new
Get trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
"Teach AI How to Code": Using Large Language Models as Teachable Agents for Programming Education
This work investigates large language models (LLMs) as teachable agents for learning by teaching (LBT). LBT with teachable agents helps learners identify their knowledge gaps and discover new knowledge. However, teachable agents require expensive programming of subject-specific knowledge. While LLMs as teachable agents can reduce the cost, LLMs' over-competence as tutees discourages learners from teaching. We propose a prompting pipeline that restrains LLMs' competence and makes them initiate "why" and "how" questions for effective knowledge-building. We combined these techniques into TeachYou, an LBT environment for algorithm learning, and AlgoBo, an LLM-based tutee chatbot that can simulate misconceptions and unawareness prescribed in its knowledge state. Our technical evaluation confirmed that our prompting pipeline can effectively configure AlgoBo's problem-solving performance. Through a between-subject study with 40 algorithm novices, we also observed that AlgoBo's questions led to knowledge-dense conversations (effect size=0.73). Lastly, we discuss design implications, cost-efficiency, and personalization of LLM-based teachable agents.
How to Build an AI Tutor that Can Adapt to Any Course and Provide Accurate Answers Using Large Language Model and Retrieval-Augmented Generation
Artificial intelligence is transforming education through data-driven, personalized learning solutions. This paper introduces AI Tutor, an innovative web application that provides personalized tutoring in any subject using state-of-the-art Large Language Model (LLM). AI Tutor ingests course materials to construct an adaptive knowledge base tailored to the course. When students pose questions, it retrieves the most relevant information and generates detailed, conversational responses citing supporting evidence. The system is powered by advanced large language models and Retrieval-Augmented Generation (RAG) techniques for accurate, natural question answering. We present a fully-functional web interface and video demonstration that showcase AI Tutor's versatility across diverse subjects and its ability to produce pedagogically cogent responses. While an initial prototype, this work represents a pioneering step toward AI-enabled tutoring systems that can democratize access to high-quality, customized educational support.
Training Turn-by-Turn Verifiers for Dialogue Tutoring Agents: The Curious Case of LLMs as Your Coding Tutors
Intelligent tutoring agents powered by large language models (LLMs) have been increasingly explored to deliver personalized guidance in areas such as language learning and science education. However, their capabilities in guiding users to solve complex real-world tasks remain underexplored. To address this limitation, in this work, we focus on coding tutoring, a challenging problem that requires tutors to proactively guide students toward completing predefined coding tasks. We propose a novel agent workflow, Trace-and-Verify (TRAVER), which combines knowledge tracing to estimate a student's knowledge state and turn-by-turn verification to ensure effective guidance toward task completion. We introduce DICT, an automatic evaluation protocol that assesses tutor agents holistically using controlled student simulation and code generation tests. Extensive experiments reveal the challenges of coding tutoring and demonstrate that TRAVER achieves a significantly higher success rate. Although we use code tutoring as an example in this paper, our results and findings can be extended beyond coding, providing valuable insights into advancing tutoring agents for a variety of tasks.



Kickstarting Deep Reinforcement Learning
We present a method for using previously-trained 'teacher' agents to kickstart the training of a new 'student' agent. To this end, we leverage ideas from policy distillation and population based training. Our method places no constraints on the architecture of the teacher or student agents, and it regulates itself to allow the students to surpass their teachers in performance. We show that, on a challenging and computationally-intensive multi-task benchmark (DMLab-30), kickstarted training improves the data efficiency of new agents, making it significantly easier to iterate on their design. We also show that the same kickstarting pipeline can allow a single student agent to leverage multiple 'expert' teachers which specialize on individual tasks. In this setting kickstarting yields surprisingly large gains, with the kickstarted agent matching the performance of an agent trained from scratch in almost 10x fewer steps, and surpassing its final performance by 42 percent. Kickstarting is conceptually simple and can easily be incorporated into reinforcement learning experiments.
Memento No More: Coaching AI Agents to Master Multiple Tasks via Hints Internalization
As the general capabilities of artificial intelligence (AI) agents continue to evolve, their ability to learn to master multiple complex tasks through experience remains a key challenge. Current LLM agents, particularly those based on proprietary language models, typically rely on prompts to incorporate knowledge about the target tasks. This approach does not allow the agent to internalize this information and instead relies on ever-expanding prompts to sustain its functionality in diverse scenarios. This resembles a system of notes used by a person affected by anterograde amnesia, the inability to form new memories. In this paper, we propose a novel method to train AI agents to incorporate knowledge and skills for multiple tasks without the need for either cumbersome note systems or prior high-quality demonstration data. Our approach employs an iterative process where the agent collects new experiences, receives corrective feedback from humans in the form of hints, and integrates this feedback into its weights via a context distillation training procedure. We demonstrate the efficacy of our approach by implementing it in a Llama-3-based agent that, after only a few rounds of feedback, outperforms advanced models GPT-4o and DeepSeek-V3 in tasksets requiring correct sequencing of information retrieval, tool use, and question answering.
Symbolic Learning Enables Self-Evolving Agents
The AI community has been exploring a pathway to artificial general intelligence (AGI) by developing "language agents", which are complex large language models (LLMs) pipelines involving both prompting techniques and tool usage methods. While language agents have demonstrated impressive capabilities for many real-world tasks, a fundamental limitation of current language agents research is that they are model-centric, or engineering-centric. That's to say, the progress on prompts, tools, and pipelines of language agents requires substantial manual engineering efforts from human experts rather than automatically learning from data. We believe the transition from model-centric, or engineering-centric, to data-centric, i.e., the ability of language agents to autonomously learn and evolve in environments, is the key for them to possibly achieve AGI. In this work, we introduce agent symbolic learning, a systematic framework that enables language agents to optimize themselves on their own in a data-centric way using symbolic optimizers. Specifically, we consider agents as symbolic networks where learnable weights are defined by prompts, tools, and the way they are stacked together. Agent symbolic learning is designed to optimize the symbolic network within language agents by mimicking two fundamental algorithms in connectionist learning: back-propagation and gradient descent. Instead of dealing with numeric weights, agent symbolic learning works with natural language simulacrums of weights, loss, and gradients. We conduct proof-of-concept experiments on both standard benchmarks and complex real-world tasks and show that agent symbolic learning enables language agents to update themselves after being created and deployed in the wild, resulting in "self-evolving agents".





How^{2}: How to learn from procedural How-to questions
An agent facing a planning problem can use answers to how-to questions to reduce uncertainty and fill knowledge gaps, helping it solve both current and future tasks. However, their open ended nature, where valid answers to "How do I X?" range from executable actions to high-level descriptions of X's sub-goals, makes them challenging for AI agents to ask, and for AI experts to answer, in ways that support efficient planning. We introduce How^{2}, a memory agent framework that enables agents to ask how-to questions, store the answers, and reuse them for lifelong learning in interactive environments. We evaluate our approach in Plancraft, a Minecraft crafting environment, where agents must complete an assembly task by manipulating inventory items. Using teacher models that answer at varying levels of abstraction, from executable action sequences to high-level subgoal descriptions, we show that lifelong learning agents benefit most from answers that are abstracted and decoupled from the current state. How^{2} offers a way for LLM-based agents to improve their planning capabilities over time by asking questions in interactive environments.
DataEnvGym: Data Generation Agents in Teacher Environments with Student Feedback
The process of creating training data to teach models is currently driven by humans, who manually analyze model weaknesses and plan how to create data that improves a student model. Recent approaches using LLMs as annotators reduce human effort, but still require humans to interpret feedback from evaluations and control the LLM to produce data the student needs. Automating this labor-intensive process by creating autonomous data generation agents - or teachers - is desirable, but requires environments that can simulate the feedback-driven, iterative, closed loop of data creation. To enable rapid and scalable testing for such agents and their modules, we introduce DataEnvGym, a testbed of teacher environments for data generation agents. DataEnvGym frames data generation as a sequential decision-making task, involving an agent consisting of a data generation policy (which generates a plan for creating training data) and a data generation engine (which transforms the plan into data), inside an environment that provides student feedback. The agent's goal is to improve student performance. Students are iteratively trained and evaluated on generated data, with their feedback (in the form of errors or weak skills) being reported to the agent after each iteration. DataEnvGym includes multiple teacher environment instantiations across 3 levels of structure in the state representation and action space. More structured environments are based on inferred skills and offer more interpretability and curriculum control. We support 3 diverse tasks (math, code, and VQA) and test multiple students and teachers. Example agents in our teaching environments can iteratively improve students across tasks and settings. Moreover, we show that environments teach different skill levels and test variants of key modules, pointing to future work in improving data generation agents, engines, and feedback mechanisms.


AgentTuning: Enabling Generalized Agent Abilities for LLMs
Open large language models (LLMs) with great performance in various tasks have significantly advanced the development of LLMs. However, they are far inferior to commercial models such as ChatGPT and GPT-4 when acting as agents to tackle complex tasks in the real world. These agent tasks employ LLMs as the central controller responsible for planning, memorization, and tool utilization, necessitating both fine-grained prompting methods and robust LLMs to achieve satisfactory performance. Though many prompting methods have been proposed to complete particular agent tasks, there is lack of research focusing on improving the agent capabilities of LLMs themselves without compromising their general abilities. In this work, we present AgentTuning, a simple and general method to enhance the agent abilities of LLMs while maintaining their general LLM capabilities. We construct AgentInstruct, a lightweight instruction-tuning dataset containing high-quality interaction trajectories. We employ a hybrid instruction-tuning strategy by combining AgentInstruct with open-source instructions from general domains. AgentTuning is used to instruction-tune the Llama 2 series, resulting in AgentLM. Our evaluations show that AgentTuning enables LLMs' agent capabilities without compromising general abilities. The AgentLM-70B is comparable to GPT-3.5-turbo on unseen agent tasks, demonstrating generalized agent capabilities. We open source the AgentInstruct and AgentLM-7B, 13B, and 70B models at https://github.com/THUDM/AgentTuning , serving open and powerful alternatives to commercial LLMs for agent tasks.



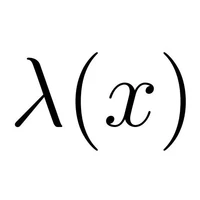

Agent Lightning: Train ANY AI Agents with Reinforcement Learning
We present Agent Lightning, a flexible and extensible framework that enables Reinforcement Learning (RL)-based training of Large Language Models (LLMs) for any AI agent. Unlike existing methods that tightly couple RL training with agent or rely on sequence concatenation with masking, Agent Lightning achieves complete decoupling between agent execution and training, allowing seamless integration with existing agents developed via diverse ways (e.g., using frameworks like LangChain, OpenAI Agents SDK, AutoGen, and building from scratch) with almost ZERO code modifications. By formulating agent execution as Markov decision process, we define an unified data interface and propose a hierarchical RL algorithm, LightningRL, which contains a credit assignment module, allowing us to decompose trajectories generated by ANY agents into training transition. This enables RL to handle complex interaction logic, such as multi-agent scenarios and dynamic workflows. For the system design, we introduce a Training-Agent Disaggregation architecture, and brings agent observability frameworks into agent runtime, providing a standardized agent finetuning interface. Experiments across text-to-SQL, retrieval-augmented generation, and math tool-use tasks demonstrate stable, continuous improvements, showcasing the framework's potential for real-world agent training and deployment.





InfoAgent: Advancing Autonomous Information-Seeking Agents
Building Large Language Model agents that expand their capabilities by interacting with external tools represents a new frontier in AI research and applications. In this paper, we introduce InfoAgent, a deep research agent powered by an innovative data synthesis pipeline and orchestrated web search tools. To construct challenging, hard-to-find queries,we build entity trees and apply sub-tree sampling with entity fuzzification to systematically increase question difficulty. Unlike prior work that relies heavily on commercial search tools, we develop a dedicated self-hosted search infrastructure, enhancing transparency of agent environments and facilitating further advancement of agent capacity. We evaluate the effectiveness of our data pipeline by measuring the average number of tool calls required to correctly answer a question, and also show that our agent yields better performance when equipped with our tools. Our InfoAgent is post-trained from Qwen3-14B using a two-stage recipe: cold-start supervised finetuning to instill long-horizon search behaviors, followed by reinforcement learning which significantly improves reasoning-driven tool use. With our methods, InfoAgent achieves 15.3\% accuracy on BrowseComp, 29.2\% on BrowseComp-ZH, and 40.4\% on Xbench-DS, outperforming prior open-source deep research agents such as WebSailor-72B and DeepDive-32B.

Situated Language Learning via Interactive Narratives
This paper provides a roadmap that explores the question of how to imbue learning agents with the ability to understand and generate contextually relevant natural language in service of achieving a goal. We hypothesize that two key components in creating such agents are interactivity and environment grounding, shown to be vital parts of language learning in humans, and posit that interactive narratives should be the environments of choice for such training these agents. These games are simulations in which an agent interacts with the world through natural language -- "perceiving", "acting upon", and "talking to" the world using textual descriptions, commands, and dialogue -- and as such exist at the intersection of natural language processing, storytelling, and sequential decision making. We discuss the unique challenges a text games' puzzle-like structure combined with natural language state-and-action spaces provides: knowledge representation, commonsense reasoning, and exploration. Beyond the challenges described so far, progress in the realm of interactive narratives can be applied in adjacent problem domains. These applications provide interesting challenges of their own as well as extensions to those discussed so far. We describe three of them in detail: (1) evaluating AI system's commonsense understanding by automatically creating interactive narratives; (2) adapting abstract text-based policies to include other modalities such as vision; and (3) enabling multi-agent and human-AI collaboration in shared, situated worlds.
AgentTrek: Agent Trajectory Synthesis via Guiding Replay with Web Tutorials
Graphical User Interface (GUI) agents hold great potential for automating complex tasks across diverse digital environments, from web applications to desktop software. However, the development of such agents is hindered by the lack of high-quality, multi-step trajectory data required for effective training. Existing approaches rely on expensive and labor-intensive human annotation, making them unsustainable at scale. To address this challenge, we propose AgentTrek, a scalable data synthesis pipeline that generates high-quality GUI agent trajectories by leveraging web tutorials. Our method automatically gathers tutorial-like texts from the internet, transforms them into task goals with step-by-step instructions, and employs a visual-language model agent to simulate their execution in a real digital environment. A VLM-based evaluator ensures the correctness of the generated trajectories. We demonstrate that training GUI agents with these synthesized trajectories significantly improves their grounding and planning performance over the current models. Moreover, our approach is more cost-efficient compared to traditional human annotation methods. This work underscores the potential of guided replay with web tutorials as a viable strategy for large-scale GUI agent training, paving the way for more capable and autonomous digital agents.





LIMI: Less is More for Agency
We define Agency as the emergent capacity of AI systems to function as autonomous agents actively discovering problems, formulating hypotheses, and executing solutions through self-directed engagement with environments and tools. This fundamental capability marks the dawn of the Age of AI Agency, driven by a critical industry shift: the urgent need for AI systems that don't just think, but work. While current AI excels at reasoning and generating responses, industries demand autonomous agents that can execute tasks, operate tools, and drive real-world outcomes. As agentic intelligence becomes the defining characteristic separating cognitive systems from productive workers, efficiently cultivating machine autonomy becomes paramount. Current approaches assume that more data yields better agency, following traditional scaling laws from language modeling. We fundamentally challenge this paradigm. LIMI (Less Is More for Intelligent Agency) demonstrates that agency follows radically different development principles. Through strategic focus on collaborative software development and scientific research workflows, we show that sophisticated agentic intelligence can emerge from minimal but strategically curated demonstrations of autonomous behavior. Using only 78 carefully designed training samples, LIMI achieves 73.5% on comprehensive agency benchmarks, dramatically outperforming state-of-the-art models: Kimi-K2-Instruct (24.1%), DeepSeek-V3.1 (11.9%), Qwen3-235B-A22B-Instruct (27.5%), and GLM-4.5 (45.1%). Most strikingly, LIMI demonstrates 53.7% improvement over models trained on 10,000 samples-achieving superior agentic intelligence with 128 times fewer samples. Our findings establish the Agency Efficiency Principle: machine autonomy emerges not from data abundance but from strategic curation of high-quality agentic demonstrations.





