

Upload all models and assets for af (20251001)
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- README.md +310 -145
- models/embeddings/monolingual/af_128d.bin +2 -2
- models/embeddings/monolingual/af_128d_metadata.json +5 -3
- models/embeddings/monolingual/af_32d.bin +2 -2
- models/embeddings/monolingual/af_32d_metadata.json +5 -3
- models/embeddings/monolingual/af_64d.bin +2 -2
- models/embeddings/monolingual/af_64d_metadata.json +5 -3
- models/subword_markov/af_markov_ctx1_subword.parquet +2 -2
- models/subword_markov/af_markov_ctx1_subword_metadata.json +2 -2
- models/subword_markov/af_markov_ctx2_subword.parquet +2 -2
- models/subword_markov/af_markov_ctx2_subword_metadata.json +2 -2
- models/subword_markov/af_markov_ctx3_subword.parquet +2 -2
- models/subword_markov/af_markov_ctx3_subword_metadata.json +2 -2
- models/subword_markov/af_markov_ctx4_subword.parquet +2 -2
- models/subword_markov/af_markov_ctx4_subword_metadata.json +2 -2
- models/subword_ngram/af_2gram_subword.parquet +2 -2
- models/subword_ngram/af_2gram_subword_metadata.json +2 -2
- models/subword_ngram/af_3gram_subword.parquet +2 -2
- models/subword_ngram/af_3gram_subword_metadata.json +2 -2
- models/subword_ngram/af_4gram_subword.parquet +2 -2
- models/subword_ngram/af_4gram_subword_metadata.json +2 -2
- models/tokenizer/af_tokenizer_16k.model +2 -2
- models/tokenizer/af_tokenizer_16k.vocab +0 -0
- models/tokenizer/af_tokenizer_32k.model +2 -2
- models/tokenizer/af_tokenizer_32k.vocab +0 -0
- models/tokenizer/af_tokenizer_64k.model +2 -2
- models/tokenizer/af_tokenizer_64k.vocab +0 -0
- models/tokenizer/af_tokenizer_8k.model +2 -2
- models/tokenizer/af_tokenizer_8k.vocab +0 -0
- models/vocabulary/af_vocabulary.parquet +2 -2
- models/vocabulary/af_vocabulary_metadata.json +10 -9
- models/word_markov/af_markov_ctx1_word.parquet +2 -2
- models/word_markov/af_markov_ctx1_word_metadata.json +2 -2
- models/word_markov/af_markov_ctx2_word.parquet +2 -2
- models/word_markov/af_markov_ctx2_word_metadata.json +2 -2
- models/word_markov/af_markov_ctx3_word.parquet +2 -2
- models/word_markov/af_markov_ctx3_word_metadata.json +2 -2
- models/word_markov/af_markov_ctx4_word.parquet +2 -2
- models/word_markov/af_markov_ctx4_word_metadata.json +2 -2
- models/word_ngram/af_2gram_word.parquet +2 -2
- models/word_ngram/af_2gram_word_metadata.json +2 -2
- models/word_ngram/af_3gram_word.parquet +2 -2
- models/word_ngram/af_3gram_word_metadata.json +2 -2
- models/word_ngram/af_4gram_word.parquet +2 -2
- models/word_ngram/af_4gram_word_metadata.json +2 -2
- visualizations/embedding_isotropy.png +0 -0
- visualizations/embedding_norms.png +0 -0
- visualizations/embedding_similarity.png +2 -2
- visualizations/markov_branching.png +0 -0
- visualizations/markov_contexts.png +0 -0
README.md
CHANGED
|
@@ -23,14 +23,14 @@ dataset_info:
|
|
| 23 |
metrics:
|
| 24 |
- name: best_compression_ratio
|
| 25 |
type: compression
|
| 26 |
-
value: 4.
|
| 27 |
- name: best_isotropy
|
| 28 |
type: isotropy
|
| 29 |
-
value: 0.
|
| 30 |
- name: vocabulary_size
|
| 31 |
type: vocab
|
| 32 |
-
value:
|
| 33 |
-
generated:
|
| 34 |
---
|
| 35 |
|
| 36 |
# AF - Wikilangs Models
|
|
@@ -44,12 +44,13 @@ We analyze tokenizers, n-gram models, Markov chains, vocabulary statistics, and
|
|
| 44 |
### Models & Assets
|
| 45 |
|
| 46 |
- Tokenizers (8k, 16k, 32k, 64k)
|
| 47 |
-
- N-gram models (2, 3, 4-gram)
|
| 48 |
-
- Markov chains (context of 1, 2, 3 and
|
| 49 |
- Subword N-gram and Markov chains
|
| 50 |
-
- Embeddings in various sizes and dimensions
|
| 51 |
- Language Vocabulary
|
| 52 |
- Language Statistics
|
|
|
|
| 53 |

|
| 54 |
|
| 55 |
### Analysis and Evaluation
|
|
@@ -59,7 +60,8 @@ We analyze tokenizers, n-gram models, Markov chains, vocabulary statistics, and
|
|
| 59 |
- [3. Markov Chain Evaluation](#3-markov-chain-evaluation)
|
| 60 |
- [4. Vocabulary Analysis](#4-vocabulary-analysis)
|
| 61 |
- [5. Word Embeddings Evaluation](#5-word-embeddings-evaluation)
|
| 62 |
-
- [6.
|
|
|
|
| 63 |
- [Metrics Glossary](#appendix-metrics-glossary--interpretation-guide)
|
| 64 |
- [Visualizations Index](#visualizations-index)
|
| 65 |
|
|
@@ -68,63 +70,57 @@ We analyze tokenizers, n-gram models, Markov chains, vocabulary statistics, and
|
|
| 68 |
|
| 69 |

|
| 70 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 71 |
### Results
|
| 72 |
|
| 73 |
| Vocab Size | Compression | Avg Token Len | UNK Rate | Total Tokens |
|
| 74 |
|------------|-------------|---------------|----------|--------------|
|
| 75 |
-
| **8k** | 3.
|
| 76 |
-
| **16k** |
|
| 77 |
-
| **32k** | 4.
|
| 78 |
-
| **64k** | 4.
|
| 79 |
|
| 80 |
### Tokenization Examples
|
| 81 |
|
| 82 |
Below are sample sentences tokenized with each vocabulary size:
|
| 83 |
|
| 84 |
-
**Sample 1:** `
|
| 85 |
-
|
| 86 |
-
Verwysings
|
| 87 |
-
|
| 88 |
-
Kateg...`
|
| 89 |
|
| 90 |
| Vocab | Tokens | Count |
|
| 91 |
|-------|--------|-------|
|
| 92 |
-
| 8k | `▁
|
| 93 |
-
| 16k | `▁
|
| 94 |
-
| 32k | `▁
|
| 95 |
-
| 64k | `▁
|
| 96 |
|
| 97 |
-
**Sample 2:** `Japan Nasionale Roete
|
| 98 |
-
|
| 99 |
-
Verwysings
|
| 100 |
-
|
| 101 |
-
Kateg...`
|
| 102 |
|
| 103 |
| Vocab | Tokens | Count |
|
| 104 |
|-------|--------|-------|
|
| 105 |
-
| 8k | `▁japan ▁nasionale ▁roete ▁ 2
|
| 106 |
-
| 16k | `▁japan ▁nasionale ▁roete ▁ 2
|
| 107 |
-
| 32k | `▁japan ▁nasionale ▁roete ▁ 2
|
| 108 |
-
| 64k | `▁japan ▁nasionale ▁roete ▁ 2
|
| 109 |
-
|
| 110 |
-
**Sample 3:** `Japan Nasionale Roete 264 is 'n nasionale snelweg in Japan.
|
| 111 |
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
Kateg...`
|
| 115 |
|
| 116 |
| Vocab | Tokens | Count |
|
| 117 |
|-------|--------|-------|
|
| 118 |
-
| 8k | `▁
|
| 119 |
-
| 16k | `▁
|
| 120 |
-
| 32k | `▁
|
| 121 |
-
| 64k | `▁
|
| 122 |
|
| 123 |
|
| 124 |
### Key Findings
|
| 125 |
|
| 126 |
-
- **Best Compression:** 64k achieves 4.
|
| 127 |
-
- **Lowest UNK Rate:** 8k with 0.
|
| 128 |
- **Trade-off:** Larger vocabularies improve compression but increase model size
|
| 129 |
- **Recommendation:** 32k vocabulary provides optimal balance for production use
|
| 130 |
|
|
@@ -133,57 +129,89 @@ Kateg...`
|
|
| 133 |
|
| 134 |

