophic forgetting across a wide variety of pre-trained models, outperforming relevant baselines on this task.
RecursiveDet: End-to-End Region-based Recursive Object Detection
End-to-end region-based object detectors like Sparse R-CNN usually have multiple cascade bounding box decoding stages, which refine the current predictions according to their previous results. Model parameters within each stage are independent, evolving a huge cost. In this paper, we find the general setting of decoding stages is actually redundant. By simply sharing parameters and making a recursive decoder, the detector already obtains a significant improvement. The recursive decoder can be further enhanced by positional encoding (PE) of the proposal box, which makes it aware of the exact locations and sizes of input bounding boxes, thus becoming adaptive to proposals from different stages during the recursion. Moreover, we also design centerness-based PE to distinguish the RoI feature element and dynamic convolution kernels at different positions within the bounding box. To validate the effectiveness of the proposed method, we conduct intensive ablations and build the full model on three recent mainstream region-based detectors. The RecusiveDet is able to achieve obvious performance boosts with even fewer model parameters and slightly increased computation cost. Codes are available at https://github.com/bravezzzzzz/RecursiveDet.
Fully Convolutional Networks for Semantic Segmentation
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build "fully convolutional" networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a novel architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional network achieves state-of-the-art segmentation of PASCAL VOC (20% relative improvement to 62.2% mean IU on 2012), NYUDv2, and SIFT Flow, while inference takes one third of a second for a typical image.
Deconvolutional Paragraph Representation Learning
Learning latent representations from long text sequences is an important first step in many natural language processing applications. Recurrent Neural Networks (RNNs) have become a cornerstone for this challenging task. However, the quality of sentences during RNN-based decoding (reconstruction) decreases with the length of the text. We propose a sequence-to-sequence, purely convolutional and deconvolutional autoencoding framework that is free of the above issue, while also being computationally efficient. The proposed method is simple, easy to implement and can be leveraged as a building block for many applications. We show empirically that compared to RNNs, our framework is better at reconstructing and correcting long paragraphs. Quantitative evaluation on semi-supervised text classification and summarization tasks demonstrate the potential for better utilization of long unlabeled text data.

White-Box Transformers via Sparse Rate Reduction
In this paper, we contend that the objective of representation learning is to compress and transform the distribution of the data, say sets of tokens, towards a mixture of low-dimensional Gaussian distributions supported on incoherent subspaces. The quality of the final representation can be measured by a unified objective function called sparse rate reduction. From this perspective, popular deep networks such as transformers can be naturally viewed as realizing iterative schemes to optimize this objective incrementally. Particularly, we show that the standard transformer block can be derived from alternating optimization on complementary parts of this objective: the multi-head self-attention operator can be viewed as a gradient descent step to compress the token sets by minimizing their lossy coding rate, and the subsequent multi-layer perceptron can be viewed as attempting to sparsify the representation of the tokens. This leads to a family of white-box transformer-like deep network architectures which are mathematically fully interpretable. Despite their simplicity, experiments show that these networks indeed learn to optimize the designed objective: they compress and sparsify representations of large-scale real-world vision datasets such as ImageNet, and achieve performance very close to thoroughly engineered transformers such as ViT. Code is at https://github.com/Ma-Lab-Berkeley/CRATE.




High-Performance Neural Networks for Visual Object Classification
We present a fast, fully parameterizable GPU implementation of Convolutional Neural Network variants. Our feature extractors are neither carefully designed nor pre-wired, but rather learned in a supervised way. Our deep hierarchical architectures achieve the best published results on benchmarks for object classification (NORB, CIFAR10) and handwritten digit recognition (MNIST), with error rates of 2.53%, 19.51%, 0.35%, respectively. Deep nets trained by simple back-propagation perform better than more shallow ones. Learning is surprisingly rapid. NORB is completely trained within five epochs. Test error rates on MNIST drop to 2.42%, 0.97% and 0.48% after 1, 3 and 17 epochs, respectively.
Recent Advances in Convolutional Neural Networks
In the last few years, deep learning has led to very good performance on a variety of problems, such as visual recognition, speech recognition and natural language processing. Among different types of deep neural networks, convolutional neural networks have been most extensively studied. Leveraging on the rapid growth in the amount of the annotated data and the great improvements in the strengths of graphics processor units, the research on convolutional neural networks has been emerged swiftly and achieved state-of-the-art results on various tasks. In this paper, we provide a broad survey of the recent advances in convolutional neural networks. We detailize the improvements of CNN on different aspects, including layer design, activation function, loss function, regularization, optimization and fast computation. Besides, we also introduce various applications of convolutional neural networks in computer vision, speech and natural language processing.
Laughing Hyena Distillery: Extracting Compact Recurrences From Convolutions
Recent advances in attention-free sequence models rely on convolutions as alternatives to the attention operator at the core of Transformers. In particular, long convolution sequence models have achieved state-of-the-art performance in many domains, but incur a significant cost during auto-regressive inference workloads -- naively requiring a full pass (or caching of activations) over the input sequence for each generated token -- similarly to attention-based models. In this paper, we seek to enable mathcal O(1) compute and memory cost per token in any pre-trained long convolution architecture to reduce memory footprint and increase throughput during generation. Concretely, our methods consist in extracting low-dimensional linear state-space models from each convolution layer, building upon rational interpolation and model-order reduction techniques. We further introduce architectural improvements to convolution-based layers such as Hyena: by weight-tying the filters across channels into heads, we achieve higher pre-training quality and reduce the number of filters to be distilled. The resulting model achieves 10x higher throughput than Transformers and 1.5x higher than Hyena at 1.3B parameters, without any loss in quality after distillation.