DANLI: Deliberative Agent for Following Natural Language Instructions
Recent years have seen an increasing amount of work on embodied AI agents that can perform tasks by following human language instructions. However, most of these agents are reactive, meaning that they simply learn and imitate behaviors encountered in the training data. These reactive agents are insufficient for long-horizon complex tasks. To address this limitation, we propose a neuro-symbolic deliberative agent that, while following language instructions, proactively applies reasoning and planning based on its neural and symbolic representations acquired from past experience (e.g., natural language and egocentric vision). We show that our deliberative agent achieves greater than 70% improvement over reactive baselines on the challenging TEACh benchmark. Moreover, the underlying reasoning and planning processes, together with our modular framework, offer impressive transparency and explainability to the behaviors of the agent. This enables an in-depth understanding of the agent's capabilities, which shed light on challenges and opportunities for future embodied agents for instruction following. The code is available at https://github.com/sled-group/DANLI.



Scaling Agents via Continual Pre-training
Large language models (LLMs) have evolved into agentic systems capable of autonomous tool use and multi-step reasoning for complex problem-solving. However, post-training approaches building upon general-purpose foundation models consistently underperform in agentic tasks, particularly in open-source implementations. We identify the root cause: the absence of robust agentic foundation models forces models during post-training to simultaneously learn diverse agentic behaviors while aligning them to expert demonstrations, thereby creating fundamental optimization tensions. To this end, we are the first to propose incorporating Agentic Continual Pre-training (Agentic CPT) into the deep research agents training pipeline to build powerful agentic foundational models. Based on this approach, we develop a deep research agent model named AgentFounder. We evaluate our AgentFounder-30B on 10 benchmarks and achieve state-of-the-art performance while retains strong tool-use ability, notably 39.9% on BrowseComp-en, 43.3% on BrowseComp-zh, and 31.5% Pass@1 on HLE.




Factored Agents: Decoupling In-Context Learning and Memorization for Robust Tool Use
In this paper, we propose a novel factored agent architecture designed to overcome the limitations of traditional single-agent systems in agentic AI. Our approach decomposes the agent into two specialized components: (1) a large language model (LLM) that serves as a high level planner and in-context learner, which may use dynamically available information in user prompts, (2) a smaller language model which acts as a memorizer of tool format and output. This decoupling addresses prevalent issues in monolithic designs, including malformed, missing, and hallucinated API fields, as well as suboptimal planning in dynamic environments. Empirical evaluations demonstrate that our factored architecture significantly improves planning accuracy and error resilience, while elucidating the inherent trade-off between in-context learning and static memorization. These findings suggest that a factored approach is a promising pathway for developing more robust and adaptable agentic AI systems.
AI Agents: Evolution, Architecture, and Real-World Applications
This paper examines the evolution, architecture, and practical applications of AI agents from their early, rule-based incarnations to modern sophisticated systems that integrate large language models with dedicated modules for perception, planning, and tool use. Emphasizing both theoretical foundations and real-world deployments, the paper reviews key agent paradigms, discusses limitations of current evaluation benchmarks, and proposes a holistic evaluation framework that balances task effectiveness, efficiency, robustness, and safety. Applications across enterprise, personal assistance, and specialized domains are analyzed, with insights into future research directions for more resilient and adaptive AI agent systems.
LearnLM: Improving Gemini for Learning
Today's generative AI systems are tuned to present information by default rather than engage users in service of learning as a human tutor would. To address the wide range of potential education use cases for these systems, we reframe the challenge of injecting pedagogical behavior as one of pedagogical instruction following, where training and evaluation examples include system-level instructions describing the specific pedagogy attributes present or desired in subsequent model turns. This framing avoids committing our models to any particular definition of pedagogy, and instead allows teachers or developers to specify desired model behavior. It also clears a path to improving Gemini models for learning -- by enabling the addition of our pedagogical data to post-training mixtures -- alongside their rapidly expanding set of capabilities. Both represent important changes from our initial tech report. We show how training with pedagogical instruction following produces a LearnLM model (available on Google AI Studio) that is preferred substantially by expert raters across a diverse set of learning scenarios, with average preference strengths of 31\% over GPT-4o, 11\% over Claude 3.5, and 13\% over the Gemini 1.5 Pro model LearnLM was based on.
MaestroMotif: Skill Design from Artificial Intelligence Feedback
Describing skills in natural language has the potential to provide an accessible way to inject human knowledge about decision-making into an AI system. We present MaestroMotif, a method for AI-assisted skill design, which yields high-performing and adaptable agents. MaestroMotif leverages the capabilities of Large Language Models (LLMs) to effectively create and reuse skills. It first uses an LLM's feedback to automatically design rewards corresponding to each skill, starting from their natural language description. Then, it employs an LLM's code generation abilities, together with reinforcement learning, for training the skills and combining them to implement complex behaviors specified in language. We evaluate MaestroMotif using a suite of complex tasks in the NetHack Learning Environment (NLE), demonstrating that it surpasses existing approaches in both performance and usability.
Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning
Large Language Model (LLM) Agents, often trained with Reinforcement Learning (RL), are constrained by a dependency on human-curated data, limiting scalability and tethering AI to human knowledge. Existing self-evolution frameworks offer an alternative but are typically restricted by the model's inherent capabilities and single-round interactions, hindering the development of complex curricula involving tool use or dynamic reasoning. We introduce Agent0, a fully autonomous framework that evolves high-performing agents without external data through multi-step co-evolution and seamless tool integration. Agent0 establishes a symbiotic competition between two agents initialized from the same base LLM: a curriculum agent that proposes increasingly challenging frontier tasks, and an executor agent that learns to solve them. We integrate external tools to enhance the executor's problem-solving capacity; this improvement, in turn, pressures the curriculum agent to construct more complex, tool-aware tasks. Through this iterative process, Agent0 establishes a self-reinforcing cycle that continuously produces high-quality curricula. Empirically, Agent0 substantially boosts reasoning capabilities, improving the Qwen3-8B-Base model by 18% on mathematical reasoning and 24% on general reasoning benchmarks. Code is available at https://github.com/aiming-lab/Agent0.

AITEE -- Agentic Tutor for Electrical Engineering
Intelligent tutoring systems combined with large language models offer a promising approach to address students' diverse needs and promote self-efficacious learning. While large language models possess good foundational knowledge of electrical engineering basics, they remain insufficiently capable of addressing specific questions about electrical circuits. In this paper, we present AITEE, an agent-based tutoring system for electrical engineering designed to accompany students throughout their learning process, offer individualized support, and promote self-directed learning. AITEE supports both hand-drawn and digital circuits through an adapted circuit reconstruction process, enabling natural interaction with students. Our novel graph-based similarity measure identifies relevant context from lecture materials through a retrieval augmented generation approach, while parallel Spice simulation further enhances accuracy in applying solution methodologies. The system implements a Socratic dialogue to foster learner autonomy through guided questioning. Experimental evaluations demonstrate that AITEE significantly outperforms baseline approaches in domain-specific knowledge application, with even medium-sized LLM models showing acceptable performance. Our results highlight the potential of agentic tutors to deliver scalable, personalized, and effective learning environments for electrical engineering education.

TEACh: Task-driven Embodied Agents that Chat
Robots operating in human spaces must be able to engage in natural language interaction with people, both understanding and executing instructions, and using conversation to resolve ambiguity and recover from mistakes. To study this, we introduce TEACh, a dataset of over 3,000 human--human, interactive dialogues to complete household tasks in simulation. A Commander with access to oracle information about a task communicates in natural language with a Follower. The Follower navigates through and interacts with the environment to complete tasks varying in complexity from "Make Coffee" to "Prepare Breakfast", asking questions and getting additional information from the Commander. We propose three benchmarks using TEACh to study embodied intelligence challenges, and we evaluate initial models' abilities in dialogue understanding, language grounding, and task execution.


Better than Your Teacher: LLM Agents that learn from Privileged AI Feedback
While large language models (LLMs) show impressive decision-making abilities, current methods lack a mechanism for automatic self-improvement from errors during task execution. We propose LEAP, an iterative fine-tuning framework that continually improves LLM agents using feedback from AI expert teachers. Our key insight is to equip the expert teachers with a privileged state -- information that is available during training but hidden at test time. This allows even weak experts to provide precise guidance, significantly improving the student agent's performance without access to privileged information at test time. We evaluate LEAP on diverse decision-making benchmarks, including text-based games (ALFWorld), web navigation (WebShop), and interactive coding (Intercode Bash). Our experiments show that LEAP (1) outperforms behavior cloning and ReAct baselines (2) enables weak student models (e.g., Llama3-8B) to exceed the performance of strong teacher models (GPT4-o), and (3) allows weak models to self-improve using privileged versions of themselves. We also provide a theoretical analysis showing that LEAP's success hinges on balancing privileged information with the student's realizability, which we empirically validate. Our code is available at https://leap-llm.github.io


Game On: Towards Language Models as RL Experimenters
We propose an agent architecture that automates parts of the common reinforcement learning experiment workflow, to enable automated mastery of control domains for embodied agents. To do so, it leverages a VLM to perform some of the capabilities normally required of a human experimenter, including the monitoring and analysis of experiment progress, the proposition of new tasks based on past successes and failures of the agent, decomposing tasks into a sequence of subtasks (skills), and retrieval of the skill to execute - enabling our system to build automated curricula for learning. We believe this is one of the first proposals for a system that leverages a VLM throughout the full experiment cycle of reinforcement learning. We provide a first prototype of this system, and examine the feasibility of current models and techniques for the desired level of automation. For this, we use a standard Gemini model, without additional fine-tuning, to provide a curriculum of skills to a language-conditioned Actor-Critic algorithm, in order to steer data collection so as to aid learning new skills. Data collected in this way is shown to be useful for learning and iteratively improving control policies in a robotics domain. Additional examination of the ability of the system to build a growing library of skills, and to judge the progress of the training of those skills, also shows promising results, suggesting that the proposed architecture provides a potential recipe for fully automated mastery of tasks and domains for embodied agents.
Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data
This paper investigates the intriguing question of whether we can create learning algorithms that automatically generate training data, learning environments, and curricula in order to help AI agents rapidly learn. We show that such algorithms are possible via Generative Teaching Networks (GTNs), a general approach that is, in theory, applicable to supervised, unsupervised, and reinforcement learning, although our experiments only focus on the supervised case. GTNs are deep neural networks that generate data and/or training environments that a learner (e.g. a freshly initialized neural network) trains on for a few SGD steps before being tested on a target task. We then differentiate through the entire learning process via meta-gradients to update the GTN parameters to improve performance on the target task. GTNs have the beneficial property that they can theoretically generate any type of data or training environment, making their potential impact large. This paper introduces GTNs, discusses their potential, and showcases that they can substantially accelerate learning. We also demonstrate a practical and exciting application of GTNs: accelerating the evaluation of candidate architectures for neural architecture search (NAS), which is rate-limited by such evaluations, enabling massive speed-ups in NAS. GTN-NAS improves the NAS state of the art, finding higher performing architectures when controlling for the search proposal mechanism. GTN-NAS also is competitive with the overall state of the art approaches, which achieve top performance while using orders of magnitude less computation than typical NAS methods. Speculating forward, GTNs may represent a first step toward the ambitious goal of algorithms that generate their own training data and, in doing so, open a variety of interesting new research questions and directions.
ChatGPT-steered Editing Instructor for Customization of Abstractive Summarization
Tailoring outputs of large language models, such as ChatGPT, to specific user needs remains a challenge despite their impressive generation quality. In this paper, we propose a tri-agent generation pipeline consisting of a generator, an instructor, and an editor to enhance the customization of generated outputs. The generator produces an initial output, the user-specific instructor generates editing instructions, and the editor generates a revised output aligned with user preferences. The inference-only large language model (ChatGPT) serves as both the generator and the editor, while a smaller model acts as the user-specific instructor to guide the generation process toward user needs. The instructor is trained using editor-steered reinforcement learning, leveraging feedback from the large-scale editor model to optimize instruction generation. Experimental results on two abstractive summarization datasets demonstrate the effectiveness of our approach in generating outputs that better fulfill user expectations.

EduPlanner: LLM-Based Multi-Agent Systems for Customized and Intelligent Instructional Design
Large Language Models (LLMs) have significantly advanced smart education in the Artificial General Intelligence (AGI) era. A promising application lies in the automatic generalization of instructional design for curriculum and learning activities, focusing on two key aspects: (1) Customized Generation: generating niche-targeted teaching content based on students' varying learning abilities and states, and (2) Intelligent Optimization: iteratively optimizing content based on feedback from learning effectiveness or test scores. Currently, a single large LLM cannot effectively manage the entire process, posing a challenge for designing intelligent teaching plans. To address these issues, we developed EduPlanner, an LLM-based multi-agent system comprising an evaluator agent, an optimizer agent, and a question analyst, working in adversarial collaboration to generate customized and intelligent instructional design for curriculum and learning activities. Taking mathematics lessons as our example, EduPlanner employs a novel Skill-Tree structure to accurately model the background mathematics knowledge of student groups, personalizing instructional design for curriculum and learning activities according to students' knowledge levels and learning abilities. Additionally, we introduce the CIDDP, an LLM-based five-dimensional evaluation module encompassing clarity, Integrity, Depth, Practicality, and Pertinence, to comprehensively assess mathematics lesson plan quality and bootstrap intelligent optimization. Experiments conducted on the GSM8K and Algebra datasets demonstrate that EduPlanner excels in evaluating and optimizing instructional design for curriculum and learning activities. Ablation studies further validate the significance and effectiveness of each component within the framework. Our code is publicly available at https://github.com/Zc0812/Edu_Planner
AIDE: AI-Driven Exploration in the Space of Code
Machine learning, the foundation of modern artificial intelligence, has driven innovations that have fundamentally transformed the world. Yet, behind advancements lies a complex and often tedious process requiring labor and compute intensive iteration and experimentation. Engineers and scientists developing machine learning models spend much of their time on trial-and-error tasks instead of conceptualizing innovative solutions or research hypotheses. To address this challenge, we introduce AI-Driven Exploration (AIDE), a machine learning engineering agent powered by large language models (LLMs). AIDE frames machine learning engineering as a code optimization problem, and formulates trial-and-error as a tree search in the space of potential solutions. By strategically reusing and refining promising solutions, AIDE effectively trades computational resources for enhanced performance, achieving state-of-the-art results on multiple machine learning engineering benchmarks, including our Kaggle evaluations, OpenAI MLE-Bench and METRs RE-Bench.





Continual Learning, Not Training: Online Adaptation For Agents
Continual Learning (CL) methods have traditionally focused on mitigating catastrophic forgetting through gradient-based retraining, an approach ill-suited for deployed agents that must adapt in real time. We introduce our Adaptive Teaching and Learning System (ATLAS), a dual-agent architecture that decouples reasoning (Teacher) from execution (Student) and incorporates a persistent learning memory that stores distilled guidance from experience. This informs the orchestration layer, enabling the system to dynamically adjust its operational strategies, such as supervision level or initial plan selection, at inference time. In doing so, ATLAS achieves gradient-free continual learning, shifting the locus of adaptation from model parameters to system-level orchestration. We formulate this as a system-centric paradigm for continual learning, where the objective is adaptive efficiency: maximizing task success while minimizing computational cost through inference-time orchestration rather than parameter updates. Evaluated on Microsoft's ExCyTIn-Bench, an open-source benchmark simulating complex cyberthreat investigation, ATLAS achieves 54.1% success with GPT-5-mini as its Student, outperforming the larger GPT-5 (High) by 13% while reducing cost by 86%. Cross-incident validation demonstrates generalization: frozen pamphlets from Incident #5 improve accuracy from 28% to 41% with zero retraining, while shifting output composition from verbose exploration to structured reasoning. Together, these findings establish gradient-free continual learning as a viable path toward adaptive, deployable AI systems and provide causally annotated traces valuable for training explicit world models.

KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents
Large Language Models (LLMs) have demonstrated great potential in complex reasoning tasks, yet they fall short when tackling more sophisticated challenges, especially when interacting with environments through generating executable actions. This inadequacy primarily stems from the lack of built-in action knowledge in language agents, which fails to effectively guide the planning trajectories during task solving and results in planning hallucination. To address this issue, we introduce KnowAgent, a novel approach designed to enhance the planning capabilities of LLMs by incorporating explicit action knowledge. Specifically, KnowAgent employs an action knowledge base and a knowledgeable self-learning strategy to constrain the action path during planning, enabling more reasonable trajectory synthesis, and thereby enhancing the planning performance of language agents. Experimental results on HotpotQA and ALFWorld based on various backbone models demonstrate that KnowAgent can achieve comparable or superior performance to existing baselines. Further analysis indicates the effectiveness of KnowAgent in terms of planning hallucinations mitigation. Code is available in https://github.com/zjunlp/KnowAgent.