|
| 135 |
|
|
|
|
|
|
|
| 136 |

|
| 137 |
|
| 138 |
### Results
|
| 139 |
|
| 140 |
-
| N-gram | Perplexity | Entropy | Unique N-grams | Top-100 Coverage | Top-1000 Coverage |
|
| 141 |
-
|
| 142 |
-
| **2-gram** |
|
| 143 |
-
| **2-gram** |
|
| 144 |
-
| **3-gram** | 293,
|
| 145 |
-
| **3-gram** | 2,
|
| 146 |
-
| **4-gram** |
|
| 147 |
-
| **4-gram** |
|
| 148 |
|
| 149 |
### Top 5 N-grams by Size
|
| 150 |
|
| 151 |
-
**2-grams:**
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 152 |
|
| 153 |
| Rank | N-gram | Count |
|
| 154 |
|------|--------|-------|
|
| 155 |
-
| 1 | `
|
| 156 |
-
| 2 | `
|
| 157 |
-
| 3 | `
|
| 158 |
-
| 4 |
|
| 159 |
-
| 5 | `
|
| 160 |
|
| 161 |
-
**3-grams:**
|
| 162 |
|
| 163 |
| Rank | N-gram | Count |
|
| 164 |
|------|--------|-------|
|
| 165 |
-
| 1 | `
|
| 166 |
-
| 2 | `
|
| 167 |
-
| 3 | `
|
| 168 |
-
| 4 |
|
| 169 |
-
| 5 | `
|
| 170 |
|
| 171 |
-
**4-grams:**
|
| 172 |
|
| 173 |
| Rank | N-gram | Count |
|
| 174 |
|------|--------|-------|
|
| 175 |
-
| 1 | `
|
| 176 |
-
| 2 | `
|
| 177 |
-
| 3 | `
|
| 178 |
-
| 4 | `
|
| 179 |
-
| 5 | `
|
| 180 |
|
| 181 |
|
| 182 |
### Key Findings
|
| 183 |
|
| 184 |
-
- **Best Perplexity:** 2-gram with
|
| 185 |
- **Entropy Trend:** Decreases with larger n-grams (more predictable)
|
| 186 |
-
- **Coverage:** Top-1000 patterns cover ~
|
| 187 |
- **Recommendation:** 4-gram or 5-gram for best predictive performance
|
| 188 |
|
| 189 |
---
|
|
@@ -191,55 +219,86 @@ Kateg...`
|
|
| 191 |
|
| 192 |

|
| 193 |
|
|
|
|
|
|
|
| 194 |

|
| 195 |
|
| 196 |
### Results
|
| 197 |
|
| 198 |
-
| Context | Avg Entropy | Perplexity | Branching Factor | Unique Contexts | Predictability |
|
| 199 |
-
|
| 200 |
-
| **1** | 0.
|
| 201 |
-
| **1** | 1.
|
| 202 |
-
| **2** | 0.
|
| 203 |
-
| **2** | 0.
|
| 204 |
-
| **3** | 0.
|
| 205 |
-
| **3** | 0.
|
| 206 |
-
| **4** | 0.
|
| 207 |
-
| **4** | 0.
|
| 208 |
|
| 209 |
-
### Generated Text Samples
|
| 210 |
|
| 211 |
-
Below are text samples generated from each Markov chain model:
|
| 212 |
|
| 213 |
**Context Size 1:**
|
| 214 |
|
| 215 |
-
1. `die
|
| 216 |
-
2.
|
| 217 |
-
3.
|
| 218 |
|
| 219 |
**Context Size 2:**
|
| 220 |
|
| 221 |
-
1. `
|
| 222 |
-
2. `
|
| 223 |
-
3. `
|
| 224 |
|
| 225 |
**Context Size 3:**
|
| 226 |
|
| 227 |
-
1. `
|
| 228 |
-
2. `
|
| 229 |
-
3.
|
| 230 |
|
| 231 |
**Context Size 4:**
|
| 232 |
|
| 233 |
-
1. `
|
| 234 |
-
2. `
|
| 235 |
-
3. `
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 236 |
|
| 237 |
|
| 238 |
### Key Findings
|
| 239 |
|
| 240 |
-
- **Best Predictability:** Context-4 with
|
| 241 |
- **Branching Factor:** Decreases with context size (more deterministic)
|
| 242 |
-
- **Memory Trade-off:** Larger contexts require more storage (
|
| 243 |
- **Recommendation:** Context-3 or Context-4 for text generation
|
| 244 |
|
| 245 |
---
|
|
@@ -255,64 +314,64 @@ Below are text samples generated from each Markov chain model:
|
|
| 255 |
|
| 256 |
| Metric | Value |
|
| 257 |
|--------|-------|
|
| 258 |
-
| Vocabulary Size |
|
| 259 |
-
| Total Tokens |
|
| 260 |
-
| Mean Frequency |
|
| 261 |
| Median Frequency | 4 |
|
| 262 |
-
| Frequency Std Dev |
|
| 263 |
|
| 264 |
### Most Common Words
|
| 265 |
|
| 266 |
| Rank | Word | Frequency |
|
| 267 |
|------|------|-----------|
|
| 268 |
-
| 1 | die | 2,
|
| 269 |
-
| 2 | van | 1,
|
| 270 |
-
| 3 | in | 1,
|
| 271 |
-
| 4 | en | 1,
|
| 272 |
-
| 5 | n |
|
| 273 |
-
| 6 | is |
|
| 274 |
-
| 7 | het |
|
| 275 |
-
| 8 | wat |
|
| 276 |
-
| 9 |
|
| 277 |
-
| 10 |
|
| 278 |
|
| 279 |
### Least Common Words (from vocabulary)
|
| 280 |
|
| 281 |
| Rank | Word | Frequency |
|
| 282 |
|------|------|-----------|
|
| 283 |
-
| 1 |
|
| 284 |
-
| 2 |
|
| 285 |
-
| 3 |
|
| 286 |
-
| 4 |
|
| 287 |
-
| 5 |
|
| 288 |
-
| 6 |
|
| 289 |
-
| 7 |
|
| 290 |
-
| 8 |
|
| 291 |
-
| 9 |
|
| 292 |
-
| 10 |
|
| 293 |
|
| 294 |
### Zipf's Law Analysis
|
| 295 |
|
| 296 |
| Metric | Value |
|
| 297 |
|--------|-------|
|
| 298 |
-
| Zipf Coefficient | 1.
|
| 299 |
-
| R² (Goodness of Fit) | 0.
|
| 300 |
| Adherence Quality | **excellent** |
|
| 301 |
|
| 302 |
### Coverage Analysis
|
| 303 |
|
| 304 |
| Top N Words | Coverage |
|
| 305 |
|-------------|----------|
|
| 306 |
-
| Top 100 |
|
| 307 |
-
| Top 1,000 |
|
| 308 |
-
| Top 5,000 | 79.
|
| 309 |
-
| Top 10,000 | 85.
|
| 310 |
|
| 311 |
### Key Findings
|
| 312 |
|
| 313 |
-
- **Zipf Compliance:** R²=0.
|
| 314 |
-
- **High Frequency Dominance:** Top 100 words cover
|
| 315 |
-
- **Long Tail:**
|
| 316 |
|
| 317 |
---
|
| 318 |
## 5. Word Embeddings Evaluation
|
|
@@ -325,24 +384,127 @@ Below are text samples generated from each Markov chain model:
|
|
| 325 |
|
| 326 |

|
| 327 |
|
| 328 |
-
### Model Comparison
|
| 329 |
|
| 330 |
-
|
| 331 |
-
|
| 332 |
-
|
| 333 |
-
|
| 334 |
-
|
| 335 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 336 |
|
| 337 |
### Key Findings
|
| 338 |
|
| 339 |
-
- **Best Isotropy:** mono_64d with 0.
|
| 340 |
-
- **
|
| 341 |
-
- **
|
| 342 |
-
- **Recommendation:**
|
| 343 |
|
| 344 |
---
|
| 345 |
-
## 6.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 346 |
|
| 347 |