Design of Efficient Convolutional Layers using Single Intra-channel Convolution, Topological Subdivisioning and Spatial "Bottleneck" Structure
Deep convolutional neural networks achieve remarkable visual recognition performance, at the cost of high computational complexity. In this paper, we have a new design of efficient convolutional layers based on three schemes. The 3D convolution operation in a convolutional layer can be considered as performing spatial convolution in each channel and linear projection across channels simultaneously. By unravelling them and arranging the spatial convolution sequentially, the proposed layer is composed of a single intra-channel convolution, of which the computation is negligible, and a linear channel projection. A topological subdivisioning is adopted to reduce the connection between the input channels and output channels. Additionally, we also introduce a spatial "bottleneck" structure that utilizes a convolution-projection-deconvolution pipeline to take advantage of the correlation between adjacent pixels in the input. Our experiments demonstrate that the proposed layers remarkably outperform the standard convolutional layers with regard to accuracy/complexity ratio. Our models achieve similar accuracy to VGG, ResNet-50, ResNet-101 while requiring 42, 4.5, 6.5 times less computation respectively.
Deep Learning Applied to Image and Text Matching
The ability to describe images with natural language sentences is the hallmark for image and language understanding. Such a system has wide ranging applications such as annotating images and using natural sentences to search for images.In this project we focus on the task of bidirectional image retrieval: such asystem is capable of retrieving an image based on a sentence (image search) andretrieve sentence based on an image query (image annotation). We present asystem based on a global ranking objective function which uses a combinationof convolutional neural networks (CNN) and multi layer perceptrons (MLP).It takes a pair of image and sentence and processes them in different channels,finally embedding it into a common multimodal vector space. These embeddingsencode abstract semantic information about the two inputs and can be comparedusing traditional information retrieval approaches. For each such pair, the modelreturns a score which is interpretted as a similarity metric. If this score is high,the image and sentence are likely to convey similar meaning, and if the score is low then they are likely not to. The visual input is modeled via deep convolutional neural network. On theother hand we explore three models for the textual module. The first one isbag of words with an MLP. The second one uses n-grams (bigram, trigrams,and a combination of trigram & skip-grams) with an MLP. The third is morespecialized deep network specific for modeling variable length sequences (SSE).We report comparable performance to recent work in the field, even though ouroverall model is simpler. We also show that the training time choice of how wecan generate our negative samples has a significant impact on performance, and can be used to specialize the bi-directional system in one particular task.
A Tour of Convolutional Networks Guided by Linear Interpreters
Convolutional networks are large linear systems divided into layers and connected by non-linear units. These units are the "articulations" that allow the network to adapt to the input. To understand how a network manages to solve a problem we must look at the articulated decisions in entirety. If we could capture the actions of non-linear units for a particular input, we would be able to replay the whole system back and forth as if it was always linear. It would also reveal the actions of non-linearities because the resulting linear system, a Linear Interpreter, depends on the input image. We introduce a hooking layer, called a LinearScope, which allows us to run the network and the linear interpreter in parallel. Its implementation is simple, flexible and efficient. From here we can make many curious inquiries: how do these linear systems look like? When the rows and columns of the transformation matrix are images, how do they look like? What type of basis do these linear transformations rely on? The answers depend on the problems presented, through which we take a tour to some popular architectures used for classification, super-resolution (SR) and image-to-image translation (I2I). For classification we observe that popular networks use a pixel-wise vote per class strategy and heavily rely on bias parameters. For SR and I2I we find that CNNs use wavelet-type basis similar to the human visual system. For I2I we reveal copy-move and template-creation strategies to generate outputs.

Interpret Vision Transformers as ConvNets with Dynamic Convolutions
There has been a debate about the superiority between vision Transformers and ConvNets, serving as the backbone of computer vision models. Although they are usually considered as two completely different architectures, in this paper, we interpret vision Transformers as ConvNets with dynamic convolutions, which enables us to characterize existing Transformers and dynamic ConvNets in a unified framework and compare their design choices side by side. In addition, our interpretation can also guide the network design as researchers now can consider vision Transformers from the design space of ConvNets and vice versa. We demonstrate such potential through two specific studies. First, we inspect the role of softmax in vision Transformers as the activation function and find it can be replaced by commonly used ConvNets modules, such as ReLU and Layer Normalization, which results in a faster convergence rate and better performance. Second, following the design of depth-wise convolution, we create a corresponding depth-wise vision Transformer that is more efficient with comparable performance. The potential of the proposed unified interpretation is not limited to the given examples and we hope it can inspire the community and give rise to more advanced network architectures.

Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring
The use of deep pre-trained bidirectional transformers has led to remarkable progress in a number of applications (Devlin et al., 2018). For tasks that make pairwise comparisons between sequences, matching a given input with a corresponding label, two approaches are common: Cross-encoders performing full self-attention over the pair and Bi-encoders encoding the pair separately. The former often performs better, but is too slow for practical use. In this work, we develop a new transformer architecture, the Poly-encoder, that learns global rather than token level self-attention features. We perform a detailed comparison of all three approaches, including what pre-training and fine-tuning strategies work best. We show our models achieve state-of-the-art results on three existing tasks; that Poly-encoders are faster than Cross-encoders and more accurate than Bi-encoders; and that the best results are obtained by pre-training on large datasets similar to the downstream tasks.
Involution: Inverting the Inherence of Convolution for Visual Recognition
Convolution has been the core ingredient of modern neural networks, triggering the surge of deep learning in vision. In this work, we rethink the inherent principles of standard convolution for vision tasks, specifically spatial-agnostic and channel-specific. Instead, we present a novel atomic operation for deep neural networks by inverting the aforementioned design principles of convolution, coined as involution. We additionally demystify the recent popular self-attention operator and subsume it into our involution family as an over-complicated instantiation. The proposed involution operator could be leveraged as fundamental bricks to build the new generation of neural networks for visual recognition, powering different deep learning models on several prevalent benchmarks, including ImageNet classification, COCO detection and segmentation, together with Cityscapes segmentation. Our involution-based models improve the performance of convolutional baselines using ResNet-50 by up to 1.6% top-1 accuracy, 2.5% and 2.4% bounding box AP, and 4.7% mean IoU absolutely while compressing the computational cost to 66%, 65%, 72%, and 57% on the above benchmarks, respectively. Code and pre-trained models for all the tasks are available at https://github.com/d-li14/involution.

A Study of Autoregressive Decoders for Multi-Tasking in Computer Vision
There has been a recent explosion of computer vision models which perform many tasks and are composed of an image encoder (usually a ViT) and an autoregressive decoder (usually a Transformer). However, most of this work simply presents one system and its results, leaving many questions regarding design decisions and trade-offs of such systems unanswered. In this work, we aim to provide such answers. We take a close look at autoregressive decoders for multi-task learning in multimodal computer vision, including classification, captioning, visual question answering, and optical character recognition. Through extensive systematic experiments, we study the effects of task and data mixture, training and regularization hyperparameters, conditioning type and specificity, modality combination, and more. Importantly, we compare these to well-tuned single-task baselines to highlight the cost incurred by multi-tasking. A key finding is that a small decoder learned on top of a frozen pretrained encoder works surprisingly well. We call this setup locked-image tuning with decoder (LiT-decoder). It can be seen as teaching a decoder to interact with a pretrained vision model via natural language.
A priori compression of convolutional neural networks for wave simulators
Convolutional neural networks are now seeing widespread use in a variety of fields, including image classification, facial and object recognition, medical imaging analysis, and many more. In addition, there are applications such as physics-informed simulators in which accurate forecasts in real time with a minimal lag are required. The present neural network designs include millions of parameters, which makes it difficult to install such complex models on devices that have limited memory. Compression techniques might be able to resolve these issues by decreasing the size of CNN models that are created by reducing the number of parameters that contribute to the complexity of the models. We propose a compressed tensor format of convolutional layer, a priori, before the training of the neural network. 3-way kernels or 2-way kernels in convolutional layers are replaced by one-way fiters. The overfitting phenomena will be reduced also. The time needed to make predictions or time required for training using the original Convolutional Neural Networks model would be cut significantly if there were fewer parameters to deal with. In this paper we present a method of a priori compressing convolutional neural networks for finite element (FE) predictions of physical data. Afterwards we validate our a priori compressed models on physical data from a FE model solving a 2D wave equation. We show that the proposed convolutinal compression technique achieves equivalent performance as classical convolutional layers with fewer trainable parameters and lower memory footprint.