GraphMASAL: A Graph-based Multi-Agent System for Adaptive Learning
The advent of Intelligent Tutoring Systems (ITSs) has marked a paradigm shift in education, enabling highly personalized learning pathways. However, true personalization requires adapting to learners' complex knowledge states (multi-source) and diverse goals (multi-sink); existing ITSs often lack the necessary structural-reasoning capability and knowledge dynamism to generate genuinely effective learning paths, and they lack scientifically rigorous validation paradigms. In this paper we propose GraphMASAL (A Graph-based Multi-Agent System for Adaptive Learning), which integrates (i) a dynamic knowledge graph for persistent, stateful learner modeling; (ii) a LangGraph-orchestrated trio of agents (Diagnostician, Planner, Tutor); (iii) a knowledge-graph-grounded two-stage neural IR component (dual-encoder dense retrieval with cross-encoder listwise re-ranking and calibrated score fusion); and (iv) a multi-source multi-sink (MSMS) planning engine with a cognitively grounded cost and an approximation guarantee via greedy set cover. Under blinded automated evaluations with matched inputs and inference settings across diverse student profiles, GraphMASAL consistently outperforms LLM prompting and structured ablations in planning--achieving stronger structural/sequence alignment of learning paths, higher coverage of weak concepts, and lower learning cost--while also surpassing prompt-based baselines in cognitive diagnosis. Agreement with expert/LLM-proxy ratings further supports the validity of our evaluation protocol. These findings indicate that grounding LLM agents in a dynamic knowledge graph, coupled with optimization under educational constraints, yields reliable, interpretable, and pedagogically plausible learning plans, advancing personalized and goal-oriented education.
AI Agents vs. Agentic AI: A Conceptual Taxonomy, Applications and Challenge
This study critically distinguishes between AI Agents and Agentic AI, offering a structured conceptual taxonomy, application mapping, and challenge analysis to clarify their divergent design philosophies and capabilities. We begin by outlining the search strategy and foundational definitions, characterizing AI Agents as modular systems driven by Large Language Models (LLMs) and Large Image Models (LIMs) for narrow, task-specific automation. Generative AI is positioned as a precursor, with AI Agents advancing through tool integration, prompt engineering, and reasoning enhancements. In contrast, Agentic AI systems represent a paradigmatic shift marked by multi-agent collaboration, dynamic task decomposition, persistent memory, and orchestrated autonomy. Through a sequential evaluation of architectural evolution, operational mechanisms, interaction styles, and autonomy levels, we present a comparative analysis across both paradigms. Application domains such as customer support, scheduling, and data summarization are contrasted with Agentic AI deployments in research automation, robotic coordination, and medical decision support. We further examine unique challenges in each paradigm including hallucination, brittleness, emergent behavior, and coordination failure and propose targeted solutions such as ReAct loops, RAG, orchestration layers, and causal modeling. This work aims to provide a definitive roadmap for developing robust, scalable, and explainable AI agent and Agentic AI-driven systems. >AI Agents, Agent-driven, Vision-Language-Models, Agentic AI Decision Support System, Agentic-AI Applications


Instruction Agent: Enhancing Agent with Expert Demonstration
Graphical user interface (GUI) agents have advanced rapidly but still struggle with complex tasks involving novel UI elements, long-horizon actions, and personalized trajectories. In this work, we introduce Instruction Agent, a GUI agent that leverages expert demonstrations to solve such tasks, enabling completion of otherwise difficult workflows. Given a single demonstration, the agent extracts step-by-step instructions and executes them by strictly following the trajectory intended by the user, which avoids making mistakes during execution. The agent leverages the verifier and backtracker modules further to improve robustness. Both modules are critical to understand the current outcome from each action and handle unexpected interruptions(such as pop-up windows) during execution. Our experiments show that Instruction Agent achieves a 60% success rate on a set of tasks in OSWorld that all top-ranked agents failed to complete. The Instruction Agent offers a practical and extensible framework, bridging the gap between current GUI agents and reliable real-world GUI task automation.
TeachMyAgent: a Benchmark for Automatic Curriculum Learning in Deep RL
Training autonomous agents able to generalize to multiple tasks is a key target of Deep Reinforcement Learning (DRL) research. In parallel to improving DRL algorithms themselves, Automatic Curriculum Learning (ACL) study how teacher algorithms can train DRL agents more efficiently by adapting task selection to their evolving abilities. While multiple standard benchmarks exist to compare DRL agents, there is currently no such thing for ACL algorithms. Thus, comparing existing approaches is difficult, as too many experimental parameters differ from paper to paper. In this work, we identify several key challenges faced by ACL algorithms. Based on these, we present TeachMyAgent (TA), a benchmark of current ACL algorithms leveraging procedural task generation. It includes 1) challenge-specific unit-tests using variants of a procedural Box2D bipedal walker environment, and 2) a new procedural Parkour environment combining most ACL challenges, making it ideal for global performance assessment. We then use TeachMyAgent to conduct a comparative study of representative existing approaches, showcasing the competitiveness of some ACL algorithms that do not use expert knowledge. We also show that the Parkour environment remains an open problem. We open-source our environments, all studied ACL algorithms (collected from open-source code or re-implemented), and DRL students in a Python package available at https://github.com/flowersteam/TeachMyAgent.


KwaiAgents: Generalized Information-seeking Agent System with Large Language Models
Driven by curiosity, humans have continually sought to explore and understand the world around them, leading to the invention of various tools to satiate this inquisitiveness. Despite not having the capacity to process and memorize vast amounts of information in their brains, humans excel in critical thinking, planning, reflection, and harnessing available tools to interact with and interpret the world, enabling them to find answers efficiently. The recent advancements in large language models (LLMs) suggest that machines might also possess the aforementioned human-like capabilities, allowing them to exhibit powerful abilities even with a constrained parameter count. In this paper, we introduce KwaiAgents, a generalized information-seeking agent system based on LLMs. Within KwaiAgents, we propose an agent system that employs LLMs as its cognitive core, which is capable of understanding a user's query, behavior guidelines, and referencing external documents. The agent can also update and retrieve information from its internal memory, plan and execute actions using a time-aware search-browse toolkit, and ultimately provide a comprehensive response. We further investigate the system's performance when powered by LLMs less advanced than GPT-4, and introduce the Meta-Agent Tuning (MAT) framework, designed to ensure even an open-sourced 7B or 13B model performs well among many agent systems. We exploit both benchmark and human evaluations to systematically validate these capabilities. Extensive experiments show the superiority of our agent system compared to other autonomous agents and highlight the enhanced generalized agent-abilities of our fine-tuned LLMs.
The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
This survey paper examines the recent advancements in AI agent implementations, with a focus on their ability to achieve complex goals that require enhanced reasoning, planning, and tool execution capabilities. The primary objectives of this work are to a) communicate the current capabilities and limitations of existing AI agent implementations, b) share insights gained from our observations of these systems in action, and c) suggest important considerations for future developments in AI agent design. We achieve this by providing overviews of single-agent and multi-agent architectures, identifying key patterns and divergences in design choices, and evaluating their overall impact on accomplishing a provided goal. Our contribution outlines key themes when selecting an agentic architecture, the impact of leadership on agent systems, agent communication styles, and key phases for planning, execution, and reflection that enable robust AI agent systems.


Language Instructed Reinforcement Learning for Human-AI Coordination
One of the fundamental quests of AI is to produce agents that coordinate well with humans. This problem is challenging, especially in domains that lack high quality human behavioral data, because multi-agent reinforcement learning (RL) often converges to different equilibria from the ones that humans prefer. We propose a novel framework, instructRL, that enables humans to specify what kind of strategies they expect from their AI partners through natural language instructions. We use pretrained large language models to generate a prior policy conditioned on the human instruction and use the prior to regularize the RL objective. This leads to the RL agent converging to equilibria that are aligned with human preferences. We show that instructRL converges to human-like policies that satisfy the given instructions in a proof-of-concept environment as well as the challenging Hanabi benchmark. Finally, we show that knowing the language instruction significantly boosts human-AI coordination performance in human evaluations in Hanabi.

Learning to Navigate the Web
Learning in environments with large state and action spaces, and sparse rewards, can hinder a Reinforcement Learning (RL) agent's learning through trial-and-error. For instance, following natural language instructions on the Web (such as booking a flight ticket) leads to RL settings where input vocabulary and number of actionable elements on a page can grow very large. Even though recent approaches improve the success rate on relatively simple environments with the help of human demonstrations to guide the exploration, they still fail in environments where the set of possible instructions can reach millions. We approach the aforementioned problems from a different perspective and propose guided RL approaches that can generate unbounded amount of experience for an agent to learn from. Instead of learning from a complicated instruction with a large vocabulary, we decompose it into multiple sub-instructions and schedule a curriculum in which an agent is tasked with a gradually increasing subset of these relatively easier sub-instructions. In addition, when the expert demonstrations are not available, we propose a novel meta-learning framework that generates new instruction following tasks and trains the agent more effectively. We train DQN, deep reinforcement learning agent, with Q-value function approximated with a novel QWeb neural network architecture on these smaller, synthetic instructions. We evaluate the ability of our agent to generalize to new instructions on World of Bits benchmark, on forms with up to 100 elements, supporting 14 million possible instructions. The QWeb agent outperforms the baseline without using any human demonstration achieving 100% success rate on several difficult environments.

Agent-Pro: Learning to Evolve via Policy-Level Reflection and Optimization
Large Language Models (LLMs) exhibit robust problem-solving capabilities for diverse tasks. However, most LLM-based agents are designed as specific task solvers with sophisticated prompt engineering, rather than agents capable of learning and evolving through interactions. These task solvers necessitate manually crafted prompts to inform task rules and regulate LLM behaviors, inherently incapacitating to address complex dynamic scenarios e.g., large interactive games. In light of this, we propose Agent-Pro: an LLM-based Agent with Policy-level Reflection and Optimization that can learn a wealth of expertise from interactive experiences and progressively elevate its behavioral policy. Specifically, it involves a dynamic belief generation and reflection process for policy evolution. Rather than action-level reflection, Agent-Pro iteratively reflects on past trajectories and beliefs, fine-tuning its irrational beliefs for a better policy. Moreover, a depth-first search is employed for policy optimization, ensuring continual enhancement in policy payoffs. Agent-Pro is evaluated across two games: Blackjack and Texas Hold'em, outperforming vanilla LLM and specialized models. Our results show Agent-Pro can learn and evolve in complex and dynamic scenes, which also benefits numerous LLM-based applications.

Proposer-Agent-Evaluator(PAE): Autonomous Skill Discovery For Foundation Model Internet Agents
The vision of a broadly capable and goal-directed agent, such as an Internet-browsing agent in the digital world and a household humanoid in the physical world, has rapidly advanced, thanks to the generalization capability of foundation models. Such a generalist agent needs to have a large and diverse skill repertoire, such as finding directions between two travel locations and buying specific items from the Internet. If each skill needs to be specified manually through a fixed set of human-annotated instructions, the agent's skill repertoire will necessarily be limited due to the quantity and diversity of human-annotated instructions. In this work, we address this challenge by proposing Proposer-Agent-Evaluator, an effective learning system that enables foundation model agents to autonomously discover and practice skills in the wild. At the heart of PAE is a context-aware task proposer that autonomously proposes tasks for the agent to practice with context information of the environment such as user demos or even just the name of the website itself for Internet-browsing agents. Then, the agent policy attempts those tasks with thoughts and actual grounded operations in the real world with resulting trajectories evaluated by an autonomous VLM-based success evaluator. The success evaluation serves as the reward signal for the agent to refine its policies through RL. We validate PAE on challenging vision-based web navigation, using both real-world and self-hosted websites from WebVoyager and WebArena.To the best of our knowledge, this work represents the first effective learning system to apply autonomous task proposal with RL for agents that generalizes real-world human-annotated benchmarks with SOTA performances. Our open-source checkpoints and code can be found in https://yanqval.github.io/PAE/

Can AI Master Econometrics? Evidence from Econometrics AI Agent on Expert-Level Tasks
Can AI effectively perform complex econometric analysis traditionally requiring human expertise? This paper evaluates an agentic AI's capability to master econometrics, focusing on empirical analysis performance. We develop an ``Econometrics AI Agent'' built on the open-source MetaGPT framework. This agent exhibits outstanding performance in: (1) planning econometric tasks strategically, (2) generating and executing code, (3) employing error-based reflection for improved robustness, and (4) allowing iterative refinement through multi-round conversations. We construct two datasets from academic coursework materials and published research papers to evaluate performance against real-world challenges. Comparative testing shows our domain-specialized agent significantly outperforms both benchmark large language models (LLMs) and general-purpose AI agents. This work establishes a testbed for exploring AI's impact on social science research and enables cost-effective integration of domain expertise, making advanced econometric methods accessible to users with minimal coding expertise. Furthermore, our agent enhances research reproducibility and offers promising pedagogical applications for econometrics teaching.
Tulip Agent -- Enabling LLM-Based Agents to Solve Tasks Using Large Tool Libraries
We introduce tulip agent, an architecture for autonomous LLM-based agents with Create, Read, Update, and Delete access to a tool library containing a potentially large number of tools. In contrast to state-of-the-art implementations, tulip agent does not encode the descriptions of all available tools in the system prompt, which counts against the model's context window, or embed the entire prompt for retrieving suitable tools. Instead, the tulip agent can recursively search for suitable tools in its extensible tool library, implemented exemplarily as a vector store. The tulip agent architecture significantly reduces inference costs, allows using even large tool libraries, and enables the agent to adapt and extend its set of tools. We evaluate the architecture with several ablation studies in a mathematics context and demonstrate its generalizability with an application to robotics. A reference implementation and the benchmark are available at github.com/HRI-EU/tulip_agent.

Training LLM-Based Agents with Synthetic Self-Reflected Trajectories and Partial Masking
Autonomous agents, which perceive environments and take actions to achieve goals, have become increasingly feasible with the advancements in large language models (LLMs). However, current powerful agents often depend on sophisticated prompt engineering combined with closed-source LLMs like GPT-4. Although training open-source LLMs using expert trajectories from teacher models has yielded some improvements in agent capabilities, this approach still faces limitations such as performance plateauing and error propagation. To mitigate these challenges, we propose STeP, a novel method for improving LLM-based agent training. We synthesize self-reflected trajectories that include reflections and corrections of error steps, which enhance the effectiveness of LLM agents in learning from teacher models, enabling them to become agents capable of self-reflecting and correcting. We also introduce partial masking strategy that prevents the LLM from internalizing incorrect or suboptimal steps. Experiments demonstrate that our method improves agent performance across three representative tasks: ALFWorld, WebShop, and SciWorld. For the open-source model LLaMA2-7B-Chat, when trained using self-reflected trajectories constructed with Qwen1.5-110B-Chat as the teacher model, it achieves comprehensive improvements with less training data compared to agents trained exclusively on expert trajectories.

