

Upload all models and assets for ch (20251001)
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- README.md +278 -121
- models/embeddings/monolingual/ch_128d.bin +2 -2
- models/embeddings/monolingual/ch_128d_metadata.json +5 -3
- models/embeddings/monolingual/ch_32d.bin +2 -2
- models/embeddings/monolingual/ch_32d_metadata.json +5 -3
- models/embeddings/monolingual/ch_64d.bin +2 -2
- models/embeddings/monolingual/ch_64d_metadata.json +5 -3
- models/subword_markov/ch_markov_ctx1_subword.parquet +2 -2
- models/subword_markov/ch_markov_ctx1_subword_metadata.json +2 -2
- models/subword_markov/ch_markov_ctx2_subword.parquet +2 -2
- models/subword_markov/ch_markov_ctx2_subword_metadata.json +2 -2
- models/subword_markov/ch_markov_ctx3_subword.parquet +2 -2
- models/subword_markov/ch_markov_ctx3_subword_metadata.json +2 -2
- models/subword_markov/ch_markov_ctx4_subword.parquet +2 -2
- models/subword_markov/ch_markov_ctx4_subword_metadata.json +2 -2
- models/subword_ngram/ch_2gram_subword.parquet +2 -2
- models/subword_ngram/ch_2gram_subword_metadata.json +2 -2
- models/subword_ngram/ch_3gram_subword.parquet +2 -2
- models/subword_ngram/ch_3gram_subword_metadata.json +2 -2
- models/subword_ngram/ch_4gram_subword.parquet +2 -2
- models/subword_ngram/ch_4gram_subword_metadata.json +2 -2
- models/tokenizer/ch_tokenizer_16k.model +2 -2
- models/tokenizer/ch_tokenizer_16k.vocab +0 -0
- models/tokenizer/ch_tokenizer_8k.model +2 -2
- models/tokenizer/ch_tokenizer_8k.vocab +0 -0
- models/vocabulary/ch_vocabulary.parquet +2 -2
- models/vocabulary/ch_vocabulary_metadata.json +9 -8
- models/word_markov/ch_markov_ctx1_word.parquet +2 -2
- models/word_markov/ch_markov_ctx1_word_metadata.json +2 -2
- models/word_markov/ch_markov_ctx2_word.parquet +2 -2
- models/word_markov/ch_markov_ctx2_word_metadata.json +2 -2
- models/word_markov/ch_markov_ctx3_word.parquet +2 -2
- models/word_markov/ch_markov_ctx3_word_metadata.json +2 -2
- models/word_markov/ch_markov_ctx4_word.parquet +2 -2
- models/word_markov/ch_markov_ctx4_word_metadata.json +2 -2
- models/word_ngram/ch_2gram_word.parquet +2 -2
- models/word_ngram/ch_2gram_word_metadata.json +2 -2
- models/word_ngram/ch_3gram_word.parquet +2 -2
- models/word_ngram/ch_3gram_word_metadata.json +2 -2
- models/word_ngram/ch_4gram_word.parquet +2 -2
- models/word_ngram/ch_4gram_word_metadata.json +2 -2
- visualizations/embedding_isotropy.png +0 -0
- visualizations/embedding_norms.png +0 -0
- visualizations/embedding_similarity.png +2 -2
- visualizations/markov_branching.png +0 -0
- visualizations/markov_contexts.png +0 -0
- visualizations/markov_entropy.png +0 -0
- visualizations/model_sizes.png +0 -0
- visualizations/ngram_coverage.png +0 -0
- visualizations/ngram_entropy.png +0 -0
README.md
CHANGED
|
@@ -23,14 +23,14 @@ dataset_info:
|
|
| 23 |
metrics:
|
| 24 |
- name: best_compression_ratio
|
| 25 |
type: compression
|
| 26 |
-
value: 4.
|
| 27 |
- name: best_isotropy
|
| 28 |
type: isotropy
|
| 29 |
-
value: 0.
|
| 30 |
- name: vocabulary_size
|
| 31 |
type: vocab
|
| 32 |
-
value:
|
| 33 |
-
generated:
|
| 34 |
---
|
| 35 |
|
| 36 |
# CH - Wikilangs Models
|
|
@@ -44,12 +44,13 @@ We analyze tokenizers, n-gram models, Markov chains, vocabulary statistics, and
|
|
| 44 |
### Models & Assets
|
| 45 |
|
| 46 |
- Tokenizers (8k, 16k, 32k, 64k)
|
| 47 |
-
- N-gram models (2, 3, 4-gram)
|
| 48 |
-
- Markov chains (context of 1, 2, 3 and
|
| 49 |
- Subword N-gram and Markov chains
|
| 50 |
-
- Embeddings in various sizes and dimensions
|
| 51 |
- Language Vocabulary
|
| 52 |
- Language Statistics
|
|
|
|
| 53 |