Seq vs Seq: An Open Suite of Paired Encoders and Decoders
The large language model (LLM) community focuses almost exclusively on decoder-only language models, since they are easier to use for text generation. However, a large subset of the community still uses encoder-only models for tasks such as classification or retrieval. Previous work has attempted to compare these architectures, but is forced to make comparisons with models that have different numbers of parameters, training techniques, and datasets. We introduce the SOTA open-data Ettin suite of models: paired encoder-only and decoder-only models ranging from 17 million parameters to 1 billion, trained on up to 2 trillion tokens. Using the same recipe for both encoder-only and decoder-only models produces SOTA recipes in both categories for their respective sizes, beating ModernBERT as an encoder and Llama 3.2 and SmolLM2 as decoders. Like previous work, we find that encoder-only models excel at classification and retrieval tasks while decoders excel at generative tasks. However, we show that adapting a decoder model to encoder tasks (and vice versa) through continued training is subpar compared to using only the reverse objective (i.e. a 400M encoder outperforms a 1B decoder on MNLI, and vice versa for generative tasks). We open-source all artifacts of this study including training data, training order segmented by checkpoint, and 200+ checkpoints to allow future work to analyze or extend all aspects of training.


Blockwise Parallel Decoding for Deep Autoregressive Models
Deep autoregressive sequence-to-sequence models have demonstrated impressive performance across a wide variety of tasks in recent years. While common architecture classes such as recurrent, convolutional, and self-attention networks make different trade-offs between the amount of computation needed per layer and the length of the critical path at training time, generation still remains an inherently sequential process. To overcome this limitation, we propose a novel blockwise parallel decoding scheme in which we make predictions for multiple time steps in parallel then back off to the longest prefix validated by a scoring model. This allows for substantial theoretical improvements in generation speed when applied to architectures that can process output sequences in parallel. We verify our approach empirically through a series of experiments using state-of-the-art self-attention models for machine translation and image super-resolution, achieving iteration reductions of up to 2x over a baseline greedy decoder with no loss in quality, or up to 7x in exchange for a slight decrease in performance. In terms of wall-clock time, our fastest models exhibit real-time speedups of up to 4x over standard greedy decoding.
Generalized Decoding for Pixel, Image, and Language
We present X-Decoder, a generalized decoding model that can predict pixel-level segmentation and language tokens seamlessly. X-Decodert takes as input two types of queries: (i) generic non-semantic queries and (ii) semantic queries induced from text inputs, to decode different pixel-level and token-level outputs in the same semantic space. With such a novel design, X-Decoder is the first work that provides a unified way to support all types of image segmentation and a variety of vision-language (VL) tasks. Further, our design enables seamless interactions across tasks at different granularities and brings mutual benefits by learning a common and rich pixel-level visual-semantic understanding space, without any pseudo-labeling. After pretraining on a mixed set of a limited amount of segmentation data and millions of image-text pairs, X-Decoder exhibits strong transferability to a wide range of downstream tasks in both zero-shot and finetuning settings. Notably, it achieves (1) state-of-the-art results on open-vocabulary segmentation and referring segmentation on eight datasets; (2) better or competitive finetuned performance to other generalist and specialist models on segmentation and VL tasks; and (3) flexibility for efficient finetuning and novel task composition (e.g., referring captioning and image editing). Code, demo, video, and visualization are available at https://x-decoder-vl.github.io.


Is Pre-training Applicable to the Decoder for Dense Prediction?
Pre-trained encoders are widely employed in dense prediction tasks for their capability to effectively extract visual features from images. The decoder subsequently processes these features to generate pixel-level predictions. However, due to structural differences and variations in input data, only encoders benefit from pre-learned representations from vision benchmarks such as image classification and self-supervised learning, while decoders are typically trained from scratch. In this paper, we introduce timesNet, which facilitates a "pre-trained encoder times pre-trained decoder" collaboration through three innovative designs. timesNet enables the direct utilization of pre-trained models within the decoder, integrating pre-learned representations into the decoding process to enhance performance in dense prediction tasks. By simply coupling the pre-trained encoder and pre-trained decoder, timesNet distinguishes itself as a highly promising approach. Remarkably, it achieves this without relying on decoding-specific structures or task-specific algorithms. Despite its streamlined design, timesNet outperforms advanced methods in tasks such as monocular depth estimation and semantic segmentation, achieving state-of-the-art performance particularly in monocular depth estimation. and semantic segmentation, achieving state-of-the-art results, especially in monocular depth estimation. embedding algorithms. Despite its streamlined design, timesNet outperforms advanced methods in tasks such as monocular depth estimation and semantic segmentation, achieving state-of-the-art performance particularly in monocular depth estimation.
Squeeze-and-Excitation Networks
The central building block of convolutional neural networks (CNNs) is the convolution operator, which enables networks to construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer. A broad range of prior research has investigated the spatial component of this relationship, seeking to strengthen the representational power of a CNN by enhancing the quality of spatial encodings throughout its feature hierarchy. In this work, we focus instead on the channel relationship and propose a novel architectural unit, which we term the "Squeeze-and-Excitation" (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels. We show that these blocks can be stacked together to form SENet architectures that generalise extremely effectively across different datasets. We further demonstrate that SE blocks bring significant improvements in performance for existing state-of-the-art CNNs at slight additional computational cost. Squeeze-and-Excitation Networks formed the foundation of our ILSVRC 2017 classification submission which won first place and reduced the top-5 error to 2.251%, surpassing the winning entry of 2016 by a relative improvement of ~25%. Models and code are available at https://github.com/hujie-frank/SENet.
Attention is All You Need? Good Embeddings with Statistics are enough:Large Scale Audio Understanding without Transformers/ Convolutions/ BERTs/ Mixers/ Attention/ RNNs or ....
This paper presents a way of doing large scale audio understanding without traditional state of the art neural architectures. Ever since the introduction of deep learning for understanding audio signals in the past decade, convolutional architectures have been able to achieve state of the art results surpassing traditional hand-crafted features. In the recent past, there has been a similar shift away from traditional convolutional and recurrent neural networks towards purely end-to-end Transformer architectures. We, in this work, explore an approach, based on Bag-of-Words model. Our approach does not have any convolutions, recurrence, attention, transformers or other approaches such as BERT. We utilize micro and macro level clustered vanilla embeddings, and use a MLP head for classification. We only use feed-forward encoder-decoder models to get the bottlenecks of spectral envelops, spectral patches and slices as well as multi-resolution spectra. A classification head (a feed-forward layer), similar to the approach in SimCLR is trained on a learned representation. Using simple codes learned on latent representations, we show how we surpass traditional convolutional neural network architectures, and come strikingly close to outperforming powerful Transformer architectures. This work hopefully would pave way for exciting advancements in the field of representation learning without massive, end-to-end neural architectures.