Learning When to Plan: Efficiently Allocating Test-Time Compute for LLM Agents
Training large language models (LLMs) to reason via reinforcement learning (RL) significantly improves their problem-solving capabilities. In agentic settings, existing methods like ReAct prompt LLMs to explicitly plan before every action; however, we demonstrate that always planning is computationally expensive and degrades performance on long-horizon tasks, while never planning further limits performance. To address this, we introduce a conceptual framework formalizing dynamic planning for LLM agents, enabling them to flexibly decide when to allocate test-time compute for planning. We propose a simple two-stage training pipeline: (1) supervised fine-tuning on diverse synthetic data to prime models for dynamic planning, and (2) RL to refine this capability in long-horizon environments. Experiments on the Crafter environment show that dynamic planning agents trained with this approach are more sample-efficient and consistently achieve more complex objectives. Additionally, we demonstrate that these agents can be effectively steered by human-written plans, surpassing their independent capabilities. To our knowledge, this work is the first to explore training LLM agents for dynamic test-time compute allocation in sequential decision-making tasks, paving the way for more efficient, adaptive, and controllable agentic systems.
ScienceWorld: Is your Agent Smarter than a 5th Grader?
We present ScienceWorld, a benchmark to test agents' scientific reasoning abilities in a new interactive text environment at the level of a standard elementary school science curriculum. Despite the transformer-based progress seen in question-answering and scientific text processing, we find that current models cannot reason about or explain learned science concepts in novel contexts. For instance, models can easily answer what the conductivity of a known material is but struggle when asked how they would conduct an experiment in a grounded environment to find the conductivity of an unknown material. This begs the question of whether current models are simply retrieving answers by way of seeing a large number of similar examples or if they have learned to reason about concepts in a reusable manner. We hypothesize that agents need to be grounded in interactive environments to achieve such reasoning capabilities. Our experiments provide empirical evidence supporting this hypothesis -- showing that a 1.5 million parameter agent trained interactively for 100k steps outperforms a 11 billion parameter model statically trained for scientific question-answering and reasoning from millions of expert demonstrations.
Training Language Model Agents without Modifying Language Models
Researchers and practitioners have recently reframed powerful Large Language Models (LLMs) as agents, enabling them to automate complex tasks largely via the use of specialized functions. To facilitate the development of LLM agents, we present a novel paradigm of training LLM agents without modifying the LLM weights, which is particularly useful when the LLMs are difficult or inaccessible for modifications. Inspired by how humans continuously forge tools to adapt to real-world tasks, rather than change our biological structure to fit a static set of tools, we propose to progressively forge agent's functions to better solve the downstream tasks instead of modifying the LLM weights. By treating the functions as learnable `agent parameters' and leveraging the fundamental idea of model training in artificial intelligence, we develop AgentOptimizer that employs the LLM to update agents' functions and devise an agent training algorithm with two strategies, roll-back, and early-stop, to streamline the training process. With extensive experiments, we showcase that the agent training paradigm could significantly improve the performance of representative LLM agents in various downstream tasks. We also study the behavior of the agent training regarding aspects like the learning curve and domain transferability.





Automated Design of Agentic Systems
Researchers are investing substantial effort in developing powerful general-purpose agents, wherein Foundation Models are used as modules within agentic systems (e.g. Chain-of-Thought, Self-Reflection, Toolformer). However, the history of machine learning teaches us that hand-designed solutions are eventually replaced by learned solutions. We formulate a new research area, Automated Design of Agentic Systems (ADAS), which aims to automatically create powerful agentic system designs, including inventing novel building blocks and/or combining them in new ways. We further demonstrate that there is an unexplored yet promising approach within ADAS where agents can be defined in code and new agents can be automatically discovered by a meta agent programming ever better ones in code. Given that programming languages are Turing Complete, this approach theoretically enables the learning of any possible agentic system: including novel prompts, tool use, control flows, and combinations thereof. We present a simple yet effective algorithm named Meta Agent Search to demonstrate this idea, where a meta agent iteratively programs interesting new agents based on an ever-growing archive of previous discoveries. Through extensive experiments across multiple domains including coding, science, and math, we show that our algorithm can progressively invent agents with novel designs that greatly outperform state-of-the-art hand-designed agents. Importantly, we consistently observe the surprising result that agents invented by Meta Agent Search maintain superior performance even when transferred across domains and models, demonstrating their robustness and generality. Provided we develop it safely, our work illustrates the potential of an exciting new research direction toward automatically designing ever-more powerful agentic systems to benefit humanity.


Gödel Agent: A Self-Referential Agent Framework for Recursive Self-Improvement
The rapid advancement of large language models (LLMs) has significantly enhanced the capabilities of AI-driven agents across various tasks. However, existing agentic systems, whether based on fixed pipeline algorithms or pre-defined meta-learning frameworks, cannot search the whole agent design space due to the restriction of human-designed components, and thus might miss the globally optimal agent design. In this paper, we introduce G\"odel Agent, a self-evolving framework inspired by the G\"odel machine, enabling agents to recursively improve themselves without relying on predefined routines or fixed optimization algorithms. G\"odel Agent leverages LLMs to dynamically modify its own logic and behavior, guided solely by high-level objectives through prompting. Experimental results on mathematical reasoning and complex agent tasks demonstrate that implementation of G\"odel Agent can achieve continuous self-improvement, surpassing manually crafted agents in performance, efficiency, and generalizability.
WebDancer: Towards Autonomous Information Seeking Agency
Addressing intricate real-world problems necessitates in-depth information seeking and multi-step reasoning. Recent progress in agentic systems, exemplified by Deep Research, underscores the potential for autonomous multi-step research. In this work, we present a cohesive paradigm for building end-to-end agentic information seeking agents from a data-centric and training-stage perspective. Our approach consists of four key stages: (1) browsing data construction, (2) trajectories sampling, (3) supervised fine-tuning for effective cold start, and (4) reinforcement learning for enhanced generalisation. We instantiate this framework in a web agent based on the ReAct, WebDancer. Empirical evaluations on the challenging information seeking benchmarks, GAIA and WebWalkerQA, demonstrate the strong performance of WebDancer, achieving considerable results and highlighting the efficacy of our training paradigm. Further analysis of agent training provides valuable insights and actionable, systematic pathways for developing more capable agentic models. The codes and demo will be released in https://github.com/Alibaba-NLP/WebAgent.




MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowledge
Autonomous agents have made great strides in specialist domains like Atari games and Go. However, they typically learn tabula rasa in isolated environments with limited and manually conceived objectives, thus failing to generalize across a wide spectrum of tasks and capabilities. Inspired by how humans continually learn and adapt in the open world, we advocate a trinity of ingredients for building generalist agents: 1) an environment that supports a multitude of tasks and goals, 2) a large-scale database of multimodal knowledge, and 3) a flexible and scalable agent architecture. We introduce MineDojo, a new framework built on the popular Minecraft game that features a simulation suite with thousands of diverse open-ended tasks and an internet-scale knowledge base with Minecraft videos, tutorials, wiki pages, and forum discussions. Using MineDojo's data, we propose a novel agent learning algorithm that leverages large pre-trained video-language models as a learned reward function. Our agent is able to solve a variety of open-ended tasks specified in free-form language without any manually designed dense shaping reward. We open-source the simulation suite, knowledge bases, algorithm implementation, and pretrained models (https://minedojo.org) to promote research towards the goal of generally capable embodied agents.




Can Language Models Teach Weaker Agents? Teacher Explanations Improve Students via Theory of Mind
Large Language Models (LLMs) perform complex reasoning by generating explanations for their predictions. However, a complementary goal of explanations is to also communicate useful knowledge that improves weaker agents. Hence, we investigate whether LLMs also make good teachers for weaker agents. In particular, we consider a student-teacher framework between two LLM agents and study if, when, and how the teacher should intervene with natural language explanations to improve the student's performance. Since communication is expensive, we define a budget such that the teacher only communicates explanations for a fraction of the data, after which the student should perform well on its own. We decompose the teaching problem along four axes: (1) if teacher's test time intervention improve student predictions, (2) when it is worth explaining a data point, (3) how the teacher should personalize explanations to better teach the student, and (4) if teacher explanations also improve student performance on future unexplained data. We first show that teacher LLMs can indeed intervene on student reasoning to improve their performance. Next, we propose a Theory of Mind approach, in which the teacher builds two few-shot mental models of the student. The first model defines an Intervention Function that simulates the utility of an intervention, allowing the teacher to intervene when this utility is the highest and improving student performance at lower budgets. The second model enables the teacher to personalize explanations for a particular student and outperform unpersonalized teachers. We also demonstrate that in multi-turn interactions, teacher explanations generalize and learning from explained data improves student performance on future unexplained data. Finally, we also verify that misaligned teachers can lower student performance to random chance by intentionally misleading them.
MaskSearch: A Universal Pre-Training Framework to Enhance Agentic Search Capability
Retrieval-Augmented Language Models (RALMs) represent a classic paradigm where models enhance generative capabilities using external knowledge retrieved via a specialized module. Recent advancements in Agent techniques enable Large Language Models (LLMs) to autonomously utilize tools for retrieval, planning, and reasoning. While existing training-based methods show promise, their agentic abilities are limited by inherent characteristics of the task-specific data used during training. To further enhance the universal search capability of agents, we propose a novel pre-training framework, MaskSearch. In the pre-training stage, we introduce the Retrieval Augmented Mask Prediction (RAMP) task, where the model learns to leverage search tools to fill masked spans on a large number of pre-training data, thus acquiring universal retrieval and reasoning capabilities for LLMs. After that, the model is trained on downstream tasks to achieve further improvement. We apply both Supervised Fine-tuning (SFT) and Reinforcement Learning (RL) for training. For SFT, we combine agent-based and distillation-based methods to generate training data, starting with a multi-agent system consisting of a planner, rewriter, observer, and followed by a self-evolving teacher model. While for RL, we employ DAPO as the training framework and adopt a hybrid reward system consisting of answer rewards and format rewards. Additionally, we introduce a curriculum learning approach that allows the model to learn progressively from easier to more challenging instances based on the number of masked spans. We evaluate the effectiveness of our framework in the scenario of open-domain multi-hop question answering. Through extensive experiments, we demonstrate that MaskSearch significantly enhances the performance of LLM-based search agents on both in-domain and out-of-domain downstream tasks.
Chain-of-Agents: End-to-End Agent Foundation Models via Multi-Agent Distillation and Agentic RL
Recent advances in large language models (LLMs) and multi-agent systems have demonstrated remarkable capabilities in complex problem-solving tasks such as deep research, vibe coding, and mathematical reasoning. However, most existing multi-agent systems are built upon manual prompt/workflow engineering with sophisticated agent frameworks, making them computationally inefficient, less capable, and can not benefit from data-centric learning. In this work, we introduce Chain-of-Agents (CoA), a novel paradigm of LLM reasoning that enables native end-to-end complex problem-solving in the same way as a multi-agent system (i.e., multi-turn problem solving with multiple tools and multiple agents) within one model. In chain-of-agents problem-solving, the model dynamically activates different tool agents and role-playing agents to simulate multi-agent collaboration in an end-to-end fashion. To elicit end-to-end chain-of-agents problem-solving abilities in LLMs, we introduce a multi-agent distillation framework to distill state-of-the-art multi-agent systems into chain-of-agents trajectories for agentic supervised fine-tuning. We then use agentic reinforcement learning on verifiable agentic tasks to further improve the models' capabilities on chain-of-agents problem solving. We call the resulting models Agent Foundation Models (AFMs). Our empirical studies demonstrate that AFM establishes new state-of-the-art performance across diverse benchmarks in both web agent and code agent settings. We make the entire research, including the model weights, code for training and evaluation, and the training data, fully open-sourced, which offers a solid starting point for future research on agent models and agentic RL.





ALAS: Autonomous Learning Agent for Self-Updating Language Models
Large language models (LLMs) often have a fixed knowledge cutoff, limiting their accuracy on emerging information. We present ALAS (Autonomous Learning Agent System), a modular pipeline that continuously updates an LLM's knowledge with minimal human intervention. ALAS autonomously generates a learning curriculum for a target domain, retrieves up-to-date information from the web (with citations), distills this into question-answer training data, and fine-tunes the model through supervised fine-tuning (SFT) and direct preference optimization (DPO). It iteratively evaluates performance and revises the curriculum, enabling long-term continual learning. We demonstrate ALAS's ability to self-improve a model on rapidly evolving domains (e.g., new Python releases, latest security CVEs, academic trends), significantly boosting post-cutoff question answering accuracy (from 15% to 90% on average) without manual dataset curation. The system emphasizes modularity and reproducibility: each component (planning, retrieval, distillation, memory, fine-tuning) is interchangeable and built on standard APIs. We discuss comparative baselines (e.g., retrieval-augmented generation vs. fine-tuning) and show that ALAS achieves 90% accuracy on knowledge-updated queries with minimal engineering overhead. Finally, we outline limitations (cost, dependency on source quality) and future directions for autonomous lifelong learning in LLMs.
The Collaboration Gap
The trajectory of AI development suggests that we will increasingly rely on agent-based systems composed of independently developed agents with different information, privileges, and tools. The success of these systems will critically depend on effective collaboration among these heterogeneous agents, even under partial observability. Despite intense interest, few empirical studies have evaluated such agent-agent collaboration at scale. We propose a collaborative maze-solving benchmark that (i) isolates collaborative capabilities, (ii) modulates problem complexity, (iii) enables scalable automated grading, and (iv) imposes no output-format constraints, preserving ecological plausibility. Using this framework, we evaluate 32 leading open- and closed-source models in solo, homogeneous, and heterogeneous pairings. Our results reveal a "collaboration gap": models that perform well solo often degrade substantially when required to collaborate. Collaboration can break down dramatically; for instance, small distilled models that solve mazes well alone may fail almost completely in certain pairings. We find that starting with the stronger agent often improves outcomes, motivating a "relay inference" approach where the stronger agent leads before handing off to the weaker one, closing much of the gap. Our findings argue for (1) collaboration-aware evaluation, (2) training strategies developed to enhance collaborative capabilities, and (3) interaction design that reliably elicits agents' latent skills, guidance that applies to AI-AI and human-AI collaboration.

Defining and Detecting the Defects of the Large Language Model-based Autonomous Agents
AI agents are systems capable of perceiving their environment, autonomously planning and executing tasks. Recent advancements in LLM have introduced a transformative paradigm for AI agents, enabling them to interact with external resources and tools through prompts. In such agents, the workflow integrates developer-written code, which manages framework construction and logic control, with LLM-generated natural language that enhances dynamic decision-making and interaction. However, discrepancies between developer-implemented logic and the dynamically generated content of LLMs in terms of behavior and expected outcomes can lead to defects, such as tool invocation failures and task execution errors. These issues introduce specific risks, leading to various defects in LLM-based AI Agents, such as service interruptions. Despite the importance of these issues, there is a lack of systematic work that focuses on analyzing LLM-based AI Agents to uncover defects in their code. In this paper, we present the first study focused on identifying and detecting defects in LLM Agents. We collected and analyzed 6,854 relevant posts from StackOverflow to define 8 types of agent defects. For each type, we provided detailed descriptions with an example. Then, we designed a static analysis tool, named Agentable, to detect the defects. Agentable leverages Code Property Graphs and LLMs to analyze Agent workflows by efficiently identifying specific code patterns and analyzing natural language descriptions. To evaluate Agentable, we constructed two datasets: AgentSet, consists of 84 real-world Agents, and AgentTest, which contains 78 Agents specifically designed to include various types of defects. Our results show that Agentable achieved an overall accuracy of 88.79% and a recall rate of 91.03%. Furthermore, our analysis reveals the 889 defects of the AgentSet, highlighting the prevalence of these defects.
Prover Agent: An Agent-Based Framework for Formal Mathematical Proofs
We present Prover Agent, a novel AI agent for automated theorem proving that integrates large language models (LLMs) with a formal proof assistant, Lean. Prover Agent coordinates an informal reasoning LLM, a formal prover model, and feedback from Lean while also generating auxiliary lemmas. These auxiliary lemmas are not limited to subgoals in the formal proof but can also include special cases or potentially useful facts derived from the assumptions, which help in discovering a viable proof strategy. It achieves an 88.1% success rate on the MiniF2F benchmark, establishing a new state-of-the-art among methods using small language models (SLMs) with a much lower sample budget than previous approaches. We also present theoretical analyses and case studies that illustrate how these generated lemmas contribute to solving challenging problems. Our code is publicly available at: https://github.com/kAIto47802/Prover-Agent.