|
| 348 |
|
|
@@ -350,11 +512,12 @@ Below are text samples generated from each Markov chain model:
|
|
| 350 |
|
| 351 |
| Component | Recommended | Rationale |
|
| 352 |
|-----------|-------------|-----------|
|
| 353 |
-
| Tokenizer | **
|
| 354 |
-
| N-gram | **
|
| 355 |
-
| Markov | **Context-4** | Highest predictability (
|
| 356 |
| Embeddings | **100d** | Balanced semantic capture and isotropy |
|
| 357 |
|
|
|
|
| 358 |
---
|
| 359 |
## Appendix: Metrics Glossary & Interpretation Guide
|
| 360 |
|
|
@@ -544,7 +707,8 @@ If you use these models in your research, please cite:
|
|
| 544 |
author = {Kamali, Omar},
|
| 545 |
title = {Wikilangs: Open NLP Models for Wikipedia Languages},
|
| 546 |
year = {2025},
|
| 547 |
-
|
|
|
|
| 548 |
url = {https://huggingface.co/wikilangs}
|
| 549 |
institution = {Omneity Labs}
|
| 550 |
}
|
|
@@ -560,7 +724,8 @@ MIT License - Free for academic and commercial use.
|
|
| 560 |
- 🤗 Models: [huggingface.co/wikilangs](https://huggingface.co/wikilangs)
|
| 561 |
- 📊 Data: [wikipedia-monthly](https://huggingface.co/datasets/omarkamali/wikipedia-monthly)
|
| 562 |
- 👤 Author: [Omar Kamali](https://huggingface.co/omarkamali)
|
|
|
|
| 563 |
---
|
| 564 |
*Generated by Wikilangs Models Pipeline*
|
| 565 |
|
| 566 |
-
*Report Date:
|
|
|
|
| 23 |
metrics:
|
| 24 |
- name: best_compression_ratio
|
| 25 |
type: compression
|
| 26 |
+
value: 4.620
|
| 27 |
- name: best_isotropy
|
| 28 |
type: isotropy
|
| 29 |
+
value: 0.6959
|
| 30 |
- name: vocabulary_size
|
| 31 |
type: vocab
|
| 32 |
+
value: 0
|
| 33 |
+
generated: 2026-01-03
|
| 34 |
---
|
| 35 |
|
| 36 |
# AF - Wikilangs Models
|
|
|
|
| 44 |
### Models & Assets
|
| 45 |
|
| 46 |
- Tokenizers (8k, 16k, 32k, 64k)
|
| 47 |
+
- N-gram models (2, 3, 4, 5-gram)
|
| 48 |
+
- Markov chains (context of 1, 2, 3, 4 and 5)
|
| 49 |
- Subword N-gram and Markov chains
|
| 50 |
+
- Embeddings in various sizes and dimensions (aligned and unaligned)
|
| 51 |
- Language Vocabulary
|
| 52 |
- Language Statistics
|
| 53 |
+
|
| 54 |

|
| 55 |
|
| 56 |
### Analysis and Evaluation
|
|
|
|
| 60 |
- [3. Markov Chain Evaluation](#3-markov-chain-evaluation)
|
| 61 |
- [4. Vocabulary Analysis](#4-vocabulary-analysis)
|
| 62 |
- [5. Word Embeddings Evaluation](#5-word-embeddings-evaluation)
|
| 63 |
+
- [6. Morphological Analysis (Experimental)](#6-morphological-analysis)
|
| 64 |
+
- [7. Summary & Recommendations](#7-summary--recommendations)
|
| 65 |
- [Metrics Glossary](#appendix-metrics-glossary--interpretation-guide)
|
| 66 |
- [Visualizations Index](#visualizations-index)
|
| 67 |
|
|
|
|
| 70 |
|
| 71 |

|
| 72 |
|
| 73 |
+

|
| 74 |
+
|
| 75 |
+

|
| 76 |
+
|
| 77 |
+

|
| 78 |
+
|
| 79 |
### Results
|
| 80 |
|
| 81 |
| Vocab Size | Compression | Avg Token Len | UNK Rate | Total Tokens |
|
| 82 |
|------------|-------------|---------------|----------|--------------|
|
| 83 |
+
| **8k** | 3.747x | 3.75 | 0.0650% | 1,240,279 |
|
| 84 |
+
| **16k** | 4.108x | 4.11 | 0.0712% | 1,131,351 |
|
| 85 |
+
| **32k** | 4.402x | 4.40 | 0.0763% | 1,055,895 |
|
| 86 |
+
| **64k** | 4.620x 🏆 | 4.62 | 0.0801% | 1,006,125 |
|
| 87 |
|
| 88 |
### Tokenization Examples
|
| 89 |
|
| 90 |
Below are sample sentences tokenized with each vocabulary size:
|
| 91 |
|
| 92 |
+
**Sample 1:** `Neede is ’n dorp in die munisipaliteit Berkelland in die provinsie Gelderland in...`
|
|
|
|
|
|
|
|
|
|
|
|
|
| 93 |
|
| 94 |
| Vocab | Tokens | Count |
|
| 95 |
|-------|--------|-------|
|
| 96 |
+
| 8k | `▁ne e de ▁is ▁’ n ▁dorp ▁in ▁die ▁munisipaliteit ... (+14 more)` | 24 |
|
| 97 |
+
| 16k | `▁ne ede ▁is ▁’ n ▁dorp ▁in ▁die ▁munisipaliteit ▁berk ... (+13 more)` | 23 |
|
| 98 |
+
| 32k | `▁ne ede ▁is ▁’ n ▁dorp ▁in ▁die ▁munisipaliteit ▁berk ... (+13 more)` | 23 |
|
| 99 |
+
| 64k | `▁ne ede ▁is ▁’ n ▁dorp ▁in ▁die ▁munisipaliteit ▁berkelland ... (+12 more)` | 22 |
|
| 100 |
|
| 101 |
+
**Sample 2:** `Japan Nasionale Roete 210 is 'n nasionale snelweg in Japan. Verwysings paaie in ...`
|
|
|
|
|
|
|
|
|
|
|
|
|
| 102 |
|
| 103 |
| Vocab | Tokens | Count |
|
| 104 |
|-------|--------|-------|
|
| 105 |
+
| 8k | `▁japan ▁nasionale ▁roete ▁ 2 1 0 ▁is ▁' n ... (+9 more)` | 19 |
|
| 106 |
+
| 16k | `▁japan ▁nasionale ▁roete ▁ 2 1 0 ▁is ▁' n ... (+9 more)` | 19 |
|
| 107 |
+
| 32k | `▁japan ▁nasionale ▁roete ▁ 2 1 0 ▁is ▁' n ... (+9 more)` | 19 |
|
| 108 |
+
| 64k | `▁japan ▁nasionale ▁roete ▁ 2 1 0 ▁is ▁' n ... (+9 more)` | 19 |
|
|
|
|
|
|
|
| 109 |
|
| 110 |
+
**Sample 3:** `Ja'Net DuBois (gebore 5 Augustus – 17 Februarie was 'n Amerikaanse aktrise. Ekst...`
|
|
|
|
|
|
|
| 111 |
|
| 112 |
| Vocab | Tokens | Count |
|
| 113 |
|-------|--------|-------|
|
| 114 |
+
| 8k | `▁ja ' net ▁dub ois ▁( gebore ▁ 5 ▁augustus ... (+30 more)` | 40 |
|
| 115 |
+
| 16k | `▁ja ' net ▁dub ois ▁( gebore ▁ 5 ▁augustus ... (+30 more)` | 40 |
|
| 116 |
+
| 32k | `▁ja ' net ▁dub ois ▁( gebore ▁ 5 ▁augustus ... (+30 more)` | 40 |
|
| 117 |
+
| 64k | `▁ja ' net ▁dubois ▁( gebore ▁ 5 ▁augustus ▁– ... (+29 more)` | 39 |
|
| 118 |
|
| 119 |
|
| 120 |
### Key Findings
|
| 121 |
|
| 122 |
+
- **Best Compression:** 64k achieves 4.620x compression
|
| 123 |
+
- **Lowest UNK Rate:** 8k with 0.0650% unknown tokens
|
| 124 |
- **Trade-off:** Larger vocabularies improve compression but increase model size
|
| 125 |
- **Recommendation:** 32k vocabulary provides optimal balance for production use
|
| 126 |
|
|
|
|
| 129 |
|
| 130 |