Scaling Up Your Kernels: Large Kernel Design in ConvNets towards Universal Representations
This paper proposes the paradigm of large convolutional kernels in designing modern Convolutional Neural Networks (ConvNets). We establish that employing a few large kernels, instead of stacking multiple smaller ones, can be a superior design strategy. Our work introduces a set of architecture design guidelines for large-kernel ConvNets that optimize their efficiency and performance. We propose the UniRepLKNet architecture, which offers systematical architecture design principles specifically crafted for large-kernel ConvNets, emphasizing their unique ability to capture extensive spatial information without deep layer stacking. This results in a model that not only surpasses its predecessors with an ImageNet accuracy of 88.0%, an ADE20K mIoU of 55.6%, and a COCO box AP of 56.4% but also demonstrates impressive scalability and performance on various modalities such as time-series forecasting, audio, point cloud, and video recognition. These results indicate the universal modeling abilities of large-kernel ConvNets with faster inference speed compared with vision transformers. Our findings reveal that large-kernel ConvNets possess larger effective receptive fields and a higher shape bias, moving away from the texture bias typical of smaller-kernel CNNs. All codes and models are publicly available at https://github.com/AILab-CVC/UniRepLKNet promoting further research and development in the community.



Are Decoder-Only Large Language Models the Silver Bullet for Code Search?
Code search is crucial for code reuse, enabling developers to efficiently locate relevant snippets. Current methods rely on encoder-based models, which suffer from limitations such as poor generalization and restricted input lengths. Decoder-only large language models (LLMs), with their extensive pre-training, larger size, and longer input capabilities, offer potential solutions to these issues, yet their effectiveness in code search remains underexplored. To fill this gap, our study presents the first systematic exploration of decoder-only LLMs for code search. We evaluate nine state-of-the-art decoder-only models using two fine-tuning methods, two datasets (CSN and CoSQA^+), and three model sizes. Our findings reveal that fine-tuned CodeGemma significantly outperforms encoder-only models like UniXcoder, achieving a 5.57% improvement in MRR on CSN and a 49.6% increase in MAP on CoSQA^+ compared to zero-shot UniXcoder. These results highlight the superior performance and adaptability of decoder-only models. Additionally, we provide valuable insights into optimizing these models for code search, covering aspects such as model selection, fine-tuning methods, training data, and model size, and discussing their strengths and limitations.
Building a Safer Maritime Environment Through Multi-Path Long-Term Vessel Trajectory Forecasting
Maritime transportation is paramount in achieving global economic growth, entailing concurrent ecological obligations in sustainability and safeguarding endangered marine species, most notably preserving large whale populations. In this regard, the Automatic Identification System (AIS) data plays a significant role by offering real-time streaming data on vessel movement, allowing enhanced traffic monitoring. This study explores using AIS data to prevent vessel-to-whale collisions by forecasting long-term vessel trajectories from engineered AIS data sequences. For such a task, we have developed an encoder-decoder model architecture using Bidirectional Long Short-Term Memory Networks (Bi-LSTM) to predict the next 12 hours of vessel trajectories using 1 to 3 hours of AIS data as input. We feed the model with probabilistic features engineered from historical AIS data that refer to each trajectory's potential route and destination. The model then predicts the vessel's trajectory, considering these additional features by leveraging convolutional layers for spatial feature learning and a position-aware attention mechanism that increases the importance of recent timesteps of a sequence during temporal feature learning. The probabilistic features have an F1 Score of approximately 85% and 75% for each feature type, respectively, demonstrating their effectiveness in augmenting information to the neural network. We test our model on the Gulf of St. Lawrence, a region known to be the habitat of North Atlantic Right Whales (NARW). Our model achieved a high R2 score of over 98% using various techniques and features. It stands out among other approaches as it can make complex decisions during turnings and path selection. Our study highlights the potential of data engineering and trajectory forecasting models for marine life species preservation.
RECALL: Rehearsal-free Continual Learning for Object Classification
Convolutional neural networks show remarkable results in classification but struggle with learning new things on the fly. We present a novel rehearsal-free approach, where a deep neural network is continually learning new unseen object categories without saving any data of prior sequences. Our approach is called RECALL, as the network recalls categories by calculating logits for old categories before training new ones. These are then used during training to avoid changing the old categories. For each new sequence, a new head is added to accommodate the new categories. To mitigate forgetting, we present a regularization strategy where we replace the classification with a regression. Moreover, for the known categories, we propose a Mahalanobis loss that includes the variances to account for the changing densities between known and unknown categories. Finally, we present a novel dataset for continual learning, especially suited for object recognition on a mobile robot (HOWS-CL-25), including 150,795 synthetic images of 25 household object categories. Our approach RECALL outperforms the current state of the art on CORe50 and iCIFAR-100 and reaches the best performance on HOWS-CL-25.