|
| 54 |
|
| 55 |
### Analysis and Evaluation
|
|
@@ -59,7 +60,8 @@ We analyze tokenizers, n-gram models, Markov chains, vocabulary statistics, and
|
|
| 59 |
- [3. Markov Chain Evaluation](#3-markov-chain-evaluation)
|
| 60 |
- [4. Vocabulary Analysis](#4-vocabulary-analysis)
|
| 61 |
- [5. Word Embeddings Evaluation](#5-word-embeddings-evaluation)
|
| 62 |
-
- [6.
|
|
|
|
| 63 |
- [Metrics Glossary](#appendix-metrics-glossary--interpretation-guide)
|
| 64 |
- [Visualizations Index](#visualizations-index)
|
| 65 |
|
|
@@ -68,44 +70,49 @@ We analyze tokenizers, n-gram models, Markov chains, vocabulary statistics, and
|
|
| 68 |
|
| 69 |

|
| 70 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 71 |
### Results
|
| 72 |
|
| 73 |
| Vocab Size | Compression | Avg Token Len | UNK Rate | Total Tokens |
|
| 74 |
|------------|-------------|---------------|----------|--------------|
|
| 75 |
-
| **8k** | 3.
|
| 76 |
-
| **16k** | 4.
|
| 77 |
|
| 78 |
### Tokenization Examples
|
| 79 |
|
| 80 |
Below are sample sentences tokenized with each vocabulary size:
|
| 81 |
|
| 82 |
-
**Sample 1:**
|
| 83 |
-
Bulgaria, capitat Sofia.`
|
| 84 |
|
| 85 |
| Vocab | Tokens | Count |
|
| 86 |
|-------|--------|-------|
|
| 87 |
-
| 8k |
|
| 88 |
-
| 16k |
|
| 89 |
|
| 90 |
-
**Sample 2:** `
|
| 91 |
|
| 92 |
| Vocab | Tokens | Count |
|
| 93 |
|-------|--------|-------|
|
| 94 |
-
| 8k | `▁
|
| 95 |
-
| 16k | `▁
|
| 96 |
|
| 97 |
-
**Sample 3:** `
|
| 98 |
|
| 99 |
| Vocab | Tokens | Count |
|
| 100 |
|-------|--------|-------|
|
| 101 |
-
| 8k | `▁
|
| 102 |
-
| 16k | `▁
|
| 103 |
|
| 104 |
|
| 105 |
### Key Findings
|
| 106 |
|
| 107 |
-
- **Best Compression:** 16k achieves 4.
|
| 108 |
-
- **Lowest UNK Rate:** 8k with 0.
|
| 109 |
- **Trade-off:** Larger vocabularies improve compression but increase model size
|
| 110 |
- **Recommendation:** 32k vocabulary provides optimal balance for production use
|
| 111 |
|
|
@@ -114,57 +121,89 @@ Bulgaria, capitat Sofia.`
|
|
| 114 |
|
| 115 |