|
| 131 |
|
| 132 |
+

|
| 133 |
+
|
| 134 |

|
| 135 |
|
| 136 |
### Results
|
| 137 |
|
| 138 |
+
| N-gram | Variant | Perplexity | Entropy | Unique N-grams | Top-100 Coverage | Top-1000 Coverage |
|
| 139 |
+
|--------|---------|------------|---------|----------------|------------------|-------------------|
|
| 140 |
+
| **2-gram** | Word | 67,018 | 16.03 | 738,183 | 13.7% | 29.1% |
|
| 141 |
+
| **2-gram** | Subword | 253 🏆 | 7.98 | 13,576 | 69.5% | 99.3% |
|
| 142 |
+
| **3-gram** | Word | 293,932 | 18.17 | 1,499,483 | 5.8% | 16.9% |
|
| 143 |
+
| **3-gram** | Subword | 2,161 | 11.08 | 96,263 | 28.5% | 71.9% |
|
| 144 |
+
| **4-gram** | Word | 555,388 | 19.08 | 2,510,434 | 6.5% | 16.6% |
|
| 145 |
+
| **4-gram** | Subword | 12,658 | 13.63 | 531,540 | 15.0% | 40.0% |
|
| 146 |
|
| 147 |
### Top 5 N-grams by Size
|
| 148 |
|
| 149 |
+
**2-grams (Word):**
|
| 150 |
+
|
| 151 |
+
| Rank | N-gram | Count |
|
| 152 |
+
|------|--------|-------|
|
| 153 |
+
| 1 | `van die` | 509,583 |
|
| 154 |
+
| 2 | `in die` | 342,810 |
|
| 155 |
+
| 3 | `is n` | 114,159 |
|
| 156 |
+
| 4 | `en die` | 109,201 |
|
| 157 |
+
| 5 | `is die` | 91,083 |
|
| 158 |
+
|
| 159 |
+
**3-grams (Word):**
|
| 160 |
+
|
| 161 |
+
| Rank | N-gram | Count |
|
| 162 |
+
|------|--------|-------|
|
| 163 |
+
| 1 | `van suid afrika` | 26,860 |
|
| 164 |
+
| 2 | `rolle in die` | 25,216 |
|
| 165 |
+
| 3 | `die 20ste eeu` | 24,460 |
|
| 166 |
+
| 4 | `van die 20ste` | 23,487 |
|
| 167 |
+
| 5 | `eksterne skakels in` | 22,326 |
|
| 168 |
+
|
| 169 |
+
**4-grams (Word):**
|
| 170 |
+
|
| 171 |
+
| Rank | N-gram | Count |
|
| 172 |
+
|------|--------|-------|
|
| 173 |
+
| 1 | `van die 20ste eeu` | 23,423 |
|
| 174 |
+
| 2 | `manlike akteurs van die` | 20,397 |
|
| 175 |
+
| 3 | `rolle in die rolprente` | 19,639 |
|
| 176 |
+
| 4 | `van die 21ste eeu` | 15,799 |
|
| 177 |
+
| 5 | `plants of the world` | 13,996 |
|
| 178 |
+
|
| 179 |
+
**2-grams (Subword):**
|
| 180 |
|
| 181 |
| Rank | N-gram | Count |
|
| 182 |
|------|--------|-------|
|
| 183 |
+
| 1 | `e _` | 8,883,972 |
|
| 184 |
+
| 2 | `n _` | 5,845,355 |
|
| 185 |
+
| 3 | `i e` | 5,296,532 |
|
| 186 |
+
| 4 | `e r` | 4,795,609 |
|
| 187 |
+
| 5 | `_ d` | 4,496,380 |
|
| 188 |
|
| 189 |
+
**3-grams (Subword):**
|
| 190 |
|
| 191 |
| Rank | N-gram | Count |
|
| 192 |
|------|--------|-------|
|
| 193 |
+
| 1 | `i e _` | 3,582,000 |
|
| 194 |
+
| 2 | `_ d i` | 3,169,450 |
|
| 195 |
+
| 3 | `d i e` | 3,046,581 |
|
| 196 |
+
| 4 | `a n _` | 1,886,278 |
|
| 197 |
+
| 5 | `e n _` | 1,538,281 |
|
| 198 |
|
| 199 |
+
**4-grams (Subword):**
|
| 200 |
|
| 201 |
| Rank | N-gram | Count |
|
| 202 |
|------|--------|-------|
|
| 203 |
+
| 1 | `d i e _` | 2,916,346 |
|
| 204 |
+
| 2 | `_ d i e` | 2,836,188 |
|
| 205 |
+
| 3 | `_ v a n` | 1,357,382 |
|
| 206 |
+
| 4 | `v a n _` | 1,341,795 |
|
| 207 |
+
| 5 | `n _ d i` | 1,169,352 |
|
| 208 |
|
| 209 |
|
| 210 |
### Key Findings
|
| 211 |
|
| 212 |
+
- **Best Perplexity:** 2-gram (subword) with 253
|
| 213 |
- **Entropy Trend:** Decreases with larger n-grams (more predictable)
|
| 214 |
+
- **Coverage:** Top-1000 patterns cover ~40% of corpus
|
| 215 |
- **Recommendation:** 4-gram or 5-gram for best predictive performance
|
| 216 |
|
| 217 |
---
|
|
|
|
| 219 |
|
| 220 |