SMPConv: Self-moving Point Representations for Continuous Convolution
Continuous convolution has recently gained prominence due to its ability to handle irregularly sampled data and model long-term dependency. Also, the promising experimental results of using large convolutional kernels have catalyzed the development of continuous convolution since they can construct large kernels very efficiently. Leveraging neural networks, more specifically multilayer perceptrons (MLPs), is by far the most prevalent approach to implementing continuous convolution. However, there are a few drawbacks, such as high computational costs, complex hyperparameter tuning, and limited descriptive power of filters. This paper suggests an alternative approach to building a continuous convolution without neural networks, resulting in more computationally efficient and improved performance. We present self-moving point representations where weight parameters freely move, and interpolation schemes are used to implement continuous functions. When applied to construct convolutional kernels, the experimental results have shown improved performance with drop-in replacement in the existing frameworks. Due to its lightweight structure, we are first to demonstrate the effectiveness of continuous convolution in a large-scale setting, e.g., ImageNet, presenting the improvements over the prior arts. Our code is available on https://github.com/sangnekim/SMPConv

BigCodec: Pushing the Limits of Low-Bitrate Neural Speech Codec
We present BigCodec, a low-bitrate neural speech codec. While recent neural speech codecs have shown impressive progress, their performance significantly deteriorates at low bitrates (around 1 kbps). Although a low bitrate inherently restricts performance, other factors, such as model capacity, also hinder further improvements. To address this problem, we scale up the model size to 159M parameters that is more than 10 times larger than popular codecs with about 10M parameters. Besides, we integrate sequential models into traditional convolutional architectures to better capture temporal dependency and adopt low-dimensional vector quantization to ensure a high code utilization. Comprehensive objective and subjective evaluations show that BigCodec, with a bitrate of 1.04 kbps, significantly outperforms several existing low-bitrate codecs. Furthermore, BigCodec achieves objective performance comparable to popular codecs operating at 4-6 times higher bitrates, and even delivers better subjective perceptual quality than the ground truth.
TransNeXt: Robust Foveal Visual Perception for Vision Transformers
Due to the depth degradation effect in residual connections, many efficient Vision Transformers models that rely on stacking layers for information exchange often fail to form sufficient information mixing, leading to unnatural visual perception. To address this issue, in this paper, we propose Aggregated Attention, a biomimetic design-based token mixer that simulates biological foveal vision and continuous eye movement while enabling each token on the feature map to have a global perception. Furthermore, we incorporate learnable tokens that interact with conventional queries and keys, which further diversifies the generation of affinity matrices beyond merely relying on the similarity between queries and keys. Our approach does not rely on stacking for information exchange, thus effectively avoiding depth degradation and achieving natural visual perception. Additionally, we propose Convolutional GLU, a channel mixer that bridges the gap between GLU and SE mechanism, which empowers each token to have channel attention based on its nearest neighbor image features, enhancing local modeling capability and model robustness. We combine aggregated attention and convolutional GLU to create a new visual backbone called TransNeXt. Extensive experiments demonstrate that our TransNeXt achieves state-of-the-art performance across multiple model sizes. At a resolution of 224^2, TransNeXt-Tiny attains an ImageNet accuracy of 84.0%, surpassing ConvNeXt-B with 69% fewer parameters. Our TransNeXt-Base achieves an ImageNet accuracy of 86.2% and an ImageNet-A accuracy of 61.6% at a resolution of 384^2, a COCO object detection mAP of 57.1, and an ADE20K semantic segmentation mIoU of 54.7.

Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
Most recent semantic segmentation methods adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract/semantic visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated/atrous convolutions or inserting attention modules. However, the encoder-decoder based FCN architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating semantic segmentation as a sequence-to-sequence prediction task. Specifically, we deploy a pure transformer (ie, without convolution and resolution reduction) to encode an image as a sequence of patches. With the global context modeled in every layer of the transformer, this encoder can be combined with a simple decoder to provide a powerful segmentation model, termed SEgmentation TRansformer (SETR). Extensive experiments show that SETR achieves new state of the art on ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU) and competitive results on Cityscapes. Particularly, we achieve the first position in the highly competitive ADE20K test server leaderboard on the day of submission.

DANIEL: A fast Document Attention Network for Information Extraction and Labelling of handwritten documents
Information extraction from handwritten documents involves traditionally three distinct steps: Document Layout Analysis, Handwritten Text Recognition, and Named Entity Recognition. Recent approaches have attempted to integrate these steps into a single process using fully end-to-end architectures. Despite this, these integrated approaches have not yet matched the performance of language models, when applied to information extraction in plain text. In this paper, we introduce DANIEL (Document Attention Network for Information Extraction and Labelling), a fully end-to-end architecture integrating a language model and designed for comprehensive handwritten document understanding. DANIEL performs layout recognition, handwriting recognition, and named entity recognition on full-page documents. Moreover, it can simultaneously learn across multiple languages, layouts, and tasks. For named entity recognition, the ontology to be applied can be specified via the input prompt. The architecture employs a convolutional encoder capable of processing images of any size without resizing, paired with an autoregressive decoder based on a transformer-based language model. DANIEL achieves competitive results on four datasets, including a new state-of-the-art performance on RIMES 2009 and M-POPP for Handwriting Text Recognition, and IAM NER for Named Entity Recognition. Furthermore, DANIEL is much faster than existing approaches. We provide the source code and the weights of the trained models at https://github.com/Shulk97/daniel.

TransMatting: Enhancing Transparent Objects Matting with Transformers
Image matting refers to predicting the alpha values of unknown foreground areas from natural images. Prior methods have focused on propagating alpha values from known to unknown regions. However, not all natural images have a specifically known foreground. Images of transparent objects, like glass, smoke, web, etc., have less or no known foreground. In this paper, we propose a Transformer-based network, TransMatting, to model transparent objects with a big receptive field. Specifically, we redesign the trimap as three learnable tri-tokens for introducing advanced semantic features into the self-attention mechanism. A small convolutional network is proposed to utilize the global feature and non-background mask to guide the multi-scale feature propagation from encoder to decoder for maintaining the contexture of transparent objects. In addition, we create a high-resolution matting dataset of transparent objects with small known foreground areas. Experiments on several matting benchmarks demonstrate the superiority of our proposed method over the current state-of-the-art methods.

Locally-Focused Face Representation for Sketch-to-Image Generation Using Noise-Induced Refinement
This paper presents a novel deep-learning framework that significantly enhances the transformation of rudimentary face sketches into high-fidelity colour images. Employing a Convolutional Block Attention-based Auto-encoder Network (CA2N), our approach effectively captures and enhances critical facial features through a block attention mechanism within an encoder-decoder architecture. Subsequently, the framework utilises a noise-induced conditional Generative Adversarial Network (cGAN) process that allows the system to maintain high performance even on domains unseen during the training. These enhancements lead to considerable improvements in image realism and fidelity, with our model achieving superior performance metrics that outperform the best method by FID margin of 17, 23, and 38 on CelebAMask-HQ, CUHK, and CUFSF datasets; respectively. The model sets a new state-of-the-art in sketch-to-image generation, can generalize across sketch types, and offers a robust solution for applications such as criminal identification in law enforcement.
CTRAN: CNN-Transformer-based Network for Natural Language Understanding
Intent-detection and slot-filling are the two main tasks in natural language understanding. In this study, we propose CTRAN, a novel encoder-decoder CNN-Transformer-based architecture for intent-detection and slot-filling. In the encoder, we use BERT, followed by several convolutional layers, and rearrange the output using window feature sequence. We use stacked Transformer encoders after the window feature sequence. For the intent-detection decoder, we utilize self-attention followed by a linear layer. In the slot-filling decoder, we introduce the aligned Transformer decoder, which utilizes a zero diagonal mask, aligning output tags with input tokens. We apply our network on ATIS and SNIPS, and surpass the current state-of-the-art in slot-filling on both datasets. Furthermore, we incorporate the language model as word embeddings, and show that this strategy yields a better result when compared to the language model as an encoder.