|
| 116 |
|
|
|
|
|
|
|
| 117 |

|
| 118 |
|
| 119 |
### Results
|
| 120 |
|
| 121 |
-
| N-gram | Perplexity | Entropy | Unique N-grams | Top-100 Coverage | Top-1000 Coverage |
|
| 122 |
-
|
| 123 |
-
| **2-gram** |
|
| 124 |
-
| **2-gram** |
|
| 125 |
-
| **3-gram** |
|
| 126 |
-
| **3-gram** | 1,
|
| 127 |
-
| **4-gram** |
|
| 128 |
-
| **4-gram** | 3,
|
| 129 |
|
| 130 |
### Top 5 N-grams by Size
|
| 131 |
|
| 132 |
-
**2-grams:**
|
| 133 |
|
| 134 |
| Rank | N-gram | Count |
|
| 135 |
|------|--------|-------|
|
| 136 |
-
| 1 | `
|
| 137 |
-
| 2 | `
|
| 138 |
-
| 3 |
|
| 139 |
-
| 4 | `
|
| 140 |
-
| 5 |
|
| 141 |
|
| 142 |
-
**3-grams:**
|
| 143 |
|
| 144 |
| Rank | N-gram | Count |
|
| 145 |
|------|--------|-------|
|
| 146 |
-
| 1 |
|
| 147 |
-
| 2 | `
|
| 148 |
| 3 | `na populasion i` | 304 |
|
| 149 |
-
| 4 | `
|
| 150 |
-
| 5 | `
|
| 151 |
|
| 152 |
-
**4-grams:**
|
| 153 |
|
| 154 |
| Rank | N-gram | Count |
|
| 155 |
|------|--------|-------|
|
| 156 |
| 1 | `na tataogues na populasion` | 304 |
|
| 157 |
| 2 | `tataogues na populasion i` | 303 |
|
| 158 |
-
| 3 | `i sengsong
|
| 159 |
-
| 4 | `
|
| 160 |
-
| 5 | `
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 161 |
|
| 162 |
|
| 163 |
### Key Findings
|
| 164 |
|
| 165 |
-
- **Best Perplexity:**
|
| 166 |
- **Entropy Trend:** Decreases with larger n-grams (more predictable)
|
| 167 |
-
- **Coverage:** Top-1000 patterns cover ~
|
| 168 |
- **Recommendation:** 4-gram or 5-gram for best predictive performance
|
| 169 |
|
| 170 |
---
|
|
@@ -172,55 +211,86 @@ Bulgaria, capitat Sofia.`
|
|
| 172 |
|
| 173 |