Situated Dialogue Learning through Procedural Environment Generation
We teach goal-driven agents to interactively act and speak in situated environments by training on generated curriculums. Our agents operate in LIGHT (Urbanek et al. 2019) -- a large-scale crowd-sourced fantasy text adventure game wherein an agent perceives and interacts with the world through textual natural language. Goals in this environment take the form of character-based quests, consisting of personas and motivations. We augment LIGHT by learning to procedurally generate additional novel textual worlds and quests to create a curriculum of steadily increasing difficulty for training agents to achieve such goals. In particular, we measure curriculum difficulty in terms of the rarity of the quest in the original training distribution -- an easier environment is one that is more likely to have been found in the unaugmented dataset. An ablation study shows that this method of learning from the tail of a distribution results in significantly higher generalization abilities as measured by zero-shot performance on never-before-seen quests.
Agent Data Protocol: Unifying Datasets for Diverse, Effective Fine-tuning of LLM Agents
Public research results on large-scale supervised finetuning of AI agents remain relatively rare, since the collection of agent training data presents unique challenges. In this work, we argue that the bottleneck is not a lack of underlying data sources, but that a large variety of data is fragmented across heterogeneous formats, tools, and interfaces. To this end, we introduce the agent data protocol (ADP), a light-weight representation language that serves as an "interlingua" between agent datasets in diverse formats and unified agent training pipelines downstream. The design of ADP is expressive enough to capture a large variety of tasks, including API/tool use, browsing, coding, software engineering, and general agentic workflows, while remaining simple to parse and train on without engineering at a per-dataset level. In experiments, we unified a broad collection of 13 existing agent training datasets into ADP format, and converted the standardized ADP data into training-ready formats for multiple agent frameworks. We performed SFT on these data, and demonstrated an average performance gain of ~20% over corresponding base models, and delivers state-of-the-art or near-SOTA performance on standard coding, browsing, tool use, and research benchmarks, without domain-specific tuning. All code and data are released publicly, in the hope that ADP could help lower the barrier to standardized, scalable, and reproducible agent training.

An Interactive Agent Foundation Model
The development of artificial intelligence systems is transitioning from creating static, task-specific models to dynamic, agent-based systems capable of performing well in a wide range of applications. We propose an Interactive Agent Foundation Model that uses a novel multi-task agent training paradigm for training AI agents across a wide range of domains, datasets, and tasks. Our training paradigm unifies diverse pre-training strategies, including visual masked auto-encoders, language modeling, and next-action prediction, enabling a versatile and adaptable AI framework. We demonstrate the performance of our framework across three separate domains -- Robotics, Gaming AI, and Healthcare. Our model demonstrates its ability to generate meaningful and contextually relevant outputs in each area. The strength of our approach lies in its generality, leveraging a variety of data sources such as robotics sequences, gameplay data, large-scale video datasets, and textual information for effective multimodal and multi-task learning. Our approach provides a promising avenue for developing generalist, action-taking, multimodal systems.





LearnAct: Few-Shot Mobile GUI Agent with a Unified Demonstration Benchmark
Mobile GUI agents show promise in automating tasks but face generalization challenges in diverse real-world scenarios. Traditional approaches using pre-training or fine-tuning with massive datasets struggle with the diversity of mobile applications and user-specific tasks. We propose enhancing mobile GUI agent capabilities through human demonstrations, focusing on improving performance in unseen scenarios rather than pursuing universal generalization through larger datasets. To realize this paradigm, we introduce LearnGUI, the first comprehensive dataset specifically designed for studying demonstration-based learning in mobile GUI agents, comprising 2,252 offline tasks and 101 online tasks with high-quality human demonstrations. We further develop LearnAct, a sophisticated multi-agent framework that automatically extracts knowledge from demonstrations to enhance task completion. This framework integrates three specialized agents: DemoParser for knowledge extraction, KnowSeeker for relevant knowledge retrieval, and ActExecutor for demonstration-enhanced task execution. Our experimental results show significant performance gains in both offline and online evaluations. In offline assessments, a single demonstration improves model performance, increasing Gemini-1.5-Pro's accuracy from 19.3% to 51.7%. In online evaluations, our framework enhances UI-TARS-7B-SFT's task success rate from 18.1% to 32.8%. LearnAct framework and LearnGUI benchmark establish demonstration-based learning as a promising direction for more adaptable, personalized, and deployable mobile GUI agents.





SFR-DeepResearch: Towards Effective Reinforcement Learning for Autonomously Reasoning Single Agents
Equipping large language models (LLMs) with complex, interleaved reasoning and tool-use capabilities has become a key focus in agentic AI research, especially with recent advances in reasoning-oriented (``thinking'') models. Such capabilities are key to unlocking a number of important applications. One such application is Deep Research (DR), which requires extensive search and reasoning over many sources. Our work in this paper focuses on the development of native Autonomous Single-Agent models for DR featuring minimal web crawling and Python tool integration. Unlike multi-agent systems, where agents take up pre-defined roles and are told what to do at each step in a static workflow, an autonomous single-agent determines its next action dynamically based on context, without manual directive. While prior work has proposed training recipes for base or instruction-tuned LLMs, we focus on continual reinforcement learning (RL) of reasoning-optimized models to further enhance agentic skills while preserving reasoning ability. Towards this end, we propose a simple RL recipe with entirely synthetic data, which we apply to various open-source LLMs. Our best variant SFR-DR-20B achieves up to 28.7% on Humanity's Last Exam benchmark. In addition, we conduct key analysis experiments to provide more insights into our methodologies.


Inducing Programmatic Skills for Agentic Tasks
To succeed in common digital tasks such as web navigation, agents must carry out a variety of specialized tasks such as searching for products or planning a travel route. To tackle these tasks, agents can bootstrap themselves by learning task-specific skills online through interaction with the web environment. In this work, we demonstrate that programs are an effective representation for skills. We propose agent skill induction (ASI), which allows agents to adapt themselves by inducing, verifying, and utilizing program-based skills on the fly. We start with an evaluation on the WebArena agent benchmark and show that ASI outperforms the static baseline agent and its text-skill counterpart by 23.5% and 11.3% in success rate, mainly thanks to the programmatic verification guarantee during the induction phase. ASI also improves efficiency by reducing 10.7-15.3% of the steps over baselines, by composing primitive actions (e.g., click) into higher-level skills (e.g., search product). We then highlight the efficacy of ASI in remaining efficient and accurate under scaled-up web activities. Finally, we examine the generalizability of induced skills when transferring between websites, and find that ASI can effectively reuse common skills, while also updating incompatible skills to versatile website changes.
Skill Machines: Temporal Logic Skill Composition in Reinforcement Learning
It is desirable for an agent to be able to solve a rich variety of problems that can be specified through language in the same environment. A popular approach towards obtaining such agents is to reuse skills learned in prior tasks to generalise compositionally to new ones. However, this is a challenging problem due to the curse of dimensionality induced by the combinatorially large number of ways high-level goals can be combined both logically and temporally in language. To address this problem, we propose a framework where an agent first learns a sufficient set of skill primitives to achieve all high-level goals in its environment. The agent can then flexibly compose them both logically and temporally to provably achieve temporal logic specifications in any regular language, such as regular fragments of linear temporal logic. This provides the agent with the ability to map from complex temporal logic task specifications to near-optimal behaviours zero-shot. We demonstrate this experimentally in a tabular setting, as well as in a high-dimensional video game and continuous control environment. Finally, we also demonstrate that the performance of skill machines can be improved with regular off-policy reinforcement learning algorithms when optimal behaviours are desired.
AgentInstruct: Toward Generative Teaching with Agentic Flows
Synthetic data is becoming increasingly important for accelerating the development of language models, both large and small. Despite several successful use cases, researchers also raised concerns around model collapse and drawbacks of imitating other models. This discrepancy can be attributed to the fact that synthetic data varies in quality and diversity. Effective use of synthetic data usually requires significant human effort in curating the data. We focus on using synthetic data for post-training, specifically creating data by powerful models to teach a new skill or behavior to another model, we refer to this setting as Generative Teaching. We introduce AgentInstruct, an extensible agentic framework for automatically creating large amounts of diverse and high-quality synthetic data. AgentInstruct can create both the prompts and responses, using only raw data sources like text documents and code files as seeds. We demonstrate the utility of AgentInstruct by creating a post training dataset of 25M pairs to teach language models different skills, such as text editing, creative writing, tool usage, coding, reading comprehension, etc. The dataset can be used for instruction tuning of any base model. We post-train Mistral-7b with the data. When comparing the resulting model Orca-3 to Mistral-7b-Instruct (which uses the same base model), we observe significant improvements across many benchmarks. For example, 40% improvement on AGIEval, 19% improvement on MMLU, 54% improvement on GSM8K, 38% improvement on BBH and 45% improvement on AlpacaEval. Additionally, it consistently outperforms other models such as LLAMA-8B-instruct and GPT-3.5-turbo.





WebArena: A Realistic Web Environment for Building Autonomous Agents
With generative AI advances, the exciting potential for autonomous agents to manage daily tasks via natural language commands has emerged. However, cur rent agents are primarily created and tested in simplified synthetic environments, substantially limiting real-world scenario representation. In this paper, we build an environment for agent command and control that is highly realistic and reproducible. Specifically, we focus on agents that perform tasks on websites, and we create an environment with fully functional websites from four common domains: e-commerce, social forum discussions, collaborative software development, and content management. Our environment is enriched with tools (e.g., a map) and external knowledge bases (e.g., user manuals) to encourage human-like task-solving. Building upon our environment, we release a set of benchmark tasks focusing on evaluating the functional correctness of task completions. The tasks in our benchmark are diverse, long-horizon, and are designed to emulate tasks that humans routinely perform on the internet. We design and implement several autonomous agents, integrating recent techniques such as reasoning before acting. The results demonstrate that solving complex tasks is challenging: our best GPT-4-based agent only achieves an end-to-end task success rate of 10.59%. These results highlight the need for further development of robust agents, that current state-of-the-art LMs are far from perfect performance in these real-life tasks, and that WebArena can be used to measure such progress. Our code, data, environment reproduction resources, and video demonstrations are publicly available at https://webarena.dev/.





ProAgent: Building Proactive Cooperative AI with Large Language Models
Building AIs with adaptive behaviors in human-AI cooperation stands as a pivotal focus in AGI research. Current methods for developing cooperative agents predominantly rely on learning-based methods, where policy generalization heavily hinges on past interactions with specific teammates. These approaches constrain the agent's capacity to recalibrate its strategy when confronted with novel teammates. We propose ProAgent, a novel framework that harnesses large language models (LLMs) to fashion a proactive agent empowered with the ability to anticipate teammates' forthcoming decisions and formulate enhanced plans for itself. ProAgent excels at cooperative reasoning with the capacity to dynamically adapt its behavior to enhance collaborative efforts with teammates. Moreover, the ProAgent framework exhibits a high degree of modularity and interpretability, facilitating seamless integration to address a wide array of coordination scenarios. Experimental evaluations conducted within the framework of Overcook-AI unveil the remarkable performance superiority of ProAgent, outperforming five methods based on self-play and population-based training in cooperation with AI agents. Further, when cooperating with human proxy models, its performance exhibits an average improvement exceeding 10\% compared to the current state-of-the-art, COLE. The advancement was consistently observed across diverse scenarios involving interactions with both AI agents of varying characteristics and human counterparts. These findings inspire future research for human-robot collaborations. For a hands-on demonstration, please visit https://pku-proagent.github.io.



Thespian: Multi-Character Text Role-Playing Game Agents
Text-adventure games and text role-playing games are grand challenges for reinforcement learning game playing agents. Text role-playing games are open-ended environments where an agent must faithfully play a particular character. We consider the distinction between characters and actors, where an actor agent has the ability to play multiple characters. We present a framework we call a thespian agent that can learn to emulate multiple characters along with a soft prompt that can be used to direct it as to which character to play at any time. We further describe an attention mechanism that allows the agent to learn new characters that are based on previously learned characters in a few-shot fashion. We show that our agent outperforms the state of the art agent framework in multi-character learning and few-shot learning.
Empowering Large Language Model Agents through Action Learning
Large Language Model (LLM) Agents have recently garnered increasing interest yet they are limited in their ability to learn from trial and error, a key element of intelligent behavior. In this work, we argue that the capacity to learn new actions from experience is fundamental to the advancement of learning in LLM agents. While humans naturally expand their action spaces and develop skills through experiential learning, LLM agents typically operate within fixed action spaces, limiting their potential for growth. To address these challenges, our study explores open-action learning for language agents. We introduce a framework LearnAct with an iterative learning strategy to create and improve actions in the form of Python functions. In each iteration, LLM revises and updates the currently available actions based on the errors identified in unsuccessful training tasks, thereby enhancing action effectiveness. Our experimental evaluations across Robotic Planning and Alfworld environments reveal that after learning on a few training task instances, our approach to open-action learning markedly improves agent performance for the type of task (by 32 percent in AlfWorld compared to ReAct+Reflexion, for instance) highlighting the importance of experiential action learning in the development of more intelligent LLM agents.

Building Open-Ended Embodied Agent via Language-Policy Bidirectional Adaptation
Building open-ended learning agents involves challenges in pre-trained language model (LLM) and reinforcement learning (RL) approaches. LLMs struggle with context-specific real-time interactions, while RL methods face efficiency issues for exploration. To this end, we propose OpenContra, a co-training framework that cooperates LLMs and GRL to construct an open-ended agent capable of comprehending arbitrary human instructions. The implementation comprises two stages: (1) fine-tuning an LLM to translate human instructions into structured goals, and curriculum training a goal-conditioned RL policy to execute arbitrary goals; (2) collaborative training to make the LLM and RL policy learn to adapt each, achieving open-endedness on instruction space. We conduct experiments on Contra, a battle royale FPS game with a complex and vast goal space. The results show that an agent trained with OpenContra comprehends arbitrary human instructions and completes goals with a high completion ratio, which proves that OpenContra may be the first practical solution for constructing open-ended embodied agents.
Efficient Agent Training for Computer Use
Scaling up high-quality trajectory data has long been a critical bottleneck for developing human-like computer use agents. We introduce PC Agent-E, an efficient agent training framework that significantly reduces reliance on large-scale human demonstrations. Starting with just 312 human-annotated computer use trajectories, we further improved data quality by synthesizing diverse action decisions with Claude 3.7 Sonnet. Trained on these enriched trajectories, our PC Agent-E model achieved a remarkable 141% relative improvement, surpassing the strong Claude 3.7 Sonnet with extended thinking on WindowsAgentArena-V2, an improved benchmark we also released. Furthermore, PC Agent-E demonstrates strong generalizability to different operating systems on OSWorld. Our findings suggest that strong computer use capabilities can be stimulated from a small amount of high-quality trajectory data.



AgentDistill: Training-Free Agent Distillation with Generalizable MCP Boxes
While knowledge distillation has become a mature field for compressing large language models (LLMs) into smaller ones by aligning their outputs or internal representations, the distillation of LLM-based agents, which involve planning, memory, and tool use, remains relatively underexplored. Existing agent distillation methods typically replay full teacher trajectories or imitate step-by-step teacher tool usage, but they often struggle to train student agents to dynamically plan and act in novel environments. We propose AgentDistill, a novel, training-free agent distillation framework that enables efficient and scalable knowledge transfer via direct reuse of Model-Context-Protocols (MCPs), which are structured and reusable task-solving modules autonomously generated by teacher agents. The reuse of these distilled MCPs enables student agents to generalize their capabilities across domains and solve new problems with minimal supervision or human intervention. Experiments on biomedical and mathematical benchmarks demonstrate that our distilled student agents, built on small language models, can achieve performance comparable to advanced systems using large LLMs such as OctoTools (GPT-4o), highlighting the effectiveness of our framework in building scalable and cost-efficient intelligent agents.


L0: Reinforcement Learning to Become General Agents
Training large language models (LLMs) to act as autonomous agents for multi-turn, long-horizon tasks remains significant challenges in scalability and training efficiency. To address this, we introduce L-Zero (L0), a scalable, end-to-end training pipeline for general-purpose agents. Featuring a low-cost, extensible, and sandboxed concurrent agent worker pool, L0 lowers the barrier for applying reinforcement learning in complex environments. We also introduce NB-Agent, the agent scaffold within L0, which operates in a "code-as-action" fashion via a Read-Eval-Print-Loop (REPL). We evaluate L0 on factuality question-answering benchmarks. Our experiments demonstrate that a base model can develop robust problem-solving skills using solely Reinforcement Learning with Verifiable Rewards (RLVR). On the Qwen2.5-7B-Instruct model, our method boosts accuracy on SimpleQA from 30 % to 80 % and on HotpotQA from 22 % to 41 %. We have open-sourced the entire L0 system, including our L0 series models, the NB-Agent, a complete training pipeline, and the corresponding training recipes on (https://github.com/cmriat/l0).
Bel Esprit: Multi-Agent Framework for Building AI Model Pipelines
As the demand for artificial intelligence (AI) grows to address complex real-world tasks, single models are often insufficient, requiring the integration of multiple models into pipelines. This paper introduces Bel Esprit, a conversational agent designed to construct AI model pipelines based on user-defined requirements. Bel Esprit employs a multi-agent framework where subagents collaborate to clarify requirements, build, validate, and populate pipelines with appropriate models. We demonstrate the effectiveness of this framework in generating pipelines from ambiguous user queries, using both human-curated and synthetic data. A detailed error analysis highlights ongoing challenges in pipeline construction. Bel Esprit is available for a free trial at https://belesprit.aixplain.com.