Variational Graph Auto-Encoders
We introduce the variational graph auto-encoder (VGAE), a framework for unsupervised learning on graph-structured data based on the variational auto-encoder (VAE). This model makes use of latent variables and is capable of learning interpretable latent representations for undirected graphs. We demonstrate this model using a graph convolutional network (GCN) encoder and a simple inner product decoder. Our model achieves competitive results on a link prediction task in citation networks. In contrast to most existing models for unsupervised learning on graph-structured data and link prediction, our model can naturally incorporate node features, which significantly improves predictive performance on a number of benchmark datasets.
Convolutional Neural Network Architectures for Matching Natural Language Sentences
Semantic matching is of central importance to many natural language tasks bordes2014semantic,RetrievalQA. A successful matching algorithm needs to adequately model the internal structures of language objects and the interaction between them. As a step toward this goal, we propose convolutional neural network models for matching two sentences, by adapting the convolutional strategy in vision and speech. The proposed models not only nicely represent the hierarchical structures of sentences with their layer-by-layer composition and pooling, but also capture the rich matching patterns at different levels. Our models are rather generic, requiring no prior knowledge on language, and can hence be applied to matching tasks of different nature and in different languages. The empirical study on a variety of matching tasks demonstrates the efficacy of the proposed model on a variety of matching tasks and its superiority to competitor models.
Decoding at the Speed of Thought: Harnessing Parallel Decoding of Lexical Units for LLMs
Large language models have demonstrated exceptional capability in natural language understanding and generation. However, their generation speed is limited by the inherently sequential nature of their decoding process, posing challenges for real-time applications. This paper introduces Lexical Unit Decoding (LUD), a novel decoding methodology implemented in a data-driven manner, accelerating the decoding process without sacrificing output quality. The core of our approach is the observation that a pre-trained language model can confidently predict multiple contiguous tokens, forming the basis for a lexical unit, in which these contiguous tokens could be decoded in parallel. Extensive experiments validate that our method substantially reduces decoding time while maintaining generation quality, i.e., 33\% speed up on natural language generation with no quality loss, and 30\% speed up on code generation with a negligible quality loss of 3\%. Distinctively, LUD requires no auxiliary models and does not require changes to existing architectures. It can also be integrated with other decoding acceleration methods, thus achieving an even more pronounced inference efficiency boost. We posit that the foundational principles of LUD could define a new decoding paradigm for future language models, enhancing their applicability for a broader spectrum of applications. All codes are be publicly available at https://github.com/tjunlp-lab/Lexical-Unit-Decoding-LUD-. Keywords: Parallel Decoding, Lexical Unit Decoding, Large Language Model

Neural Networks as Explicit Word-Based Rules
Filters of convolutional networks used in computer vision are often visualized as image patches that maximize the response of the filter. We use the same approach to interpret weight matrices in simple architectures for natural language processing tasks. We interpret a convolutional network for sentiment classification as word-based rules. Using the rule, we recover the performance of the original model.

What Makes Convolutional Models Great on Long Sequence Modeling?
Convolutional models have been widely used in multiple domains. However, most existing models only use local convolution, making the model unable to handle long-range dependency efficiently. Attention overcomes this problem by aggregating global information but also makes the computational complexity quadratic to the sequence length. Recently, Gu et al. [2021] proposed a model called S4 inspired by the state space model. S4 can be efficiently implemented as a global convolutional model whose kernel size equals the input sequence length. S4 can model much longer sequences than Transformers and achieve significant gains over SoTA on several long-range tasks. Despite its empirical success, S4 is involved. It requires sophisticated parameterization and initialization schemes. As a result, S4 is less intuitive and hard to use. Here we aim to demystify S4 and extract basic principles that contribute to the success of S4 as a global convolutional model. We focus on the structure of the convolution kernel and identify two critical but intuitive principles enjoyed by S4 that are sufficient to make up an effective global convolutional model: 1) The parameterization of the convolutional kernel needs to be efficient in the sense that the number of parameters should scale sub-linearly with sequence length. 2) The kernel needs to satisfy a decaying structure that the weights for convolving with closer neighbors are larger than the more distant ones. Based on the two principles, we propose a simple yet effective convolutional model called Structured Global Convolution (SGConv). SGConv exhibits strong empirical performance over several tasks: 1) With faster speed, SGConv surpasses S4 on Long Range Arena and Speech Command datasets. 2) When plugging SGConv into standard language and vision models, it shows the potential to improve both efficiency and performance.
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.