|
| 221 |
|
| 222 |
+

|
| 223 |
+
|
| 224 |

|
| 225 |
|
| 226 |
### Results
|
| 227 |
|
| 228 |
+
| Context | Variant | Avg Entropy | Perplexity | Branching Factor | Unique Contexts | Predictability |
|
| 229 |
+
|---------|---------|-------------|------------|------------------|-----------------|----------------|
|
| 230 |
+
| **1** | Word | 0.9426 | 1.922 | 9.97 | 884,548 | 5.7% |
|
| 231 |
+
| **1** | Subword | 1.0721 | 2.102 | 6.58 | 7,654 | 0.0% |
|
| 232 |
+
| **2** | Word | 0.3842 | 1.305 | 2.33 | 8,810,967 | 61.6% |
|
| 233 |
+
| **2** | Subword | 0.7311 | 1.660 | 4.61 | 50,359 | 26.9% |
|
| 234 |
+
| **3** | Word | 0.1707 | 1.126 | 1.40 | 20,525,798 | 82.9% |
|
| 235 |
+
| **3** | Subword | 0.7061 | 1.631 | 4.02 | 231,918 | 29.4% |
|
| 236 |
+
| **4** | Word | 0.0704 🏆 | 1.050 | 1.13 | 28,628,609 | 93.0% |
|
| 237 |
+
| **4** | Subword | 0.6911 | 1.615 | 3.50 | 931,942 | 30.9% |
|
| 238 |
|
| 239 |
+
### Generated Text Samples (Word-based)
|
| 240 |
|
| 241 |
+
Below are text samples generated from each word-based Markov chain model:
|
| 242 |
|
| 243 |
**Context Size 1:**
|
| 244 |
|
| 245 |
+
1. `die burger 13 augustus se fsa nommer vier soldate die uitkoms vir letterkunde in n klein`
|
| 246 |
+
2. `van soest r amphoriscus cylindrus is in paradise careful he du mont dolent teen 5 6`
|
| 247 |
+
3. `in die rigting van die twee broers en met die ou teeroete die liberte het die`
|
| 248 |
|
| 249 |
**Context Size 2:**
|
| 250 |
|
| 251 |
+
1. `van die spons behoort tot die genus geodia en tot die genus leucadendron behoort en is deur`
|
| 252 |
+
2. `in die stille oseaan wat tot 4 uur later onder westerse intellektuele invloede gekom frankryk hertog...`
|
| 253 |
+
3. `is n nuwe telling van 83 etse wat spesiaal vir hierdie liedjie is in die rolprente innerspace`
|
| 254 |
|
| 255 |
**Context Size 3:**
|
| 256 |
|
| 257 |
+
1. `rolle in die rolprente the squaw man resurrección kongo the broken wing roaring rails en devils dice...`
|
| 258 |
+
2. `van die 20ste eeu aktrises van die 21ste eeu mense aktrises van die 21ste eeu aktrises van die`
|
| 259 |
+
3. `eksterne skakels in manlike akteurs van die 20ste eeu in n stormwind deur pieter kluyver wind is die`
|
| 260 |
|
| 261 |
**Context Size 4:**
|
| 262 |
|
| 263 |
+
1. `manlike akteurs van die 20ste eeu aktrises van die 20ste eeu rolprentvervaardigers in mense van die ...`
|
| 264 |
+
2. `rolle in die rolprente tomorrow when the war began the weekend shift high life tidelands eksterne sk...`
|
| 265 |
+
3. `plants of the world online van suid afrika plante van suid afrika gramineum`
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
### Generated Text Samples (Subword-based)
|
| 269 |
+
|
| 270 |
+
Below are text samples generated from each subword-based Markov chain model:
|
| 271 |
+
|
| 272 |
+
**Context Size 1:**
|
| 273 |
+
|
| 274 |
+
1. `_ho_evise_j._wom`
|
| 275 |
+
2. `enstein_n_nkt_he`
|
| 276 |
+
3. `igeked_dig_linid`
|
| 277 |
+
|
| 278 |
+
**Context Size 2:**
|
| 279 |
+
|
| 280 |
+
1. `e_nin:_sy_offie_l`
|
| 281 |
+
2. `n_die_nivir_nbom_`
|
| 282 |
+
3. `ie_uikaide_ver_ro`
|
| 283 |
+
|
| 284 |
+
**Context Size 3:**
|
| 285 |
+
|
| 286 |
+
1. `ie_van_die_bespelt`
|
| 287 |
+
2. `_die_wassen_paropo`
|
| 288 |
+
3. `die_van_spel_andar`
|
| 289 |
+
|
| 290 |
+
**Context Size 4:**
|
| 291 |
+
|
| 292 |
+
1. `die_vonnikeksadige_`
|
| 293 |
+
2. `_die_branse_levisie`
|
| 294 |
+
3. `_van_waar_toest,_r.`
|
| 295 |
|
| 296 |
|
| 297 |
### Key Findings
|
| 298 |
|
| 299 |
+
- **Best Predictability:** Context-4 (word) with 93.0% predictability
|
| 300 |
- **Branching Factor:** Decreases with context size (more deterministic)
|
| 301 |
+
- **Memory Trade-off:** Larger contexts require more storage (931,942 contexts)
|
| 302 |
- **Recommendation:** Context-3 or Context-4 for text generation
|
| 303 |
|
| 304 |
---
|
|
|
|
| 314 |
|
| 315 |
| Metric | Value |
|
| 316 |
|--------|-------|
|
| 317 |
+
| Vocabulary Size | 403,515 |
|
| 318 |
+
| Total Tokens | 38,429,571 |
|
| 319 |
+
| Mean Frequency | 95.24 |
|
| 320 |
| Median Frequency | 4 |
|
| 321 |
+
| Frequency Std Dev | 6117.62 |
|
| 322 |
|
| 323 |
### Most Common Words
|
| 324 |
|
| 325 |
| Rank | Word | Frequency |
|
| 326 |
|------|------|-----------|
|
| 327 |
+
| 1 | die | 2,828,931 |
|
| 328 |
+
| 2 | van | 1,318,980 |
|
| 329 |
+
| 3 | in | 1,109,973 |
|
| 330 |
+
| 4 | en | 1,045,922 |
|
| 331 |
+
| 5 | n | 802,080 |
|
| 332 |
+
| 6 | is | 763,111 |
|
| 333 |
+
| 7 | het | 641,876 |
|
| 334 |
+
| 8 | wat | 341,748 |
|
| 335 |
+
| 9 | the | 292,778 |
|
| 336 |
+
| 10 | op | 289,154 |
|
| 337 |
|
| 338 |
### Least Common Words (from vocabulary)
|
| 339 |
|
| 340 |
| Rank | Word | Frequency |
|
| 341 |
|------|------|-----------|
|
| 342 |
+
| 1 | williamsville | 2 |
|
| 343 |
+
| 2 | 1kd | 2 |
|
| 344 |
+
| 3 | argiefkopie | 2 |
|
| 345 |
+
| 4 | liuzhi | 2 |
|
| 346 |
+
| 5 | microsat | 2 |
|
| 347 |
+
| 6 | orbex | 2 |
|
| 348 |
+
| 7 | afrikanertoekoms | 2 |
|
| 349 |
+
| 8 | wêreldkennis | 2 |
|
| 350 |
+
| 9 | gastebydraes | 2 |
|
| 351 |
+
| 10 | sandkweek | 2 |
|
| 352 |
|
| 353 |
### Zipf's Law Analysis
|
| 354 |
|
| 355 |
| Metric | Value |
|
| 356 |
|--------|-------|
|
| 357 |
+
| Zipf Coefficient | 1.0518 |
|
| 358 |
+
| R² (Goodness of Fit) | 0.996010 |
|
| 359 |
| Adherence Quality | **excellent** |
|
| 360 |
|
| 361 |
### Coverage Analysis
|
| 362 |
|
| 363 |
| Top N Words | Coverage |
|
| 364 |
|-------------|----------|
|
| 365 |
+
| Top 100 | 43.7% |
|
| 366 |
+
| Top 1,000 | 64.3% |
|
| 367 |
+
| Top 5,000 | 79.4% |
|
| 368 |
+
| Top 10,000 | 85.0% |
|
| 369 |
|
| 370 |
### Key Findings
|
| 371 |
|
| 372 |
+
- **Zipf Compliance:** R²=0.9960 indicates excellent adherence to Zipf's law
|
| 373 |
+
- **High Frequency Dominance:** Top 100 words cover 43.7% of corpus
|
| 374 |
+
- **Long Tail:** 393,515 words needed for remaining 15.0% coverage
|
| 375 |
|
| 376 |
---
|
| 377 |
## 5. Word Embeddings Evaluation
|
|
|
|
| 384 |
|
| 385 |