Open-Ended Learning Leads to Generally Capable Agents
In this work we create agents that can perform well beyond a single, individual task, that exhibit much wider generalisation of behaviour to a massive, rich space of challenges. We define a universe of tasks within an environment domain and demonstrate the ability to train agents that are generally capable across this vast space and beyond. The environment is natively multi-agent, spanning the continuum of competitive, cooperative, and independent games, which are situated within procedurally generated physical 3D worlds. The resulting space is exceptionally diverse in terms of the challenges posed to agents, and as such, even measuring the learning progress of an agent is an open research problem. We propose an iterative notion of improvement between successive generations of agents, rather than seeking to maximise a singular objective, allowing us to quantify progress despite tasks being incomparable in terms of achievable rewards. We show that through constructing an open-ended learning process, which dynamically changes the training task distributions and training objectives such that the agent never stops learning, we achieve consistent learning of new behaviours. The resulting agent is able to score reward in every one of our humanly solvable evaluation levels, with behaviour generalising to many held-out points in the universe of tasks. Examples of this zero-shot generalisation include good performance on Hide and Seek, Capture the Flag, and Tag. Through analysis and hand-authored probe tasks we characterise the behaviour of our agent, and find interesting emergent heuristic behaviours such as trial-and-error experimentation, simple tool use, option switching, and cooperation. Finally, we demonstrate that the general capabilities of this agent could unlock larger scale transfer of behaviour through cheap finetuning.
EnvGen: Generating and Adapting Environments via LLMs for Training Embodied Agents
Recent SOTA approaches for embodied learning via interaction directly employ large language models (LLMs) as agents to determine the next steps in an environment. Due to their world knowledge and reasoning capabilities, LLM agents achieve stronger performance than previous smaller agents based on reinforcement learning (RL); however, frequently calling LLMs is slow and expensive. Instead of directly employing LLMs as agents, can we use LLMs' reasoning capabilities to adaptively create training environments to help smaller embodied RL agents learn useful skills that they are weak at? We propose EnvGen, a novel framework to address this question. First, we prompt an LLM to generate training environments that allow agents to quickly learn different tasks in parallel. Concretely, the LLM is given the task description and simulator objectives that the agents should learn and is then asked to generate a set of environment configurations (e.g., different terrains, items given to agents, etc.). Next, we train a small RL agent in a mixture of the original and LLM-generated environments. Then, we enable the LLM to continuously adapt the generated environments to progressively improve the skills that the agent is weak at, by providing feedback to the LLM in the form of the agent's performance. We demonstrate the usefulness of EnvGen with comprehensive experiments in Crafter and Heist environments. We find that a small RL agent trained with EnvGen can outperform SOTA methods, including a GPT-4 agent, and learns long-horizon tasks significantly faster. We show qualitatively how the LLM adapts training environments to help improve RL agents' weaker skills over time. Additionally, EnvGen is substantially more efficient as it only uses a small number of LLM calls (e.g., 4 in total), whereas LLM agents require thousands of LLM calls. Lastly, we present detailed ablation studies for our design choices.


Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
A key method for creating Artificial Intelligence (AI) agents is Reinforcement Learning (RL). However, constructing a standalone RL policy that maps perception to action directly encounters severe problems, chief among them being its lack of generality across multiple tasks and the need for a large amount of training data. The leading cause is that it cannot effectively integrate prior information into the perception-action cycle when devising the policy. Large language models (LLMs) emerged as a fundamental way to incorporate cross-domain knowledge into AI agents but lack crucial learning and adaptation toward specific decision problems. This paper presents a general framework model for integrating and learning structured reasoning into AI agents' policies. Our methodology is motivated by the modularity found in the human brain. The framework utilises the construction of intrinsic and extrinsic functions to add previous understandings of reasoning structures. It also provides the adaptive ability to learn models inside every module or function, consistent with the modular structure of cognitive processes. We describe the framework in-depth and compare it with other AI pipelines and existing frameworks. The paper explores practical applications, covering experiments that show the effectiveness of our method. Our results indicate that AI agents perform and adapt far better when organised reasoning and prior knowledge are embedded. This opens the door to more resilient and general AI agent systems.




ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Given a simple request like Put a washed apple in the kitchen fridge, humans can reason in purely abstract terms by imagining action sequences and scoring their likelihood of success, prototypicality, and efficiency, all without moving a muscle. Once we see the kitchen in question, we can update our abstract plans to fit the scene. Embodied agents require the same abilities, but existing work does not yet provide the infrastructure necessary for both reasoning abstractly and executing concretely. We address this limitation by introducing ALFWorld, a simulator that enables agents to learn abstract, text based policies in TextWorld (C\^ot\'e et al., 2018) and then execute goals from the ALFRED benchmark (Shridhar et al., 2020) in a rich visual environment. ALFWorld enables the creation of a new BUTLER agent whose abstract knowledge, learned in TextWorld, corresponds directly to concrete, visually grounded actions. In turn, as we demonstrate empirically, this fosters better agent generalization than training only in the visually grounded environment. BUTLER's simple, modular design factors the problem to allow researchers to focus on models for improving every piece of the pipeline (language understanding, planning, navigation, and visual scene understanding).
CGMI: Configurable General Multi-Agent Interaction Framework
Benefiting from the powerful capabilities of large language models (LLMs), agents based on LLMs have shown the potential to address domain-specific tasks and emulate human behaviors. However, the content generated by these agents remains somewhat superficial, owing to their limited domain expertise and the absence of an effective cognitive architecture. To address this, we present the Configurable General Multi-Agent Interaction (CGMI) framework, designed to replicate human interactions in real-world scenarios. Specifically, we propose a tree-structured methodology for the assignment, detection, and maintenance of agent personality. Additionally, we designed a cognitive architecture equipped with a skill library based on the ACT* model, which contains memory, reflection, and planning modules. We have also integrated general agents to augment the virtual environment's realism. Using the CGMI framework, we simulated numerous classroom interactions between teacher and students. The experiments indicate that aspects such as the teaching methodology, curriculum, and student performance closely mirror real classroom settings. We will open source our work.
Language Models can Solve Computer Tasks
Agents capable of carrying out general tasks on a computer can improve efficiency and productivity by automating repetitive tasks and assisting in complex problem-solving. Ideally, such agents should be able to solve new computer tasks presented to them through natural language commands. However, previous approaches to this problem require large amounts of expert demonstrations and task-specific reward functions, both of which are impractical for new tasks. In this work, we show that a pre-trained large language model (LLM) agent can execute computer tasks guided by natural language using a simple prompting scheme where the agent Recursively Criticizes and Improves its output (RCI). The RCI approach significantly outperforms existing LLM methods for automating computer tasks and surpasses supervised learning (SL) and reinforcement learning (RL) approaches on the MiniWoB++ benchmark. We compare multiple LLMs and find that RCI with the InstructGPT-3+RLHF LLM is state-of-the-art on MiniWoB++, using only a handful of demonstrations per task rather than tens of thousands, and without a task-specific reward function. Furthermore, we demonstrate RCI prompting's effectiveness in enhancing LLMs' reasoning abilities on a suite of natural language reasoning tasks, outperforming chain of thought (CoT) prompting. We find that RCI combined with CoT performs better than either separately. Our code can be found here: https://github.com/posgnu/rci-agent.
xLAM: A Family of Large Action Models to Empower AI Agent Systems
Autonomous agents powered by large language models (LLMs) have attracted significant research interest. However, the open-source community faces many challenges in developing specialized models for agent tasks, driven by the scarcity of high-quality agent datasets and the absence of standard protocols in this area. We introduce and publicly release xLAM, a series of large action models designed for AI agent tasks. The xLAM series includes five models with both dense and mixture-of-expert architectures, ranging from 1B to 8x22B parameters, trained using a scalable, flexible pipeline that unifies, augments, and synthesizes diverse datasets to enhance AI agents' generalizability and performance across varied environments. Our experimental results demonstrate that xLAM consistently delivers exceptional performance across multiple agent ability benchmarks, notably securing the 1st position on the Berkeley Function-Calling Leaderboard, outperforming GPT-4, Claude-3, and many other models in terms of tool use. By releasing the xLAM series, we aim to advance the performance of open-source LLMs for autonomous AI agents, potentially accelerating progress and democratizing access to high-performance models for agent tasks. Models are available at https://huggingface.co/collections/Salesforce/xlam-models-65f00e2a0a63bbcd1c2dade4





Learning to Use Tools via Cooperative and Interactive Agents
Tool learning empowers large language models (LLMs) as agents to use external tools to extend their capability. Existing methods employ one single LLM-based agent to iteratively select and execute tools, thereafter incorporating the result into the next action prediction. However, they still suffer from potential performance degradation when addressing complex tasks due to: (1) the limitation of the inherent capability of a single LLM to perform diverse actions, and (2) the struggle to adaptively correct mistakes when the task fails. To mitigate these problems, we propose the ConAgents, a Cooperative and interactive Agents framework, which modularizes the workflow of tool learning into Grounding, Execution, and Observing agents. We also introduce an iterative calibration (IterCali) method, enabling the agents to adapt themselves based on the feedback from the tool environment. Experiments conducted on three datasets demonstrate the superiority of our ConAgents (e.g., 6 point improvement over the SOTA baseline). We further provide fine-granularity analysis for the efficiency and consistency of our framework.
Using Generative AI and Multi-Agents to Provide Automatic Feedback
This study investigates the use of generative AI and multi-agent systems to provide automatic feedback in educational contexts, particularly for student constructed responses in science assessments. The research addresses a key gap in the field by exploring how multi-agent systems, called AutoFeedback, can improve the quality of GenAI-generated feedback, overcoming known issues such as over-praise and over-inference that are common in single-agent large language models (LLMs). The study developed a multi-agent system consisting of two AI agents: one for generating feedback and another for validating and refining it. The system was tested on a dataset of 240 student responses, and its performance was compared to that of a single-agent LLM. Results showed that AutoFeedback significantly reduced the occurrence of over-praise and over-inference errors, providing more accurate and pedagogically sound feedback. The findings suggest that multi-agent systems can offer a more reliable solution for generating automated feedback in educational settings, highlighting their potential for scalable and personalized learning support. These results have important implications for educators and researchers seeking to leverage AI in formative assessments, offering a pathway to more effective feedback mechanisms that enhance student learning outcomes.

Knowledge-enhanced Agents for Interactive Text Games
Communication via natural language is a crucial aspect of intelligence, and it requires computational models to learn and reason about world concepts, with varying levels of supervision. While there has been significant progress made on fully-supervised non-interactive tasks, such as question-answering and procedural text understanding, much of the community has turned to various sequential interactive tasks, as in semi-Markov text-based games, which have revealed limitations of existing approaches in terms of coherence, contextual awareness, and their ability to learn effectively from the environment. In this paper, we propose a framework for enabling improved functional grounding of agents in text-based games. Specifically, we consider two forms of domain knowledge that we inject into learning-based agents: memory of previous correct actions and affordances of relevant objects in the environment. Our framework supports three representative model classes: `pure' reinforcement learning (RL) agents, RL agents enhanced with knowledge graphs, and agents equipped with language models. Furthermore, we devise multiple injection strategies for the above domain knowledge types and agent architectures, including injection via knowledge graphs and augmentation of the existing input encoding strategies. We perform all experiments on the ScienceWorld text-based game environment, to illustrate the performance of various model configurations in challenging science-related instruction-following tasks. Our findings provide crucial insights on the development of effective natural language processing systems for interactive contexts.



ELLA: Exploration through Learned Language Abstraction
Building agents capable of understanding language instructions is critical to effective and robust human-AI collaboration. Recent work focuses on training these agents via reinforcement learning in environments with synthetic language; however, instructions often define long-horizon, sparse-reward tasks, and learning policies requires many episodes of experience. We introduce ELLA: Exploration through Learned Language Abstraction, a reward shaping approach geared towards boosting sample efficiency in sparse reward environments by correlating high-level instructions with simpler low-level constituents. ELLA has two key elements: 1) A termination classifier that identifies when agents complete low-level instructions, and 2) A relevance classifier that correlates low-level instructions with success on high-level tasks. We learn the termination classifier offline from pairs of instructions and terminal states. Notably, in departure from prior work in language and abstraction, we learn the relevance classifier online, without relying on an explicit decomposition of high-level instructions to low-level instructions. On a suite of complex BabyAI environments with varying instruction complexities and reward sparsity, ELLA shows gains in sample efficiency relative to language-based shaping and traditional RL methods.

Exploring Large Language Model based Intelligent Agents: Definitions, Methods, and Prospects
Intelligent agents stand out as a potential path toward artificial general intelligence (AGI). Thus, researchers have dedicated significant effort to diverse implementations for them. Benefiting from recent progress in large language models (LLMs), LLM-based agents that use universal natural language as an interface exhibit robust generalization capabilities across various applications -- from serving as autonomous general-purpose task assistants to applications in coding, social, and economic domains, LLM-based agents offer extensive exploration opportunities. This paper surveys current research to provide an in-depth overview of LLM-based intelligent agents within single-agent and multi-agent systems. It covers their definitions, research frameworks, and foundational components such as their composition, cognitive and planning methods, tool utilization, and responses to environmental feedback. We also delve into the mechanisms of deploying LLM-based agents in multi-agent systems, including multi-role collaboration, message passing, and strategies to alleviate communication issues between agents. The discussions also shed light on popular datasets and application scenarios. We conclude by envisioning prospects for LLM-based agents, considering the evolving landscape of AI and natural language processing.

Synthesizing Agentic Data for Web Agents with Progressive Difficulty Enhancement Mechanisms
Web-based 'deep research' agents aim to solve complex question - answering tasks through long-horizon interactions with online tools. These tasks remain challenging, as the underlying language models are often not optimized for long-horizon reasoning and exploration. Prior work has proposed workflows for constructing instruction-tuning datasets, often leveraging knowledge graphs. However, such methods typically lack fine-grained control over difficulty and quality, yielding synthetic data that falls short of capturing the complexity required for long-horizon reasoning. Furthermore, many studies conflate data and training effects by comparing models trained under different optimization recipes, making it difficult to isolate and evaluate the effectiveness of the data itself. We introduce a two-pronged data synthesis pipeline that generates question - answer pairs by progressively increasing task complexity until a frontier baseline web agent fails. The baseline agent plays multiple roles in this process: attempting the questions, validating factuality, checking for alternative answers, and enforcing filtering. To evaluate the effectiveness of our synthesis methods, we adopt a controlled training setup based on distillation from strong web agents. Experiments across multiple web-based benchmarks show that our dataset - despite being smaller - enables the training of more effective web agents than existing datasets. In particular, our data exhibits twice the diversity in tool-use actions, allowing models trained on it to achieve stronger performance while avoiding repetitive tool-calling behaviors.

Simulating Classroom Education with LLM-Empowered Agents
Large language models (LLMs) have been employed in various intelligent educational tasks to assist teaching. While preliminary explorations have focused on independent LLM-empowered agents for specific educational tasks, the potential for LLMs within a multi-agent collaborative framework to simulate a classroom with real user participation remains unexplored. In this work, we propose SimClass, a multi-agent classroom simulation framework involving user participation. We recognize representative class roles and introduce a novel class control mechanism for automatic classroom teaching, and conduct user experiments in two real-world courses. Utilizing the Flanders Interactive Analysis System and Community of Inquiry theoretical frame works from educational analysis, we demonstrate that LLMs can simulate traditional classroom interaction patterns effectively while enhancing user's experience. We also observe emergent group behaviors among agents in SimClass, where agents collaborate to create enlivening interactions in classrooms to improve user learning process. We hope this work pioneers the application of LLM-empowered multi-agent systems in virtual classroom teaching.