Rescoring Sequence-to-Sequence Models for Text Line Recognition with CTC-Prefixes
In contrast to Connectionist Temporal Classification (CTC) approaches, Sequence-To-Sequence (S2S) models for Handwritten Text Recognition (HTR) suffer from errors such as skipped or repeated words which often occur at the end of a sequence. In this paper, to combine the best of both approaches, we propose to use the CTC-Prefix-Score during S2S decoding. Hereby, during beam search, paths that are invalid according to the CTC confidence matrix are penalised. Our network architecture is composed of a Convolutional Neural Network (CNN) as visual backbone, bidirectional Long-Short-Term-Memory-Cells (LSTMs) as encoder, and a decoder which is a Transformer with inserted mutual attention layers. The CTC confidences are computed on the encoder while the Transformer is only used for character-wise S2S decoding. We evaluate this setup on three HTR data sets: IAM, Rimes, and StAZH. On IAM, we achieve a competitive Character Error Rate (CER) of 2.95% when pretraining our model on synthetic data and including a character-based language model for contemporary English. Compared to other state-of-the-art approaches, our model requires about 10-20 times less parameters. Access our shared implementations via this link to GitHub: https://github.com/Planet-AI-GmbH/tfaip-hybrid-ctc-s2s.
VesSAM: Efficient Multi-Prompting for Segmenting Complex Vessel
Accurate vessel segmentation is critical for clinical applications such as disease diagnosis and surgical planning, yet remains challenging due to thin, branching structures and low texture contrast. While foundation models like the Segment Anything Model (SAM) have shown promise in generic segmentation, they perform sub-optimally on vascular structures. In this work, we present VesSAM, a powerful and efficient framework tailored for 2D vessel segmentation. VesSAM integrates (1) a convolutional adapter to enhance local texture features, (2) a multi-prompt encoder that fuses anatomical prompts, including skeletons, bifurcation points, and segment midpoints, via hierarchical cross-attention, and (3) a lightweight mask decoder to reduce jagged artifacts. We also introduce an automated pipeline to generate structured multi-prompt annotations, and curate a diverse benchmark dataset spanning 8 datasets across 5 imaging modalities. Experimental results demonstrate that VesSAM consistently outperforms state-of-the-art PEFT-based SAM variants by over 10% Dice and 13% IoU, and achieves competitive performance compared to fully fine-tuned methods, with significantly fewer parameters. VesSAM also generalizes well to out-of-distribution (OoD) settings, outperforming all baselines in average OoD Dice and IoU.
Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation
Single-channel, speaker-independent speech separation methods have recently seen great progress. However, the accuracy, latency, and computational cost of such methods remain insufficient. The majority of the previous methods have formulated the separation problem through the time-frequency representation of the mixed signal, which has several drawbacks, including the decoupling of the phase and magnitude of the signal, the suboptimality of time-frequency representation for speech separation, and the long latency in calculating the spectrograms. To address these shortcomings, we propose a fully-convolutional time-domain audio separation network (Conv-TasNet), a deep learning framework for end-to-end time-domain speech separation. Conv-TasNet uses a linear encoder to generate a representation of the speech waveform optimized for separating individual speakers. Speaker separation is achieved by applying a set of weighting functions (masks) to the encoder output. The modified encoder representations are then inverted back to the waveforms using a linear decoder. The masks are found using a temporal convolutional network (TCN) consisting of stacked 1-D dilated convolutional blocks, which allows the network to model the long-term dependencies of the speech signal while maintaining a small model size. The proposed Conv-TasNet system significantly outperforms previous time-frequency masking methods in separating two- and three-speaker mixtures. Additionally, Conv-TasNet surpasses several ideal time-frequency magnitude masks in two-speaker speech separation as evaluated by both objective distortion measures and subjective quality assessment by human listeners. Finally, Conv-TasNet has a significantly smaller model size and a shorter minimum latency, making it a suitable solution for both offline and real-time speech separation applications.
Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue
A significant weakness of most current deep Convolutional Neural Networks is the need to train them using vast amounts of manu- ally labelled data. In this work we propose a unsupervised framework to learn a deep convolutional neural network for single view depth predic- tion, without requiring a pre-training stage or annotated ground truth depths. We achieve this by training the network in a manner analogous to an autoencoder. At training time we consider a pair of images, source and target, with small, known camera motion between the two such as a stereo pair. We train the convolutional encoder for the task of predicting the depth map for the source image. To do so, we explicitly generate an inverse warp of the target image using the predicted depth and known inter-view displacement, to reconstruct the source image; the photomet- ric error in the reconstruction is the reconstruction loss for the encoder. The acquisition of this training data is considerably simpler than for equivalent systems, requiring no manual annotation, nor calibration of depth sensor to camera. We show that our network trained on less than half of the KITTI dataset (without any further augmentation) gives com- parable performance to that of the state of art supervised methods for single view depth estimation.
Accelerating Transformer Inference for Translation via Parallel Decoding
Autoregressive decoding limits the efficiency of transformers for Machine Translation (MT). The community proposed specific network architectures and learning-based methods to solve this issue, which are expensive and require changes to the MT model, trading inference speed at the cost of the translation quality. In this paper, we propose to address the problem from the point of view of decoding algorithms, as a less explored but rather compelling direction. We propose to reframe the standard greedy autoregressive decoding of MT with a parallel formulation leveraging Jacobi and Gauss-Seidel fixed-point iteration methods for fast inference. This formulation allows to speed up existing models without training or modifications while retaining translation quality. We present three parallel decoding algorithms and test them on different languages and models showing how the parallelization introduces a speedup up to 38% w.r.t. the standard autoregressive decoding and nearly 2x when scaling the method on parallel resources. Finally, we introduce a decoding dependency graph visualizer (DDGviz) that let us see how the model has learned the conditional dependence between tokens and inspect the decoding procedure.



Your ViT is Secretly an Image Segmentation Model
Vision Transformers (ViTs) have shown remarkable performance and scalability across various computer vision tasks. To apply single-scale ViTs to image segmentation, existing methods adopt a convolutional adapter to generate multi-scale features, a pixel decoder to fuse these features, and a Transformer decoder that uses the fused features to make predictions. In this paper, we show that the inductive biases introduced by these task-specific components can instead be learned by the ViT itself, given sufficiently large models and extensive pre-training. Based on these findings, we introduce the Encoder-only Mask Transformer (EoMT), which repurposes the plain ViT architecture to conduct image segmentation. With large-scale models and pre-training, EoMT obtains a segmentation accuracy similar to state-of-the-art models that use task-specific components. At the same time, EoMT is significantly faster than these methods due to its architectural simplicity, e.g., up to 4x faster with ViT-L. Across a range of model sizes, EoMT demonstrates an optimal balance between segmentation accuracy and prediction speed, suggesting that compute resources are better spent on scaling the ViT itself rather than adding architectural complexity. Code: https://www.tue-mps.org/eomt/.