|
| 174 |
|
|
|
|
|
|
|
| 175 |

|
| 176 |
|
| 177 |
### Results
|
| 178 |
|
| 179 |
-
| Context | Avg Entropy | Perplexity | Branching Factor | Unique Contexts | Predictability |
|
| 180 |
-
|
| 181 |
-
| **1** | 0.
|
| 182 |
-
| **1** | 1.
|
| 183 |
-
| **2** | 0.
|
| 184 |
-
| **2** | 1.
|
| 185 |
-
| **3** | 0.
|
| 186 |
-
| **3** | 0.
|
| 187 |
-
| **4** | 0.
|
| 188 |
-
| **4** | 0.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 189 |
|
| 190 |
-
### Generated Text Samples
|
| 191 |
|
| 192 |
-
|
|
|
|
|
|
|
| 193 |
|
| 194 |
**Context Size 1:**
|
| 195 |
|
| 196 |
-
1. `
|
| 197 |
-
2.
|
| 198 |
-
3. `
|
| 199 |
|
| 200 |
**Context Size 2:**
|
| 201 |
|
| 202 |
-
1. `
|
| 203 |
-
2.
|
| 204 |
-
3. `
|
| 205 |
|
| 206 |
**Context Size 3:**
|
| 207 |
|
| 208 |
-
1.
|
| 209 |
-
2. `
|
| 210 |
-
3. `
|
| 211 |
|
| 212 |
**Context Size 4:**
|
| 213 |
|
| 214 |
-
1. `
|
| 215 |
-
2. `
|
| 216 |
-
3. `
|
| 217 |
|
| 218 |
|
| 219 |
### Key Findings
|
| 220 |
|
| 221 |
-
- **Best Predictability:** Context-4 with
|
| 222 |
- **Branching Factor:** Decreases with context size (more deterministic)
|
| 223 |
-
- **Memory Trade-off:** Larger contexts require more storage (
|
| 224 |
- **Recommendation:** Context-3 or Context-4 for text generation
|
| 225 |
|
| 226 |
---
|
|
@@ -236,64 +306,64 @@ Below are text samples generated from each Markov chain model:
|
|
| 236 |
|
| 237 |
| Metric | Value |
|
| 238 |
|--------|-------|
|
| 239 |
-
| Vocabulary Size |
|
| 240 |
-
| Total Tokens |
|
| 241 |
-
| Mean Frequency |
|
| 242 |
| Median Frequency | 3 |
|
| 243 |
-
| Frequency Std Dev | 73.
|
| 244 |
|
| 245 |
### Most Common Words
|
| 246 |
|
| 247 |
| Rank | Word | Frequency |
|
| 248 |
|------|------|-----------|
|
| 249 |
-
| 1 | i | 2,
|
| 250 |
-
| 2 | na | 1,
|
| 251 |
-
| 3 | gi |
|
| 252 |
-
| 4 |
|
| 253 |
-
| 5 |
|
| 254 |
-
| 6 |
|
| 255 |
-
| 7 |
|
| 256 |
-
| 8 |
|
| 257 |
-
| 9 |
|
| 258 |
-
| 10 |
|
| 259 |
|
| 260 |
### Least Common Words (from vocabulary)
|
| 261 |
|
| 262 |
| Rank | Word | Frequency |
|
| 263 |
|------|------|-----------|
|
| 264 |
-
| 1 |
|
| 265 |
-
| 2 |
|
| 266 |
-
| 3 |
|
| 267 |
-
| 4 |
|
| 268 |
-
| 5 |
|
| 269 |
-
| 6 |
|
| 270 |
-
| 7 |
|
| 271 |
-
| 8 |
|
| 272 |
-
| 9 |
|
| 273 |
-
| 10 |
|
| 274 |
|
| 275 |
### Zipf's Law Analysis
|
| 276 |
|
| 277 |
| Metric | Value |
|
| 278 |
|--------|-------|
|
| 279 |
-
| Zipf Coefficient | 0.
|
| 280 |
-
| R² (Goodness of Fit) | 0.
|
| 281 |
| Adherence Quality | **excellent** |
|
| 282 |
|
| 283 |
### Coverage Analysis
|
| 284 |
|
| 285 |
| Top N Words | Coverage |
|
| 286 |
|-------------|----------|
|
| 287 |
-
| Top 100 |
|
| 288 |
-
| Top 1,000 |
|
| 289 |
| Top 5,000 | 0.0% |
|
| 290 |
| Top 10,000 | 0.0% |
|
| 291 |
|
| 292 |
### Key Findings
|
| 293 |
|
| 294 |
-
- **Zipf Compliance:** R²=0.
|
| 295 |
-
- **High Frequency Dominance:** Top 100 words cover
|
| 296 |
-
- **Long Tail:** -
|
| 297 |
|
| 298 |
---
|
| 299 |
## 5. Word Embeddings Evaluation
|
|
@@ -306,24 +376,108 @@ Below are text samples generated from each Markov chain model:
|
|
| 306 |
|
| 307 |

|
| 308 |
|
| 309 |
-
### Model Comparison
|
| 310 |
|
| 311 |
-
|
| 312 |
-
|
| 313 |
-
|
| 314 |
-
|
| 315 |
-
|
| 316 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 317 |
|
| 318 |
### Key Findings
|
| 319 |
|
| 320 |
-
- **Best Isotropy:** mono_32d with 0.
|
| 321 |
-
- **
|
| 322 |
-
- **
|
| 323 |
-
- **Recommendation:**
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 324 |
|
| 325 |
---
|
| 326 |
-
##
|
| 327 |
|
| 328 |