Husky: A Unified, Open-Source Language Agent for Multi-Step Reasoning
Language agents perform complex tasks by using tools to execute each step precisely. However, most existing agents are based on proprietary models or designed to target specific tasks, such as mathematics or multi-hop question answering. We introduce Husky, a holistic, open-source language agent that learns to reason over a unified action space to address a diverse set of complex tasks involving numerical, tabular, and knowledge-based reasoning. Husky iterates between two stages: 1) generating the next action to take towards solving a given task and 2) executing the action using expert models and updating the current solution state. We identify a thorough ontology of actions for addressing complex tasks and curate high-quality data to train expert models for executing these actions. Our experiments show that Husky outperforms prior language agents across 14 evaluation datasets. Moreover, we introduce HuskyQA, a new evaluation set which stress tests language agents for mixed-tool reasoning, with a focus on retrieving missing knowledge and performing numerical reasoning. Despite using 7B models, Husky matches or even exceeds frontier LMs such as GPT-4 on these tasks, showcasing the efficacy of our holistic approach in addressing complex reasoning problems. Our code and models are available at https://github.com/agent-husky/Husky-v1.



Scaling Instructable Agents Across Many Simulated Worlds
Building embodied AI systems that can follow arbitrary language instructions in any 3D environment is a key challenge for creating general AI. Accomplishing this goal requires learning to ground language in perception and embodied actions, in order to accomplish complex tasks. The Scalable, Instructable, Multiworld Agent (SIMA) project tackles this by training agents to follow free-form instructions across a diverse range of virtual 3D environments, including curated research environments as well as open-ended, commercial video games. Our goal is to develop an instructable agent that can accomplish anything a human can do in any simulated 3D environment. Our approach focuses on language-driven generality while imposing minimal assumptions. Our agents interact with environments in real-time using a generic, human-like interface: the inputs are image observations and language instructions and the outputs are keyboard-and-mouse actions. This general approach is challenging, but it allows agents to ground language across many visually complex and semantically rich environments while also allowing us to readily run agents in new environments. In this paper we describe our motivation and goal, the initial progress we have made, and promising preliminary results on several diverse research environments and a variety of commercial video games.



Countering Language Drift with Seeded Iterated Learning
Pretraining on human corpus and then finetuning in a simulator has become a standard pipeline for training a goal-oriented dialogue agent. Nevertheless, as soon as the agents are finetuned to maximize task completion, they suffer from the so-called language drift phenomenon: they slowly lose syntactic and semantic properties of language as they only focus on solving the task. In this paper, we propose a generic approach to counter language drift called Seeded iterated learning (SIL). We periodically refine a pretrained student agent by imitating data sampled from a newly generated teacher agent. At each time step, the teacher is created by copying the student agent, before being finetuned to maximize task completion. SIL does not require external syntactic constraint nor semantic knowledge, making it a valuable task-agnostic finetuning protocol. We evaluate SIL in a toy-setting Lewis Game, and then scale it up to the translation game with natural language. In both settings, SIL helps counter language drift as well as it improves the task completion compared to baselines.


Learning on the Job: Test-Time Curricula for Targeted Reinforcement Learning
Humans are good at learning on the job: We learn how to solve the tasks we face as we go along. Can a model do the same? We propose an agent that assembles a task-specific curriculum, called test-time curriculum (TTC-RL), and applies reinforcement learning to continue training the model for its target task. The test-time curriculum avoids time-consuming human curation of datasets by automatically selecting the most task-relevant data from a large pool of available training data. Our experiments demonstrate that reinforcement learning on a test-time curriculum consistently improves the model on its target tasks, across a variety of evaluations and models. Notably, on challenging math and coding benchmarks, TTC-RL improves the pass@1 of Qwen3-8B by approximately 1.8x on AIME25 and 2.1x on CodeElo. Moreover, we find that TTC-RL significantly raises the performance ceiling compared to the initial model, increasing pass@8 on AIME25 from 40% to 62% and on CodeElo from 28% to 43%. Our findings show the potential of test-time curricula in extending the test-time scaling paradigm to continual training on thousands of task-relevant experiences during test-time.
Book2Dial: Generating Teacher-Student Interactions from Textbooks for Cost-Effective Development of Educational Chatbots
Educational chatbots are a promising tool for assisting student learning. However, the development of effective chatbots in education has been challenging, as high-quality data is seldom available in this domain. In this paper, we propose a framework for generating synthetic teacher-student interactions grounded in a set of textbooks. Our approaches capture one aspect of learning interactions where curious students with partial knowledge interactively ask a teacher questions about the material in the textbook. We highlight various quality criteria that such dialogues should fulfill and compare several approaches relying on either prompting or fine-tuning large language models. We use synthetic dialogues to train educational chatbots and show benefits of further fine-tuning in different educational domains. However, human evaluation shows that our best data synthesis method still suffers from hallucinations and tends to reiterate information from previous conversations. Our findings offer insights for future efforts in synthesizing conversational data that strikes a balance between size and quality. We will open-source our data and code.

From MOOC to MAIC: Reshaping Online Teaching and Learning through LLM-driven Agents
Since the first instances of online education, where courses were uploaded to accessible and shared online platforms, this form of scaling the dissemination of human knowledge to reach a broader audience has sparked extensive discussion and widespread adoption. Recognizing that personalized learning still holds significant potential for improvement, new AI technologies have been continuously integrated into this learning format, resulting in a variety of educational AI applications such as educational recommendation and intelligent tutoring. The emergence of intelligence in large language models (LLMs) has allowed for these educational enhancements to be built upon a unified foundational model, enabling deeper integration. In this context, we propose MAIC (Massive AI-empowered Course), a new form of online education that leverages LLM-driven multi-agent systems to construct an AI-augmented classroom, balancing scalability with adaptivity. Beyond exploring the conceptual framework and technical innovations, we conduct preliminary experiments at Tsinghua University, one of China's leading universities. Drawing from over 100,000 learning records of more than 500 students, we obtain a series of valuable observations and initial analyses. This project will continue to evolve, ultimately aiming to establish a comprehensive open platform that supports and unifies research, technology, and applications in exploring the possibilities of online education in the era of large model AI. We envision this platform as a collaborative hub, bringing together educators, researchers, and innovators to collectively explore the future of AI-driven online education.



Professional Agents -- Evolving Large Language Models into Autonomous Experts with Human-Level Competencies
The advent of large language models (LLMs) such as ChatGPT, PaLM, and GPT-4 has catalyzed remarkable advances in natural language processing, demonstrating human-like language fluency and reasoning capacities. This position paper introduces the concept of Professional Agents (PAgents), an application framework harnessing LLM capabilities to create autonomous agents with controllable, specialized, interactive, and professional-level competencies. We posit that PAgents can reshape professional services through continuously developed expertise. Our proposed PAgents framework entails a tri-layered architecture for genesis, evolution, and synergy: a base tool layer, a middle agent layer, and a top synergy layer. This paper aims to spur discourse on promising real-world applications of LLMs. We argue the increasing sophistication and integration of PAgents could lead to AI systems exhibiting professional mastery over complex domains, serving critical needs, and potentially achieving artificial general intelligence.

AgentGym: Evolving Large Language Model-based Agents across Diverse Environments
Building generalist agents that can handle diverse tasks and evolve themselves across different environments is a long-term goal in the AI community. Large language models (LLMs) are considered a promising foundation to build such agents due to their generalized capabilities. Current approaches either have LLM-based agents imitate expert-provided trajectories step-by-step, requiring human supervision, which is hard to scale and limits environmental exploration; or they let agents explore and learn in isolated environments, resulting in specialist agents with limited generalization. In this paper, we take the first step towards building generally-capable LLM-based agents with self-evolution ability. We identify a trinity of ingredients: 1) diverse environments for agent exploration and learning, 2) a trajectory set to equip agents with basic capabilities and prior knowledge, and 3) an effective and scalable evolution method. We propose AgentGym, a new framework featuring a variety of environments and tasks for broad, real-time, uni-format, and concurrent agent exploration. AgentGym also includes a database with expanded instructions, a benchmark suite, and high-quality trajectories across environments. Next, we propose a novel method, AgentEvol, to investigate the potential of agent self-evolution beyond previously seen data across tasks and environments. Experimental results show that the evolved agents can achieve results comparable to SOTA models. We release the AgentGym suite, including the platform, dataset, benchmark, checkpoints, and algorithm implementations. The AgentGym suite is available on https://github.com/WooooDyy/AgentGym.





Multimodal Lecture Presentations Dataset: Understanding Multimodality in Educational Slides
Lecture slide presentations, a sequence of pages that contain text and figures accompanied by speech, are constructed and presented carefully in order to optimally transfer knowledge to students. Previous studies in multimedia and psychology attribute the effectiveness of lecture presentations to their multimodal nature. As a step toward developing AI to aid in student learning as intelligent teacher assistants, we introduce the Multimodal Lecture Presentations dataset as a large-scale benchmark testing the capabilities of machine learning models in multimodal understanding of educational content. Our dataset contains aligned slides and spoken language, for 180+ hours of video and 9000+ slides, with 10 lecturers from various subjects (e.g., computer science, dentistry, biology). We introduce two research tasks which are designed as stepping stones towards AI agents that can explain (automatically captioning a lecture presentation) and illustrate (synthesizing visual figures to accompany spoken explanations) educational content. We provide manual annotations to help implement these two research tasks and evaluate state-of-the-art models on them. Comparing baselines and human student performances, we find that current models struggle in (1) weak crossmodal alignment between slides and spoken text, (2) learning novel visual mediums, (3) technical language, and (4) long-range sequences. Towards addressing this issue, we also introduce PolyViLT, a multimodal transformer trained with a multi-instance learning loss that is more effective than current approaches. We conclude by shedding light on the challenges and opportunities in multimodal understanding of educational presentations.
Deep Research Agents: A Systematic Examination And Roadmap
The rapid progress of Large Language Models (LLMs) has given rise to a new category of autonomous AI systems, referred to as Deep Research (DR) agents. These agents are designed to tackle complex, multi-turn informational research tasks by leveraging a combination of dynamic reasoning, adaptive long-horizon planning, multi-hop information retrieval, iterative tool use, and the generation of structured analytical reports. In this paper, we conduct a detailed analysis of the foundational technologies and architectural components that constitute Deep Research agents. We begin by reviewing information acquisition strategies, contrasting API-based retrieval methods with browser-based exploration. We then examine modular tool-use frameworks, including code execution, multimodal input processing, and the integration of Model Context Protocols (MCPs) to support extensibility and ecosystem development. To systematize existing approaches, we propose a taxonomy that differentiates between static and dynamic workflows, and we classify agent architectures based on planning strategies and agent composition, including single-agent and multi-agent configurations. We also provide a critical evaluation of current benchmarks, highlighting key limitations such as restricted access to external knowledge, sequential execution inefficiencies, and misalignment between evaluation metrics and the practical objectives of DR agents. Finally, we outline open challenges and promising directions for future research. A curated and continuously updated repository of DR agent research is available at: {https://github.com/ai-agents-2030/awesome-deep-research-agent}.


Coalitions of Large Language Models Increase the Robustness of AI Agents
The emergence of Large Language Models (LLMs) have fundamentally altered the way we interact with digital systems and have led to the pursuit of LLM powered AI agents to assist in daily workflows. LLMs, whilst powerful and capable of demonstrating some emergent properties, are not logical reasoners and often struggle to perform well at all sub-tasks carried out by an AI agent to plan and execute a workflow. While existing studies tackle this lack of proficiency by generalised pretraining at a huge scale or by specialised fine-tuning for tool use, we assess if a system comprising of a coalition of pretrained LLMs, each exhibiting specialised performance at individual sub-tasks, can match the performance of single model agents. The coalition of models approach showcases its potential for building robustness and reducing the operational costs of these AI agents by leveraging traits exhibited by specific models. Our findings demonstrate that fine-tuning can be mitigated by considering a coalition of pretrained models and believe that this approach can be applied to other non-agentic systems which utilise LLMs.

TUTORING: Instruction-Grounded Conversational Agent for Language Learners
In this paper, we propose Tutoring bot, a generative chatbot trained on a large scale of tutor-student conversations for English-language learning. To mimic a human tutor's behavior in language education, the tutor bot leverages diverse educational instructions and grounds to each instruction as additional input context for the tutor response generation. As a single instruction generally involves multiple dialogue turns to give the student sufficient speaking practice, the tutor bot is required to monitor and capture when the current instruction should be kept or switched to the next instruction. For that, the tutor bot is learned to not only generate responses but also infer its teaching action and progress on the current conversation simultaneously by a multi-task learning scheme. Our Tutoring bot is deployed under a non-commercial use license at https://tutoringai.com.


OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
A Survey on Agentic Multimodal Large Language Models
With the recent emergence of revolutionary autonomous agentic systems, research community is witnessing a significant shift from traditional static, passive, and domain-specific AI agents toward more dynamic, proactive, and generalizable agentic AI. Motivated by the growing interest in agentic AI and its potential trajectory toward AGI, we present a comprehensive survey on Agentic Multimodal Large Language Models (Agentic MLLMs). In this survey, we explore the emerging paradigm of agentic MLLMs, delineating their conceptual foundations and distinguishing characteristics from conventional MLLM-based agents. We establish a conceptual framework that organizes agentic MLLMs along three fundamental dimensions: (i) Agentic internal intelligence functions as the system's commander, enabling accurate long-horizon planning through reasoning, reflection, and memory; (ii) Agentic external tool invocation, whereby models proactively use various external tools to extend their problem-solving capabilities beyond their intrinsic knowledge; and (iii) Agentic environment interaction further situates models within virtual or physical environments, allowing them to take actions, adapt strategies, and sustain goal-directed behavior in dynamic real-world scenarios. To further accelerate research in this area for the community, we compile open-source training frameworks, training and evaluation datasets for developing agentic MLLMs. Finally, we review the downstream applications of agentic MLLMs and outline future research directions for this rapidly evolving field. To continuously track developments in this rapidly evolving field, we will also actively update a public repository at https://github.com/HJYao00/Awesome-Agentic-MLLMs.
Survey on Evaluation of LLM-based Agents
The emergence of LLM-based agents represents a paradigm shift in AI, enabling autonomous systems to plan, reason, use tools, and maintain memory while interacting with dynamic environments. This paper provides the first comprehensive survey of evaluation methodologies for these increasingly capable agents. We systematically analyze evaluation benchmarks and frameworks across four critical dimensions: (1) fundamental agent capabilities, including planning, tool use, self-reflection, and memory; (2) application-specific benchmarks for web, software engineering, scientific, and conversational agents; (3) benchmarks for generalist agents; and (4) frameworks for evaluating agents. Our analysis reveals emerging trends, including a shift toward more realistic, challenging evaluations with continuously updated benchmarks. We also identify critical gaps that future research must address-particularly in assessing cost-efficiency, safety, and robustness, and in developing fine-grained, and scalable evaluation methods. This survey maps the rapidly evolving landscape of agent evaluation, reveals the emerging trends in the field, identifies current limitations, and proposes directions for future research.





Generative Agents: Interactive Simulacra of Human Behavior
Believable proxies of human behavior can empower interactive applications ranging from immersive environments to rehearsal spaces for interpersonal communication to prototyping tools. In this paper, we introduce generative agents--computational software agents that simulate believable human behavior. Generative agents wake up, cook breakfast, and head to work; artists paint, while authors write; they form opinions, notice each other, and initiate conversations; they remember and reflect on days past as they plan the next day. To enable generative agents, we describe an architecture that extends a large language model to store a complete record of the agent's experiences using natural language, synthesize those memories over time into higher-level reflections, and retrieve them dynamically to plan behavior. We instantiate generative agents to populate an interactive sandbox environment inspired by The Sims, where end users can interact with a small town of twenty five agents using natural language. In an evaluation, these generative agents produce believable individual and emergent social behaviors: for example, starting with only a single user-specified notion that one agent wants to throw a Valentine's Day party, the agents autonomously spread invitations to the party over the next two days, make new acquaintances, ask each other out on dates to the party, and coordinate to show up for the party together at the right time. We demonstrate through ablation that the components of our agent architecture--observation, planning, and reflection--each contribute critically to the believability of agent behavior. By fusing large language models with computational, interactive agents, this work introduces architectural and interaction patterns for enabling believable simulations of human behavior.