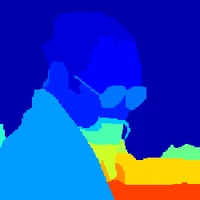


Improving anatomical plausibility in medical image segmentation via hybrid graph neural networks: applications to chest x-ray analysis
Anatomical segmentation is a fundamental task in medical image computing, generally tackled with fully convolutional neural networks which produce dense segmentation masks. These models are often trained with loss functions such as cross-entropy or Dice, which assume pixels to be independent of each other, thus ignoring topological errors and anatomical inconsistencies. We address this limitation by moving from pixel-level to graph representations, which allow to naturally incorporate anatomical constraints by construction. To this end, we introduce HybridGNet, an encoder-decoder neural architecture that leverages standard convolutions for image feature encoding and graph convolutional neural networks (GCNNs) to decode plausible representations of anatomical structures. We also propose a novel image-to-graph skip connection layer which allows localized features to flow from standard convolutional blocks to GCNN blocks, and show that it improves segmentation accuracy. The proposed architecture is extensively evaluated in a variety of domain shift and image occlusion scenarios, and audited considering different types of demographic domain shift. Our comprehensive experimental setup compares HybridGNet with other landmark and pixel-based models for anatomical segmentation in chest x-ray images, and shows that it produces anatomically plausible results in challenging scenarios where other models tend to fail.
Controlled Caption Generation for Images Through Adversarial Attacks
Deep learning is found to be vulnerable to adversarial examples. However, its adversarial susceptibility in image caption generation is under-explored. We study adversarial examples for vision and language models, which typically adopt an encoder-decoder framework consisting of two major components: a Convolutional Neural Network (i.e., CNN) for image feature extraction and a Recurrent Neural Network (RNN) for caption generation. In particular, we investigate attacks on the visual encoder's hidden layer that is fed to the subsequent recurrent network. The existing methods either attack the classification layer of the visual encoder or they back-propagate the gradients from the language model. In contrast, we propose a GAN-based algorithm for crafting adversarial examples for neural image captioning that mimics the internal representation of the CNN such that the resulting deep features of the input image enable a controlled incorrect caption generation through the recurrent network. Our contribution provides new insights for understanding adversarial attacks on vision systems with language component. The proposed method employs two strategies for a comprehensive evaluation. The first examines if a neural image captioning system can be misled to output targeted image captions. The second analyzes the possibility of keywords into the predicted captions. Experiments show that our algorithm can craft effective adversarial images based on the CNN hidden layers to fool captioning framework. Moreover, we discover the proposed attack to be highly transferable. Our work leads to new robustness implications for neural image captioning.
Modelling Long Range Dependencies in ND: From Task-Specific to a General Purpose CNN
Performant Convolutional Neural Network (CNN) architectures must be tailored to specific tasks in order to consider the length, resolution, and dimensionality of the input data. In this work, we tackle the need for problem-specific CNN architectures. We present the Continuous Convolutional Neural Network (CCNN): a single CNN able to process data of arbitrary resolution, dimensionality and length without any structural changes. Its key component are its continuous convolutional kernels which model long-range dependencies at every layer, and thus remove the need of current CNN architectures for task-dependent downsampling and depths. We showcase the generality of our method by using the same architecture for tasks on sequential (1{rm D}), visual (2{rm D}) and point-cloud (3{rm D}) data. Our CCNN matches and often outperforms the current state-of-the-art across all tasks considered.

Unsupervised Learning of Neural Networks to Explain Neural Networks
This paper presents an unsupervised method to learn a neural network, namely an explainer, to interpret a pre-trained convolutional neural network (CNN), i.e., explaining knowledge representations hidden in middle conv-layers of the CNN. Given feature maps of a certain conv-layer of the CNN, the explainer performs like an auto-encoder, which first disentangles the feature maps into object-part features and then inverts object-part features back to features of higher conv-layers of the CNN. More specifically, the explainer contains interpretable conv-layers, where each filter disentangles the representation of a specific object part from chaotic input feature maps. As a paraphrase of CNN features, the disentangled representations of object parts help people understand the logic inside the CNN. We also learn the explainer to use object-part features to reconstruct features of higher CNN layers, in order to minimize loss of information during the feature disentanglement. More crucially, we learn the explainer via network distillation without using any annotations of sample labels, object parts, or textures for supervision. We have applied our method to different types of CNNs for evaluation, and explainers have significantly boosted the interpretability of CNN features.

PredFormer: Transformers Are Effective Spatial-Temporal Predictive Learners
Spatiotemporal predictive learning methods generally fall into two categories: recurrent-based approaches, which face challenges in parallelization and performance, and recurrent-free methods, which employ convolutional neural networks (CNNs) as encoder-decoder architectures. These methods benefit from strong inductive biases but often at the expense of scalability and generalization. This paper proposes PredFormer, a pure transformer-based framework for spatiotemporal predictive learning. Motivated by the Vision Transformers (ViT) design, PredFormer leverages carefully designed Gated Transformer blocks, following a comprehensive analysis of 3D attention mechanisms, including full-, factorized-, and interleaved-spatial-temporal attention. With its recurrent-free, transformer-based design, PredFormer is both simple and efficient, significantly outperforming previous methods by large margins. Extensive experiments on synthetic and real-world datasets demonstrate that PredFormer achieves state-of-the-art performance. On Moving MNIST, PredFormer achieves a 51.3% reduction in MSE relative to SimVP. For TaxiBJ, the model decreases MSE by 33.1% and boosts FPS from 533 to 2364. Additionally, on WeatherBench, it reduces MSE by 11.1% while enhancing FPS from 196 to 404. These performance gains in both accuracy and efficiency demonstrate PredFormer's potential for real-world applications. The source code will be released at https://github.com/yyyujintang/PredFormer .
SkeletonMAE: Graph-based Masked Autoencoder for Skeleton Sequence Pre-training
Skeleton sequence representation learning has shown great advantages for action recognition due to its promising ability to model human joints and topology. However, the current methods usually require sufficient labeled data for training computationally expensive models, which is labor-intensive and time-consuming. Moreover, these methods ignore how to utilize the fine-grained dependencies among different skeleton joints to pre-train an efficient skeleton sequence learning model that can generalize well across different datasets. In this paper, we propose an efficient skeleton sequence learning framework, named Skeleton Sequence Learning (SSL). To comprehensively capture the human pose and obtain discriminative skeleton sequence representation, we build an asymmetric graph-based encoder-decoder pre-training architecture named SkeletonMAE, which embeds skeleton joint sequence into Graph Convolutional Network (GCN) and reconstructs the masked skeleton joints and edges based on the prior human topology knowledge. Then, the pre-trained SkeletonMAE encoder is integrated with the Spatial-Temporal Representation Learning (STRL) module to build the SSL framework. Extensive experimental results show that our SSL generalizes well across different datasets and outperforms the state-of-the-art self-supervised skeleton-based action recognition methods on FineGym, Diving48, NTU 60 and NTU 120 datasets. Additionally, we obtain comparable performance to some fully supervised methods. The code is avaliable at https://github.com/HongYan1123/SkeletonMAE.
Training data-efficient image transformers & distillation through attention
Recently, neural networks purely based on attention were shown to address image understanding tasks such as image classification. However, these visual transformers are pre-trained with hundreds of millions of images using an expensive infrastructure, thereby limiting their adoption. In this work, we produce a competitive convolution-free transformer by training on Imagenet only. We train them on a single computer in less than 3 days. Our reference vision transformer (86M parameters) achieves top-1 accuracy of 83.1% (single-crop evaluation) on ImageNet with no external data. More importantly, we introduce a teacher-student strategy specific to transformers. It relies on a distillation token ensuring that the student learns from the teacher through attention. We show the interest of this token-based distillation, especially when using a convnet as a teacher. This leads us to report results competitive with convnets for both Imagenet (where we obtain up to 85.2% accuracy) and when transferring to other tasks. We share our code and models.