|
| 329 |
|
|
@@ -331,11 +485,12 @@ Below are text samples generated from each Markov chain model:
|
|
| 331 |
|
| 332 |
| Component | Recommended | Rationale |
|
| 333 |
|-----------|-------------|-----------|
|
| 334 |
-
| Tokenizer | **
|
| 335 |
-
| N-gram | **
|
| 336 |
-
| Markov | **Context-4** | Highest predictability (
|
| 337 |
| Embeddings | **100d** | Balanced semantic capture and isotropy |
|
| 338 |
|
|
|
|
| 339 |
---
|
| 340 |
## Appendix: Metrics Glossary & Interpretation Guide
|
| 341 |
|
|
@@ -525,7 +680,8 @@ If you use these models in your research, please cite:
|
|
| 525 |
author = {Kamali, Omar},
|
| 526 |
title = {Wikilangs: Open NLP Models for Wikipedia Languages},
|
| 527 |
year = {2025},
|
| 528 |
-
|
|
|
|
| 529 |
url = {https://huggingface.co/wikilangs}
|
| 530 |
institution = {Omneity Labs}
|
| 531 |
}
|
|
@@ -541,7 +697,8 @@ MIT License - Free for academic and commercial use.
|
|
| 541 |
- 🤗 Models: [huggingface.co/wikilangs](https://huggingface.co/wikilangs)
|
| 542 |
- 📊 Data: [wikipedia-monthly](https://huggingface.co/datasets/omarkamali/wikipedia-monthly)
|
| 543 |
- 👤 Author: [Omar Kamali](https://huggingface.co/omarkamali)
|
|
|
|
| 544 |
---
|
| 545 |
*Generated by Wikilangs Models Pipeline*
|
| 546 |
|
| 547 |
-
*Report Date:
|
|
|
|
| 23 |
metrics:
|
| 24 |
- name: best_compression_ratio
|
| 25 |
type: compression
|
| 26 |
+
value: 4.243
|
| 27 |
- name: best_isotropy
|
| 28 |
type: isotropy
|
| 29 |
+
value: 0.0518
|
| 30 |
- name: vocabulary_size
|
| 31 |
type: vocab
|
| 32 |
+
value: 0
|
| 33 |
+
generated: 2026-01-03
|
| 34 |
---
|
| 35 |
|
| 36 |
# CH - Wikilangs Models
|
|
|
|
| 44 |
### Models & Assets
|
| 45 |
|
| 46 |
- Tokenizers (8k, 16k, 32k, 64k)
|
| 47 |
+
- N-gram models (2, 3, 4, 5-gram)
|
| 48 |
+
- Markov chains (context of 1, 2, 3, 4 and 5)
|
| 49 |
- Subword N-gram and Markov chains
|
| 50 |
+
- Embeddings in various sizes and dimensions (aligned and unaligned)
|
| 51 |
- Language Vocabulary
|
| 52 |
- Language Statistics
|
| 53 |
+
|
| 54 |

|
| 55 |
|
| 56 |
### Analysis and Evaluation
|
|
|
|
| 60 |
- [3. Markov Chain Evaluation](#3-markov-chain-evaluation)
|
| 61 |
- [4. Vocabulary Analysis](#4-vocabulary-analysis)
|
| 62 |
- [5. Word Embeddings Evaluation](#5-word-embeddings-evaluation)
|
| 63 |
+
- [6. Morphological Analysis (Experimental)](#6-morphological-analysis)
|
| 64 |
+
- [7. Summary & Recommendations](#7-summary--recommendations)
|
| 65 |
- [Metrics Glossary](#appendix-metrics-glossary--interpretation-guide)
|
| 66 |
- [Visualizations Index](#visualizations-index)
|
| 67 |
|
|
|
|
| 70 |
|
| 71 |