MALT: Improving Reasoning with Multi-Agent LLM Training
Enabling effective collaboration among LLMs is a crucial step toward developing autonomous systems capable of solving complex problems. While LLMs are typically used as single-model generators, where humans critique and refine their outputs, the potential for jointly-trained collaborative models remains largely unexplored. Despite promising results in multi-agent communication and debate settings, little progress has been made in training models to work together on tasks. In this paper, we present a first step toward "Multi-agent LLM training" (MALT) on reasoning problems. Our approach employs a sequential multi-agent setup with heterogeneous LLMs assigned specialized roles: a generator, verifier, and refinement model iteratively solving problems. We propose a trajectory-expansion-based synthetic data generation process and a credit assignment strategy driven by joint outcome based rewards. This enables our post-training setup to utilize both positive and negative trajectories to autonomously improve each model's specialized capabilities as part of a joint sequential system. We evaluate our approach across MATH, GSM8k, and CQA, where MALT on Llama 3.1 8B models achieves relative improvements of 14.14%, 7.12%, and 9.40% respectively over the same baseline model. This demonstrates an early advance in multi-agent cooperative capabilities for performance on mathematical and common sense reasoning questions. More generally, our work provides a concrete direction for research around multi-agent LLM training approaches.




Agent S: An Open Agentic Framework that Uses Computers Like a Human
We present Agent S, an open agentic framework that enables autonomous interaction with computers through a Graphical User Interface (GUI), aimed at transforming human-computer interaction by automating complex, multi-step tasks. Agent S aims to address three key challenges in automating computer tasks: acquiring domain-specific knowledge, planning over long task horizons, and handling dynamic, non-uniform interfaces. To this end, Agent S introduces experience-augmented hierarchical planning, which learns from external knowledge search and internal experience retrieval at multiple levels, facilitating efficient task planning and subtask execution. In addition, it employs an Agent-Computer Interface (ACI) to better elicit the reasoning and control capabilities of GUI agents based on Multimodal Large Language Models (MLLMs). Evaluation on the OSWorld benchmark shows that Agent S outperforms the baseline by 9.37% on success rate (an 83.6% relative improvement) and achieves a new state-of-the-art. Comprehensive analysis highlights the effectiveness of individual components and provides insights for future improvements. Furthermore, Agent S demonstrates broad generalizability to different operating systems on a newly-released WindowsAgentArena benchmark. Code available at https://github.com/simular-ai/Agent-S.



A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems
Recent advances in large language models have sparked growing interest in AI agents capable of solving complex, real-world tasks. However, most existing agent systems rely on manually crafted configurations that remain static after deployment, limiting their ability to adapt to dynamic and evolving environments. To this end, recent research has explored agent evolution techniques that aim to automatically enhance agent systems based on interaction data and environmental feedback. This emerging direction lays the foundation for self-evolving AI agents, which bridge the static capabilities of foundation models with the continuous adaptability required by lifelong agentic systems. In this survey, we provide a comprehensive review of existing techniques for self-evolving agentic systems. Specifically, we first introduce a unified conceptual framework that abstracts the feedback loop underlying the design of self-evolving agentic systems. The framework highlights four key components: System Inputs, Agent System, Environment, and Optimisers, serving as a foundation for understanding and comparing different strategies. Based on this framework, we systematically review a wide range of self-evolving techniques that target different components of the agent system. We also investigate domain-specific evolution strategies developed for specialised fields such as biomedicine, programming, and finance, where optimisation objectives are tightly coupled with domain constraints. In addition, we provide a dedicated discussion on the evaluation, safety, and ethical considerations for self-evolving agentic systems, which are critical to ensuring their effectiveness and reliability. This survey aims to provide researchers and practitioners with a systematic understanding of self-evolving AI agents, laying the foundation for the development of more adaptive, autonomous, and lifelong agentic systems.





Agent KB: Leveraging Cross-Domain Experience for Agentic Problem Solving
As language agents tackle increasingly complex tasks, they struggle with effective error correction and experience reuse across domains. We introduce Agent KB, a hierarchical experience framework that enables complex agentic problem solving via a novel Reason-Retrieve-Refine pipeline. Agent KB addresses a core limitation: agents traditionally cannot learn from each other's experiences. By capturing both high-level strategies and detailed execution logs, Agent KB creates a shared knowledge base that enables cross-agent knowledge transfer. Evaluated on the GAIA benchmark, Agent KB improves success rates by up to 16.28 percentage points. On the most challenging tasks, Claude-3 improves from 38.46% to 57.69%, while GPT-4 improves from 53.49% to 73.26% on intermediate tasks. On SWE-bench code repair, Agent KB enables Claude-3 to improve from 41.33% to 53.33%. Our results suggest that Agent KB provides a modular, framework-agnostic infrastructure for enabling agents to learn from past experiences and generalize successful strategies to new tasks.




On the interaction between supervision and self-play in emergent communication
A promising approach for teaching artificial agents to use natural language involves using human-in-the-loop training. However, recent work suggests that current machine learning methods are too data inefficient to be trained in this way from scratch. In this paper, we investigate the relationship between two categories of learning signals with the ultimate goal of improving sample efficiency: imitating human language data via supervised learning, and maximizing reward in a simulated multi-agent environment via self-play (as done in emergent communication), and introduce the term supervised self-play (S2P) for algorithms using both of these signals. We find that first training agents via supervised learning on human data followed by self-play outperforms the converse, suggesting that it is not beneficial to emerge languages from scratch. We then empirically investigate various S2P schedules that begin with supervised learning in two environments: a Lewis signaling game with symbolic inputs, and an image-based referential game with natural language descriptions. Lastly, we introduce population based approaches to S2P, which further improves the performance over single-agent methods.

SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
To survive and thrive in complex environments, humans have evolved sophisticated self-improvement mechanisms through environment exploration, hierarchical abstraction of experiences into reuseable skills, and collaborative construction of an ever-growing skill repertoire. Despite recent advancements, autonomous web agents still lack crucial self-improvement capabilities, struggling with procedural knowledge abstraction, refining skills, and skill composition. In this work, we introduce SkillWeaver, a skill-centric framework enabling agents to self-improve by autonomously synthesizing reusable skills as APIs. Given a new website, the agent autonomously discovers skills, executes them for practice, and distills practice experiences into robust APIs. Iterative exploration continually expands a library of lightweight, plug-and-play APIs, significantly enhancing the agent's capabilities. Experiments on WebArena and real-world websites demonstrate the efficacy of SkillWeaver, achieving relative success rate improvements of 31.8% and 39.8%, respectively. Additionally, APIs synthesized by strong agents substantially enhance weaker agents through transferable skills, yielding improvements of up to 54.3% on WebArena. These results demonstrate the effectiveness of honing diverse website interactions into APIs, which can be seamlessly shared among various web agents.



Distilling LLM Agent into Small Models with Retrieval and Code Tools
Large language models (LLMs) excel at complex reasoning tasks but remain computationally expensive, limiting their practical deployment. To address this, recent works have focused on distilling reasoning capabilities into smaller language models (sLMs) using chain-of-thought (CoT) traces from teacher LLMs. However, this approach struggles in scenarios requiring rare factual knowledge or precise computation, where sLMs often hallucinate due to limited capability. In this work, we propose Agent Distillation, a framework for transferring not only reasoning capability but full task-solving behavior from LLM-based agents into sLMs with retrieval and code tools. We improve agent distillation along two complementary axes: (1) we introduce a prompting method called first-thought prefix to enhance the quality of teacher-generated trajectories; and (2) we propose a self-consistent action generation for improving test-time robustness of small agents. We evaluate our method on eight reasoning tasks across factual and mathematical domains, covering both in-domain and out-of-domain generalization. Our results show that sLMs as small as 0.5B, 1.5B, 3B parameters can achieve performance competitive with next-tier larger 1.5B, 3B, 7B models fine-tuned using CoT distillation, demonstrating the potential of agent distillation for building practical, tool-using small agents. Our code is available at https://github.com/Nardien/agent-distillation.


AgentRefine: Enhancing Agent Generalization through Refinement Tuning
Large Language Model (LLM) based agents have proved their ability to perform complex tasks like humans. However, there is still a large gap between open-sourced LLMs and commercial models like the GPT series. In this paper, we focus on improving the agent generalization capabilities of LLMs via instruction tuning. We first observe that the existing agent training corpus exhibits satisfactory results on held-in evaluation sets but fails to generalize to held-out sets. These agent-tuning works face severe formatting errors and are frequently stuck in the same mistake for a long while. We analyze that the poor generalization ability comes from overfitting to several manual agent environments and a lack of adaptation to new situations. They struggle with the wrong action steps and can not learn from the experience but just memorize existing observation-action relations. Inspired by the insight, we propose a novel AgentRefine framework for agent-tuning. The core idea is to enable the model to learn to correct its mistakes via observation in the trajectory. Specifically, we propose an agent synthesis framework to encompass a diverse array of environments and tasks and prompt a strong LLM to refine its error action according to the environment feedback. AgentRefine significantly outperforms state-of-the-art agent-tuning work in terms of generalization ability on diverse agent tasks. It also has better robustness facing perturbation and can generate diversified thought in inference. Our findings establish the correlation between agent generalization and self-refinement and provide a new paradigm for future research.

MetaAgent: Toward Self-Evolving Agent via Tool Meta-Learning
In this work, we propose MetaAgent, an agentic paradigm inspired by the principle of learning-by-doing, where expertise is developed through hands-on practice and continual self-improvement. MetaAgent starts with a minimal workflow, equipped only with basic reasoning and adaptive help-seeking abilities. When a knowledge gap is encountered, MetaAgent generates natural language help requests, which are routed to the most suitable external tool by a dedicated tool router. As MetaAgent solves tasks, it continually conducts self-reflection and answer verification, distilling actionable experience into concise texts that are dynamically incorporated into future task contexts. Besides, MetaAgent autonomously builds in-house tools and a persistent knowledge base by organizing its tool-use history, further enhancing its ability to retrieve and integrate relevant information We term this continual, data-driven process as meta tool learning, through which MetaAgent incrementally refines its reasoning and tool-use strategies, without changing model parameters or requiring further post-training. Evaluated on challenging knowledge discovery benchmarks, including GAIA, WebWalkerQA, and BrowseCamp, MetaAgent consistently outperforms workflow-based baselines and matches or exceeds end-to-end trained agents, demonstrating the promise of self-evolving agentic systems for robust, general-purpose knowledge discovery. We provide our source codes in https://github.com/qhjqhj00/MetaAgent.
SimuRA: Towards General Goal-Oriented Agent via Simulative Reasoning Architecture with LLM-Based World Model
AI agents built on large language models (LLMs) hold enormous promise, but current practice focuses on a one-task-one-agent approach, which not only falls short of scalability and generality, but also suffers from the fundamental limitations of autoregressive LLMs. On the other hand, humans are general agents who reason by mentally simulating the outcomes of their actions and plans. Moving towards a more general and powerful AI agent, we introduce SimuRA, a goal-oriented architecture for generalized agentic reasoning. Based on a principled formulation of optimal agent in any environment, \modelname overcomes the limitations of autoregressive reasoning by introducing a world model for planning via simulation. The generalized world model is implemented using LLM, which can flexibly plan in a wide range of environments using the concept-rich latent space of natural language. Experiments on difficult web browsing tasks show that \modelname improves the success of flight search from 0\% to 32.2\%. World-model-based planning, in particular, shows consistent advantage of up to 124\% over autoregressive planning, demonstrating the advantage of world model simulation as a reasoning paradigm. We are excited about the possibility for training a single, general agent model based on LLMs that can act superintelligently in all environments. To start, we make SimuRA, a web-browsing agent built on \modelname with pretrained LLMs, available as a research demo for public testing.
Cognitive Architectures for Language Agents
Recent efforts have augmented large language models (LLMs) with external resources (e.g., the Internet) or internal control flows (e.g., prompt chaining) for tasks requiring grounding or reasoning, leading to a new class of language agents. While these agents have achieved substantial empirical success, we lack a systematic framework to organize existing agents and plan future developments. In this paper, we draw on the rich history of cognitive science and symbolic artificial intelligence to propose Cognitive Architectures for Language Agents (CoALA). CoALA describes a language agent with modular memory components, a structured action space to interact with internal memory and external environments, and a generalized decision-making process to choose actions. We use CoALA to retrospectively survey and organize a large body of recent work, and prospectively identify actionable directions towards more capable agents. Taken together, CoALA contextualizes today's language agents within the broader history of AI and outlines a path towards language-based general intelligence.
IDEA:Enhancing the Rule Learning Ability of Language Agents through Induction, Deduction, and Abduction
While large language models (LLMs) have been thoroughly evaluated for deductive and inductive reasoning, their proficiency in abductive reasoning and holistic rule learning in interactive environments remains less explored. This work introduces RULEARN, a novel benchmark specifically designed to assess the rule-learning ability of LLMs in interactive settings. In RULEARN, agents interact with the environment to gather observations and discern patterns, using these insights to solve problems. To further enhance the rule-learning capabilities of LLM agents within this benchmark, we propose IDEA agent, which integrates Induction, Deduction, and Abduction processes. IDEA agent refines this approach by leveraging a structured reasoning sequence: generating hypotheses through abduction, testing them via deduction, and refining them based on feedback from induction. This sequence enables agents to dynamically establish and apply rules, mimicking human-like reasoning processes. Our evaluation of five representative LLMs indicates that while these models can generate plausible initial hypotheses, they often struggle with strategic interaction within the environment, effective incorporation of feedback, and adaptive refinement of their hypotheses. IDEA agent demonstrates significantly improved performance on the RULEARN benchmark, offering valuable insights for the development of agents capable of human-like rule-learning in real-world scenarios. We will release our code and data.
CodeAgents: A Token-Efficient Framework for Codified Multi-Agent Reasoning in LLMs
Effective prompt design is essential for improving the planning capabilities of large language model (LLM)-driven agents. However, existing structured prompting strategies are typically limited to single-agent, plan-only settings, and often evaluate performance solely based on task accuracy - overlooking critical factors such as token efficiency, modularity, and scalability in multi-agent environments. To address these limitations, we introduce CodeAgents, a prompting framework that codifies multi-agent reasoning and enables structured, token-efficient planning in multi-agent systems. In CodeAgents, all components of agent interaction - Task, Plan, Feedback, system roles, and external tool invocations - are codified into modular pseudocode enriched with control structures (e.g., loops, conditionals), boolean logic, and typed variables. This design transforms loosely connected agent plans into cohesive, interpretable, and verifiable multi-agent reasoning programs. We evaluate the proposed framework across three diverse benchmarks - GAIA, HotpotQA, and VirtualHome - using a range of representative LLMs. Results show consistent improvements in planning performance, with absolute gains of 3-36 percentage points over natural language prompting baselines. On VirtualHome, our method achieves a new state-of-the-art success rate of 56%. In addition, our approach reduces input and output token usage by 55-87% and 41-70%, respectively, underscoring the importance of token-aware evaluation metrics in the development of scalable multi-agent LLM systems. The code and resources are available at: https://anonymous.4open.science/r/CodifyingAgent-5A86
STELLA: Self-Evolving LLM Agent for Biomedical Research
The rapid growth of biomedical data, tools, and literature has created a fragmented research landscape that outpaces human expertise. While AI agents offer a solution, they typically rely on static, manually curated toolsets, limiting their ability to adapt and scale. Here, we introduce STELLA, a self-evolving AI agent designed to overcome these limitations. STELLA employs a multi-agent architecture that autonomously improves its own capabilities through two core mechanisms: an evolving Template Library for reasoning strategies and a dynamic Tool Ocean that expands as a Tool Creation Agent automatically discovers and integrates new bioinformatics tools. This allows STELLA to learn from experience. We demonstrate that STELLA achieves state-of-the-art accuracy on a suite of biomedical benchmarks, scoring approximately 26\% on Humanity's Last Exam: Biomedicine, 54\% on LAB-Bench: DBQA, and 63\% on LAB-Bench: LitQA, outperforming leading models by up to 6 percentage points. More importantly, we show that its performance systematically improves with experience; for instance, its accuracy on the Humanity's Last Exam benchmark almost doubles with increased trials. STELLA represents a significant advance towards AI Agent systems that can learn and grow, dynamically scaling their expertise to accelerate the pace of biomedical discovery.