|
| 386 |
|
|
|
|
| 387 |
|
| 388 |
+
### 5.1 Cross-Lingual Alignment
|
| 389 |
+
|
| 390 |
+
> *Note: Multilingual alignment visualization not available for this language.*
|
| 391 |
+
|
| 392 |
+
|
| 393 |
+
### 5.2 Model Comparison
|
| 394 |
+
|
| 395 |
+
| Model | Dimension | Isotropy | Semantic Density | Alignment R@1 | Alignment R@10 |
|
| 396 |
+
|-------|-----------|----------|------------------|---------------|----------------|
|
| 397 |
+
| **mono_32d** | 32 | 0.6926 | 0.3664 | N/A | N/A |
|
| 398 |
+
| **mono_64d** | 64 | 0.6959 🏆 | 0.3037 | N/A | N/A |
|
| 399 |
+
| **mono_128d** | 128 | 0.6723 | 0.2366 | N/A | N/A |
|
| 400 |
|
| 401 |
### Key Findings
|
| 402 |
|
| 403 |
+
- **Best Isotropy:** mono_64d with 0.6959 (more uniform distribution)
|
| 404 |
+
- **Semantic Density:** Average pairwise similarity of 0.3023. Lower values indicate better semantic separation.
|
| 405 |
+
- **Alignment Quality:** No aligned models evaluated in this run.
|
| 406 |
+
- **Recommendation:** 128d aligned for best cross-lingual performance
|
| 407 |
|
| 408 |
---
|
| 409 |
+
## 6. Morphological Analysis (Experimental)
|
| 410 |
+
|
| 411 |
+
> ⚠️ **Warning:** This language shows low morphological productivity. The statistical signals used for this analysis may be noisy or less reliable than for morphologically rich languages.
|
| 412 |
+
|
| 413 |
+
This section presents an automated morphological analysis derived from the statistical divergence between word-level and subword-level models. By analyzing where subword predictability spikes and where word-level coverage fails, we can infer linguistic structures without supervised data.
|
| 414 |
+
|
| 415 |
+
### 6.1 Productivity & Complexity
|
| 416 |
+
|
| 417 |
+
| Metric | Value | Interpretation | Recommendation |
|
| 418 |
+
|--------|-------|----------------|----------------|
|
| 419 |
+
| Productivity Index | **0.000** | Low morphological productivity | ⚠️ Likely unreliable |
|
| 420 |
+
| Idiomaticity Gap | **-1.000** | Low formulaic content | - |
|
| 421 |
+
|
| 422 |
+
### 6.2 Affix Inventory (Productive Units)
|
| 423 |
+
|
| 424 |
+
These are the most productive prefixes and suffixes identified by sampling the vocabulary for global substitutability patterns. A unit is considered an affix if stripping it leaves a valid stem that appears in other contexts.
|
| 425 |
+
|
| 426 |
+
#### Productive Prefixes
|
| 427 |
+
| Prefix | Examples |
|
| 428 |
+
|--------|----------|
|
| 429 |
+
| `-ge` | gewandel, gefloreer, getrouheidseed |
|
| 430 |
+
|
| 431 |
+
#### Productive Suffixes
|
| 432 |
+
| Suffix | Examples |
|
| 433 |
+
|--------|----------|
|
| 434 |
+
| `-e` | kurasse, kortikosteroïde, maatskappyname |
|
| 435 |
+
| `-s` | tuttles, stakings, kenens |
|
| 436 |
+
| `-er` | gefloreer, umbilorivier, koorsanger |
|
| 437 |
+
| `-es` | tuttles, spectres, kladmetodes |
|
| 438 |
+
| `-ng` | kruiskleding, saambring, swangerskapvergiftiging |
|
| 439 |
+
| `-ie` | patagonie, photographie, kriminologie |
|
| 440 |
+
| `-ing` | kruiskleding, saambring, swangerskapvergiftiging |
|
| 441 |
+
| `-te` | monofisiete, skrikwekkendste, curriebekerpunte |
|
| 442 |
+
|
| 443 |
+
### 6.3 Bound Stems (Lexical Roots)
|
| 444 |
+
|
| 445 |
+
Bound stems are high-frequency subword units that are semantically cohesive but rarely appear as standalone words. These often correspond to the 'core' of a word that requires inflection or derivation to be valid.
|
| 446 |
+
|
| 447 |
+
| Stem | Cohesion | Substitutability | Examples |
|
| 448 |
+
|------|----------|------------------|----------|
|
| 449 |
+
| `pren` | 2.37x | 29 contexts | prent, prens, prend |
|
| 450 |
+
| `staa` | 1.71x | 98 contexts | staat, staal, staan |
|
| 451 |
+
| `ings` | 1.53x | 145 contexts | wings, rings, hings |
|
| 452 |
+
| `brui` | 1.99x | 44 contexts | bruis, bruid, bruik |
|
| 453 |
+
| `kend` | 1.65x | 95 contexts | kende, kendo, skend |
|
| 454 |
+
| `ebru` | 2.08x | 32 contexts | gebru, hebrus, gebruk |
|
| 455 |
+
| `ersk` | 1.54x | 107 contexts | perske, koersk, perski |
|
| 456 |
+
| `erdi` | 1.61x | 84 contexts | verdi, ferdi, gerdi |
|
| 457 |
+
| `rste` | 1.42x | 150 contexts | erste, eerste, fyrste |
|
| 458 |
+
| `rdie` | 1.73x | 51 contexts | ardie, gordie, jordie |
|
| 459 |
+
| `kste` | 1.54x | 71 contexts | ekster, tekste, dikste |
|
| 460 |
+
| `eken` | 1.34x | 123 contexts | weken, deken, oeken |
|
| 461 |
+
|
| 462 |
+
### 6.4 Affix Compatibility (Co-occurrence)
|
| 463 |
+
|
| 464 |
+
This table shows which prefixes and suffixes most frequently co-occur on the same stems, revealing the 'stacking' rules of the language's morphology.
|
| 465 |
+
|
| 466 |
+
| Prefix | Suffix | Frequency | Examples |
|
| 467 |
+
|--------|--------|-----------|----------|
|
| 468 |
+
| `-ge` | `-e` | 63 words | geenlokusse, gebruikskode |
|
| 469 |
+
| `-ge` | `-de` | 28 words | gebruikskode, geeboniseerde |
|
| 470 |
+
| `-ge` | `-er` | 27 words | geigenspieler, getelegrafeer |
|
| 471 |
+
| `-ge` | `-s` | 11 words | gemeentesusters, geles |
|
| 472 |
+
| `-ge` | `-en` | 9 words | gefahren, gelegen |
|
| 473 |
+
| `-ge` | `-te` | 6 words | geskenkte, geweldigste |
|
| 474 |
+
| `-ge` | `-ie` | 5 words | getalteorie, geelglasogie |
|
| 475 |
+
| `-ge` | `-es` | 4 words | geles, geowetenskaplikes |
|
| 476 |
+
| `-ge` | `-ng` | 2 words | geeking, gesondheidsbevordering |
|
| 477 |
+
| `-ge` | `-ing` | 1 words | geeking, gesondheidsbevordering |
|
| 478 |
+
|
| 479 |
+
### 6.5 Recursive Morpheme Segmentation
|
| 480 |
+
|
| 481 |
+
Using **Recursive Hierarchical Substitutability**, we decompose complex words into their constituent morphemes. This approach handles nested affixes (e.g., `prefix-prefix-root-suffix`).
|
| 482 |
+
|
| 483 |
+
| Word | Suggested Split | Confidence | Stem |
|
| 484 |
+
|------|-----------------|------------|------|
|
| 485 |
+
| gemonteerde | **`ge-monte-er-de`** | 7.5 | `monte` |
|
| 486 |
+
| bevredigende | **`bevredig-en-de`** | 6.0 | `bevredig` |
|
| 487 |
+
| ouditering | **`oudit-er-ing`** | 6.0 | `oudit` |
|
| 488 |
+
| kruiningen | **`kruin-ing-en`** | 6.0 | `kruin` |
|
| 489 |
+
| verlorener | **`verlor-en-er`** | 6.0 | `verlor` |
|
| 490 |
+
| verhardende | **`verhard-en-de`** | 6.0 | `verhard` |
|
| 491 |
+
| bestuifde | **`bestuif-de`** | 4.5 | `bestuif` |
|
| 492 |
+
| behoeften | **`behoeft-en`** | 4.5 | `behoeft` |
|
| 493 |
+
| verminkte | **`vermink-te`** | 4.5 | `vermink` |
|
| 494 |
+
| onreëlmatiger | **`onreëlmatig-er`** | 4.5 | `onreëlmatig` |
|
| 495 |
+
| kollageen | **`kollage-en`** | 4.5 | `kollage` |
|
| 496 |
+
| gekrummel | **`ge-krummel`** | 4.5 | `krummel` |
|
| 497 |
+
| repeterende | **`repet-er-en-de`** | 4.5 | `repet` |
|
| 498 |
+
| gehoorvermoë | **`ge-hoorvermoë`** | 4.5 | `hoorvermoë` |
|
| 499 |
+
| eksoskelette | **`eksoskelet-te`** | 4.5 | `eksoskelet` |
|
| 500 |
+
|
| 501 |
+
### 6.6 Linguistic Interpretation
|
| 502 |
+
|
| 503 |
+
> **Automated Insight:**
|
| 504 |
+
The language AF appears to be more isolating or has a highly fixed vocabulary. Word-level models perform nearly as well as subword models, indicating fewer productive morphological processes.
|
| 505 |
+
|
| 506 |
+
---
|
| 507 |
+
## 7. Summary & Recommendations
|
| 508 |
|
| 509 |