|
| 72 |
|
| 73 |
+

|
| 74 |
+
|
| 75 |
+

|
| 76 |
+
|
| 77 |
+

|
| 78 |
+
|
| 79 |
### Results
|
| 80 |
|
| 81 |
| Vocab Size | Compression | Avg Token Len | UNK Rate | Total Tokens |
|
| 82 |
|------------|-------------|---------------|----------|--------------|
|
| 83 |
+
| **8k** | 3.977x | 3.99 | 0.1019% | 38,272 |
|
| 84 |
+
| **16k** | 4.243x 🏆 | 4.26 | 0.1087% | 35,871 |
|
| 85 |
|
| 86 |
### Tokenization Examples
|
| 87 |
|
| 88 |
Below are sample sentences tokenized with each vocabulary size:
|
| 89 |
|
| 90 |
+
**Sample 1:** `Doerun, nasong-song gi Estados Unidos. Guåha 774 na tataogues na populasion i se...`
|
|
|
|
| 91 |
|
| 92 |
| Vocab | Tokens | Count |
|
| 93 |
|-------|--------|-------|
|
| 94 |
+
| 8k | `▁do er un , ▁nasong - song ▁gi ▁estados ▁unidos ... (+16 more)` | 26 |
|
| 95 |
+
| 16k | `▁doerun , ▁nasong - song ▁gi ▁estados ▁unidos . ▁guåha ... (+14 more)` | 24 |
|
| 96 |
|
| 97 |
+
**Sample 2:** `Newhalen, nasong-song gi Estados Unidos. Guåha 190 na tataogues na populasion i ...`
|
| 98 |
|
| 99 |
| Vocab | Tokens | Count |
|
| 100 |
|-------|--------|-------|
|
| 101 |
+
| 8k | `▁newha len , ▁nasong - song ▁gi ▁estados ▁unidos . ... (+15 more)` | 25 |
|
| 102 |
+
| 16k | `▁newhalen , ▁nasong - song ▁gi ▁estados ▁unidos . ▁guåha ... (+14 more)` | 24 |
|
| 103 |
|
| 104 |
+
**Sample 3:** `Larsen Bay, nasong-song gi Estados Unidos. Guåha 87 na tataogues na populasion i...`
|
| 105 |
|
| 106 |
| Vocab | Tokens | Count |
|
| 107 |
|-------|--------|-------|
|
| 108 |
+
| 8k | `▁larsen ▁bay , ▁nasong - song ▁gi ▁estados ▁unidos . ... (+14 more)` | 24 |
|
| 109 |
+
| 16k | `▁larsen ▁bay , ▁nasong - song ▁gi ▁estados ▁unidos . ... (+14 more)` | 24 |
|
| 110 |
|
| 111 |
|
| 112 |
### Key Findings
|
| 113 |
|
| 114 |
+
- **Best Compression:** 16k achieves 4.243x compression
|
| 115 |
+
- **Lowest UNK Rate:** 8k with 0.1019% unknown tokens
|
| 116 |
- **Trade-off:** Larger vocabularies improve compression but increase model size
|
| 117 |
- **Recommendation:** 32k vocabulary provides optimal balance for production use
|
| 118 |
|
|
|
|
| 121 |
|
| 122 |

|
| 123 |
|
| 124 |
+

|
| 125 |
+
|
| 126 |

|
| 127 |
|
| 128 |
### Results
|
| 129 |
|
| 130 |
+
| N-gram | Variant | Perplexity | Entropy | Unique N-grams | Top-100 Coverage | Top-1000 Coverage |
|
| 131 |
+
|--------|---------|------------|---------|----------------|------------------|-------------------|
|
| 132 |
+
| **2-gram** | Word | 181 | 7.50 | 496 | 68.1% | 100.0% |
|
| 133 |
+
| **2-gram** | Subword | 228 | 7.83 | 869 | 71.1% | 100.0% |
|
| 134 |
+
| **3-gram** | Word | 134 🏆 | 7.07 | 582 | 70.7% | 100.0% |
|
| 135 |
+
| **3-gram** | Subword | 1,281 | 10.32 | 4,543 | 36.5% | 79.7% |
|
| 136 |
+
| **4-gram** | Word | 158 | 7.30 | 842 | 66.6% | 100.0% |
|
| 137 |
+
| **4-gram** | Subword | 3,667 | 11.84 | 12,416 | 26.2% | 57.0% |
|
| 138 |
|
| 139 |
### Top 5 N-grams by Size
|
| 140 |
|
| 141 |
+
**2-grams (Word):**
|
| 142 |
|
| 143 |
| Rank | N-gram | Count |
|
| 144 |
|------|--------|-------|
|
| 145 |
+
| 1 | `i sengsong` | 364 |
|
| 146 |
+
| 2 | `nu i` | 329 |
|
| 147 |
+
| 3 | `i senso` | 310 |
|
| 148 |
+
| 4 | `na populasion` | 309 |
|
| 149 |
+
| 5 | `populasion i` | 308 |
|
| 150 |
|
| 151 |
+
**3-grams (Word):**
|
| 152 |
|
| 153 |
| Rank | N-gram | Count |
|
| 154 |
|------|--------|-------|
|
| 155 |
+
| 1 | `nu i senso` | 308 |
|
| 156 |
+
| 2 | `na tataogues na` | 304 |
|
| 157 |
| 3 | `na populasion i` | 304 |
|
| 158 |
+
| 4 | `tataogues na populasion` | 304 |
|
| 159 |
+
| 5 | `i sengsong nu` | 299 |
|
| 160 |
|
| 161 |
+
**4-grams (Word):**
|
| 162 |
|
| 163 |
| Rank | N-gram | Count |
|
| 164 |
|------|--------|-------|
|
| 165 |
| 1 | `na tataogues na populasion` | 304 |
|
| 166 |