|
| 510 |
|
|
|
|
| 512 |
|
| 513 |
| Component | Recommended | Rationale |
|
| 514 |
|-----------|-------------|-----------|
|
| 515 |
+
| Tokenizer | **64k BPE** | Best compression (4.62x) |
|
| 516 |
+
| N-gram | **2-gram** | Lowest perplexity (253) |
|
| 517 |
+
| Markov | **Context-4** | Highest predictability (93.0%) |
|
| 518 |
| Embeddings | **100d** | Balanced semantic capture and isotropy |
|
| 519 |
|
| 520 |
+
|
| 521 |
---
|
| 522 |
## Appendix: Metrics Glossary & Interpretation Guide
|
| 523 |
|
|
|
|
| 707 |
author = {Kamali, Omar},
|
| 708 |
title = {Wikilangs: Open NLP Models for Wikipedia Languages},
|
| 709 |
year = {2025},
|
| 710 |
+
doi = {10.5281/zenodo.18073153},
|
| 711 |
+
publisher = {Zenodo},
|
| 712 |
url = {https://huggingface.co/wikilangs}
|
| 713 |
institution = {Omneity Labs}
|
| 714 |
}
|
|
|
|
| 724 |
- 🤗 Models: [huggingface.co/wikilangs](https://huggingface.co/wikilangs)
|
| 725 |
- 📊 Data: [wikipedia-monthly](https://huggingface.co/datasets/omarkamali/wikipedia-monthly)
|
| 726 |
- 👤 Author: [Omar Kamali](https://huggingface.co/omarkamali)
|
| 727 |
+
- 🤝 Sponsor: [Featherless AI](https://featherless.ai)
|
| 728 |
---
|
| 729 |
*Generated by Wikilangs Models Pipeline*
|
| 730 |
|
| 731 |
+
*Report Date: 2026-01-03 07:17:29*
|
models/embeddings/monolingual/af_128d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:11057ead6d145fd80aa8a3489e8c8d86000071008dba47a7f9f04188e658acb2
|
| 3 |
+
size 1301432503
|
models/embeddings/monolingual/af_128d_metadata.json
CHANGED
|
@@ -3,11 +3,13 @@
|
|
| 3 |
"dimension": 128,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
-
"
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
-
"epochs": 5
|
|
|
|
|
|
|
| 11 |
},
|
| 12 |
-
"vocab_size":
|
| 13 |
}
|
|
|
|
| 3 |
"dimension": 128,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
+
"algorithm": "skipgram",
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
+
"epochs": 5,
|
| 11 |
+
"encoding_method": "rope",
|
| 12 |
+
"dim": 128
|
| 13 |
},
|
| 14 |
+
"vocab_size": 266109
|
| 15 |
}
|
models/embeddings/monolingual/af_32d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:933902af3f06d4dccbab2f9cda13414a48c3a2fafa734a3e6c9cc651ffed6732
|
| 3 |
+
size 329060791
|
models/embeddings/monolingual/af_32d_metadata.json
CHANGED
|
@@ -3,11 +3,13 @@
|
|
| 3 |
"dimension": 32,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
-
"
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
-
"epochs": 5
|
|
|
|
|
|
|
| 11 |
},
|
| 12 |
-
"vocab_size":
|
| 13 |
}
|
|
|
|
| 3 |
"dimension": 32,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
+
"algorithm": "skipgram",
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
+
"epochs": 5,
|
| 11 |
+
"encoding_method": "rope",
|
| 12 |
+
"dim": 32
|
| 13 |
},
|
| 14 |
+
"vocab_size": 266109
|
| 15 |
}
|
models/embeddings/monolingual/af_64d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7c676e073cfbf1cb9b2e7f3e4b3e94463a17ee848c6d9df01ea4fc280e2f7ce6
|
| 3 |
+
size 653184695
|
models/embeddings/monolingual/af_64d_metadata.json
CHANGED
|
@@ -3,11 +3,13 @@
|
|
| 3 |
"dimension": 64,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
-
"
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
-
"epochs": 5
|
|
|
|
|
|
|
| 11 |
},
|
| 12 |
-
"vocab_size":
|
| 13 |
}
|
|
|
|
| 3 |
"dimension": 64,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
+
"algorithm": "skipgram",
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
+
"epochs": 5,
|
| 11 |
+
"encoding_method": "rope",
|
| 12 |
+
"dim": 64
|
| 13 |
},
|
| 14 |
+
"vocab_size": 266109
|
| 15 |
}
|
models/subword_markov/af_markov_ctx1_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d149d8684419833d4d657f06ff43fde6f6330d2a78848a075e6c2fec57f7c4a8
|
| 3 |
+
size 378608
|
models/subword_markov/af_markov_ctx1_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 1,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "af",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 1,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "af",
|
| 5 |
+
"unique_contexts": 7654,
|
| 6 |
+
"total_transitions": 242297410
|
| 7 |
}
|
models/subword_markov/af_markov_ctx2_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:420f531b4f1b408ddda531f838f2d4932ecc9cbb7de16ed5589351bbace9b214
|
| 3 |
+
size 1866665
|
models/subword_markov/af_markov_ctx2_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 2,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "af",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 2,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "af",
|
| 5 |
+
"unique_contexts": 50359,
|
| 6 |
+
"total_transitions": 242170946
|
| 7 |
}
|
models/subword_markov/af_markov_ctx3_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:075a8bbd37d56e56e0b0f55526f7b478207748bf68daf7f1981287409f6c5cb8
|
| 3 |
+
size 8218278
|
models/subword_markov/af_markov_ctx3_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 3,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "af",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 3,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "af",
|
| 5 |
+
"unique_contexts": 231918,
|
| 6 |
+
"total_transitions": 242044482
|
| 7 |
}
|
models/subword_markov/af_markov_ctx4_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e71c7cbca9385f2aabc8bff2108e5cb3876745099e692d102b8817bd6e393051
|
| 3 |
+
size 26401415
|
models/subword_markov/af_markov_ctx4_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 4,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "af",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 4,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "af",
|
| 5 |
+
"unique_contexts": 931942,
|
| 6 |
+
"total_transitions": 241918018
|
| 7 |
}
|
models/subword_ngram/af_2gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:69bbe527269e41324fd2369bdb8f0798f0b62fd22d70026c15fbf678f77788e1
|
| 3 |
+
size 182664
|
models/subword_ngram/af_2gram_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 2,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "af",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 2,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "af",
|
| 5 |
+
"unique_ngrams": 13576,
|
| 6 |
+
"total_ngrams": 242297410
|
| 7 |
}
|
models/subword_ngram/af_3gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8fcbc486b3961f9f14aee1492ea622129d621d205e682bab43457c4029f343ca
|
| 3 |
+
size 1229801
|
models/subword_ngram/af_3gram_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 3,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "af",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 3,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "af",
|
| 5 |
+
"unique_ngrams": 96263,
|
| 6 |
+
"total_ngrams": 242170946
|
| 7 |
}
|
models/subword_ngram/af_4gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b35e67ae40780c953eae3c44b6344369d951fcbf2c26114557257a76b11f77d5
|
| 3 |
+
size 6246285
|
models/subword_ngram/af_4gram_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 4,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "af",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 4,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "af",
|
| 5 |
+
"unique_ngrams": 531540,
|
| 6 |
+
"total_ngrams": 242044482
|
| 7 |
}
|
models/tokenizer/af_tokenizer_16k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2be64d6763f5e6fd310791270e3525ef8484a9db66ef0fff6e0f1476d6a96d34
|
| 3 |
+
size 507153
|
models/tokenizer/af_tokenizer_16k.vocab
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/tokenizer/af_tokenizer_32k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8b5159876118e0a3489a99480419b844198a12a1b816ad232fed8ccae35bb818
|
| 3 |
+
size 786684
|
models/tokenizer/af_tokenizer_32k.vocab
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/tokenizer/af_tokenizer_64k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4675b04acf7e973018b38e96d006eb263620e28799e83be7bdd4a27ac0994a13
|
| 3 |
+
size 1361348
|
models/tokenizer/af_tokenizer_64k.vocab
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/tokenizer/af_tokenizer_8k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1f7dc8da1d29ab51f9c6ac5f659460f17c5222dd813dbe07b43facfc31f68728
|
| 3 |
+
size 371768
|
models/tokenizer/af_tokenizer_8k.vocab
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/vocabulary/af_vocabulary.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e2355921b7485f0850c13db4987f38a9cb0cb18c4d52369c481dbd6c58288967
|
| 3 |
+
size 6384076
|
models/vocabulary/af_vocabulary_metadata.json
CHANGED
|
@@ -1,16 +1,17 @@
|
|
| 1 |
{
|
| 2 |
"language": "af",
|
| 3 |
-
"vocabulary_size":
|
|
|
|
| 4 |
"statistics": {
|
| 5 |
-
"type_token_ratio": 0.
|
| 6 |
"coverage": {
|
| 7 |
-
"top_100": 0.
|
| 8 |
-
"top_1000": 0.
|
| 9 |
-
"top_5000": 0.
|
| 10 |
-
"top_10000": 0.
|
| 11 |
},
|
| 12 |
-
"hapax_count":
|
| 13 |
-
"hapax_ratio": 0.
|
| 14 |
-
"total_documents":
|
| 15 |
}
|
| 16 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"language": "af",
|
| 3 |
+
"vocabulary_size": 403515,
|
| 4 |
+
"variant": "full",
|
| 5 |
"statistics": {
|
| 6 |
+
"type_token_ratio": 0.02274299800346992,
|
| 7 |
"coverage": {
|
| 8 |
+
"top_100": 0.4314823858718236,
|
| 9 |
+
"top_1000": 0.6347620541014498,
|
| 10 |
+
"top_5000": 0.7838174538213594,
|
| 11 |
+
"top_10000": 0.8392913943711919
|
| 12 |
},
|
| 13 |
+
"hapax_count": 481438,
|
| 14 |
+
"hapax_ratio": 0.5440266319228253,
|
| 15 |
+
"total_documents": 126464
|
| 16 |
}
|
| 17 |
}
|
models/word_markov/af_markov_ctx1_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:137d7884907248e6dab7f37ec9010eca83d41914f5a04456d97db0173992ed52
|
| 3 |
+
size 77512633
|
models/word_markov/af_markov_ctx1_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 1,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "af",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 1,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "af",
|
| 5 |
+
"unique_contexts": 884548,
|
| 6 |
+
"total_transitions": 38784545
|
| 7 |
}
|
models/word_markov/af_markov_ctx2_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:509f64b241796227fd01fdc0d6d9738c3943aabf43e5c799d193f8707fa2a669
|
| 3 |
+
size 234719710
|
models/word_markov/af_markov_ctx2_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 2,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "af",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 2,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "af",
|
| 5 |
+
"unique_contexts": 8810967,
|
| 6 |
+
"total_transitions": 38658081
|
| 7 |
}
|
models/word_markov/af_markov_ctx3_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b7b6e1d49f05b7f0a242d75b1deca41677df4392fd3120553ba2e335ce06fee2
|
| 3 |
+
size 401895512
|
models/word_markov/af_markov_ctx3_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 3,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "af",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 3,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "af",
|
| 5 |
+
"unique_contexts": 20525798,
|
| 6 |
+
"total_transitions": 38531617
|
| 7 |
}
|
models/word_markov/af_markov_ctx4_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2b17acd652effc19ef7d02df727c29bc1d40a01cc11192d367fc60ef3d69a16d
|
| 3 |
+
size 515063986
|
models/word_markov/af_markov_ctx4_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 4,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "af",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 4,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "af",
|
| 5 |
+
"unique_contexts": 28628609,
|
| 6 |
+
"total_transitions": 38405153
|
| 7 |
}
|
models/word_ngram/af_2gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0ce0cab75f83c53a097010b2765735880a382f5bffd0e9d05fac9f3cbba823c4
|
| 3 |
+
size 10363466
|
models/word_ngram/af_2gram_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 2,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "af",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 2,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "af",
|
| 5 |
+
"unique_ngrams": 738183,
|
| 6 |
+
"total_ngrams": 38784545
|
| 7 |
}
|
models/word_ngram/af_3gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ed24c80ec95bb4f7b7f3e9b41efc4116210257d7e53719a017c664294f0cb056
|
| 3 |
+
size 23146048
|
models/word_ngram/af_3gram_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 3,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "af",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 3,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "af",
|
| 5 |
+
"unique_ngrams": 1499483,
|
| 6 |
+
"total_ngrams": 38658081
|
| 7 |
}
|
models/word_ngram/af_4gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:00b7902ab50f3ce3549864847da14b49603e12c990921c24438e1f9e61596ab4
|
| 3 |
+
size 40930272
|
models/word_ngram/af_4gram_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 4,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "af",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 4,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "af",
|
| 5 |
+
"unique_ngrams": 2510434,
|
| 6 |
+
"total_ngrams": 38531617
|
| 7 |
}
|
visualizations/embedding_isotropy.png
CHANGED

|

|
visualizations/embedding_norms.png
CHANGED

|
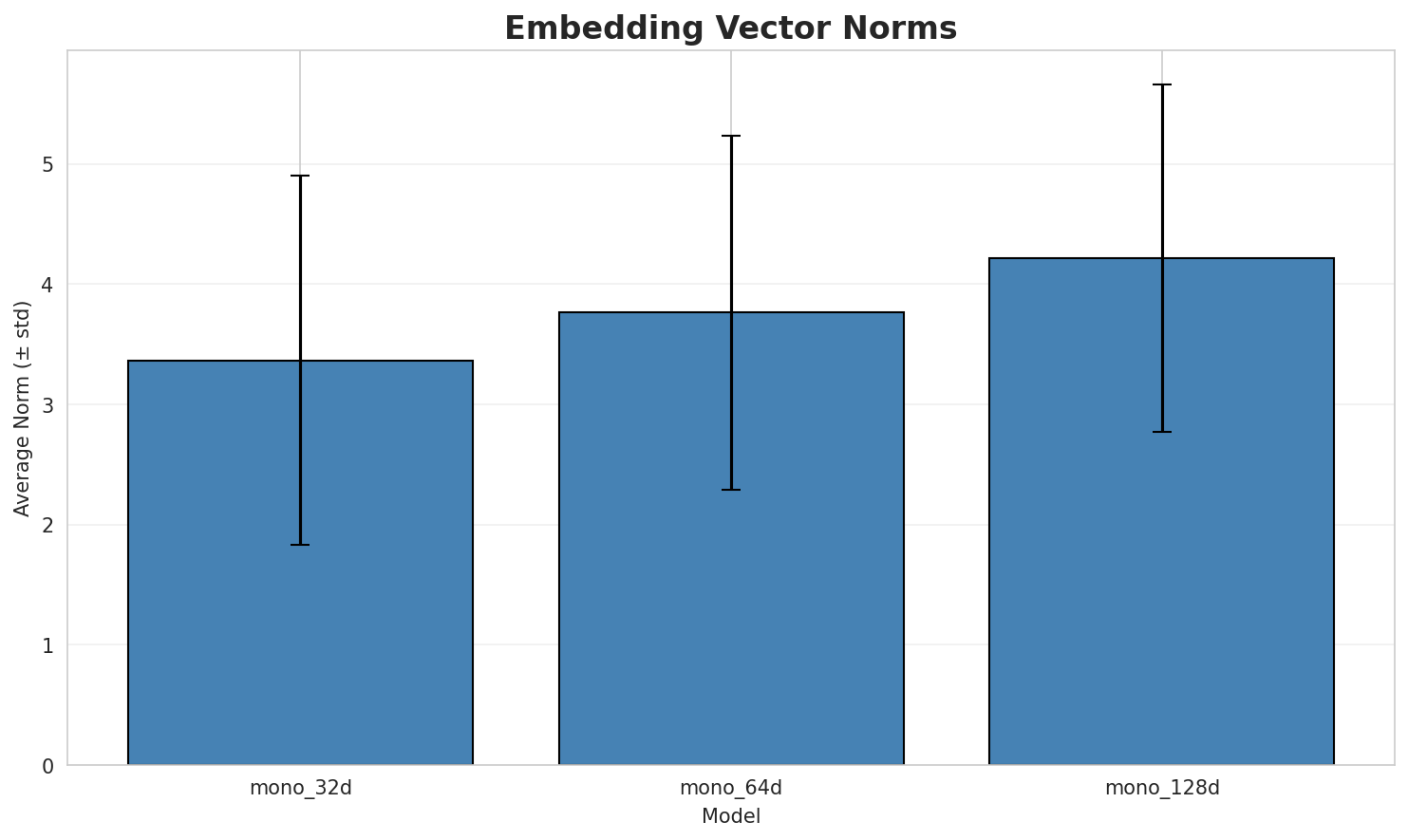
|
visualizations/embedding_similarity.png
CHANGED

|
Git LFS Details
|
|
Git LFS Details
|
visualizations/markov_branching.png
CHANGED

|

|
visualizations/markov_contexts.png
CHANGED

|

|