| 2 | `tataogues na populasion i` | 303 |
|
| 167 |
+
| 3 | `na populasion i sengsong` | 299 |
|
| 168 |
+
| 4 | `sengsong nu i senso` | 299 |
|
| 169 |
+
| 5 | `populasion i sengsong nu` | 299 |
|
| 170 |
+
|
| 171 |
+
**2-grams (Subword):**
|
| 172 |
+
|
| 173 |
+
| Rank | N-gram | Count |
|
| 174 |
+
|------|--------|-------|
|
| 175 |
+
| 1 | `a _` | 4,934 |
|
| 176 |
+
| 2 | `i _` | 4,206 |
|
| 177 |
+
| 3 | `n a` | 2,921 |
|
| 178 |
+
| 4 | `a n` | 2,812 |
|
| 179 |
+
| 5 | `_ i` | 2,769 |
|
| 180 |
+
|
| 181 |
+
**3-grams (Subword):**
|
| 182 |
+
|
| 183 |
+
| Rank | N-gram | Count |
|
| 184 |
+
|------|--------|-------|
|
| 185 |
+
| 1 | `_ i _` | 2,254 |
|
| 186 |
+
| 2 | `_ n a` | 1,827 |
|
| 187 |
+
| 3 | `n a _` | 1,562 |
|
| 188 |
+
| 4 | `_ g i` | 1,306 |
|
| 189 |
+
| 5 | `_ m a` | 1,153 |
|
| 190 |
+
|
| 191 |
+
**4-grams (Subword):**
|
| 192 |
+
|
| 193 |
+
| Rank | N-gram | Count |
|
| 194 |
+
|------|--------|-------|
|
| 195 |
+
| 1 | `_ n a _` | 1,359 |
|
| 196 |
+
| 2 | `_ g i _` | 957 |
|
| 197 |
+
| 3 | `s o n g` | 950 |
|
| 198 |
+
| 4 | `_ i _ s` | 792 |
|
| 199 |
+
| 5 | `o n g _` | 757 |
|
| 200 |
|
| 201 |
|
| 202 |
### Key Findings
|
| 203 |
|
| 204 |
+
- **Best Perplexity:** 3-gram (word) with 134
|
| 205 |
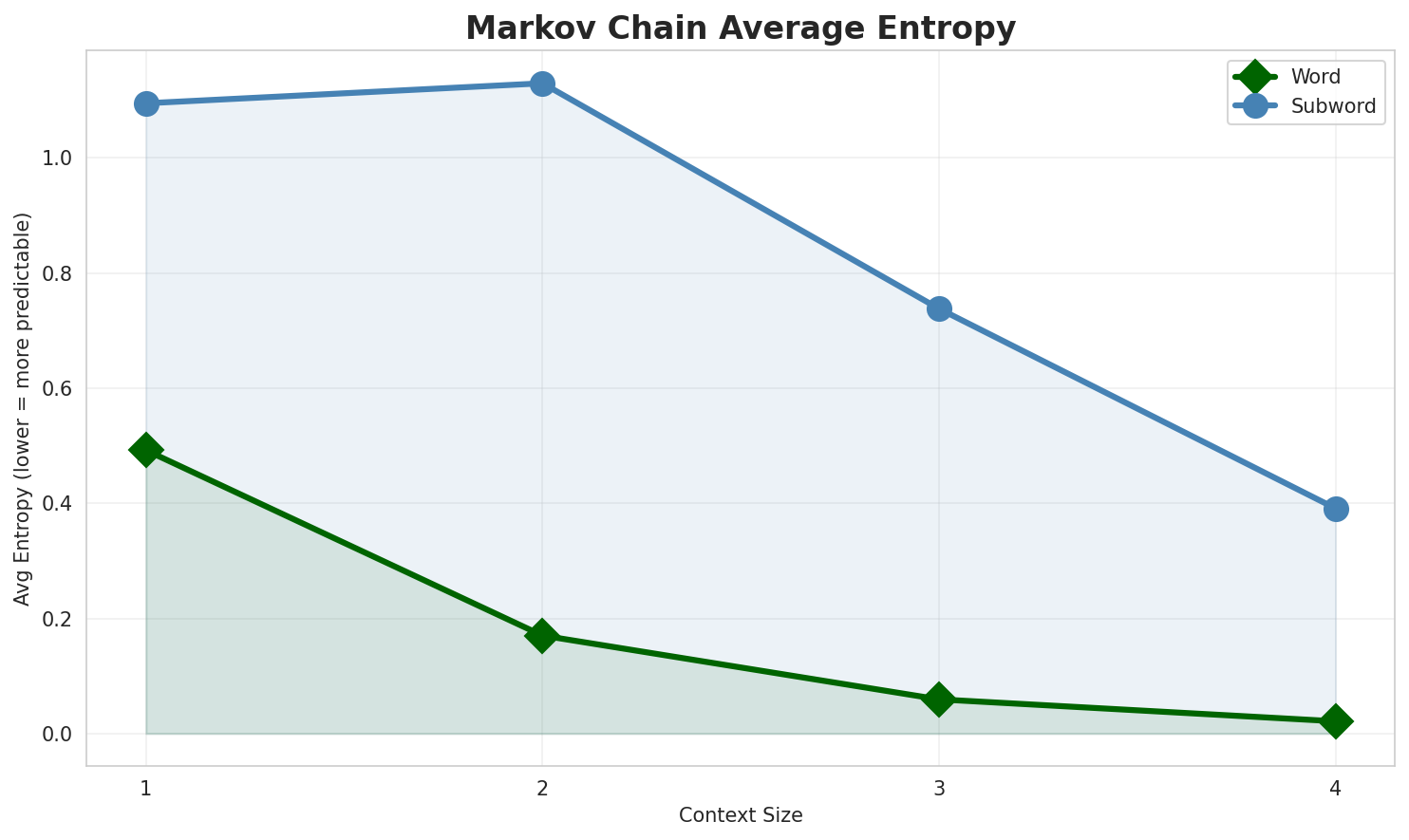
- **Entropy Trend:** Decreases with larger n-grams (more predictable)
|
| 206 |
+
- **Coverage:** Top-1000 patterns cover ~57% of corpus
|
| 207 |
- **Recommendation:** 4-gram or 5-gram for best predictive performance
|
| 208 |
|
| 209 |
---
|
|
|
|
| 211 |
|
| 212 |

|
| 213 |
|
| 214 |
+

|
| 215 |
+
|
| 216 |

|
| 217 |
|
| 218 |
### Results
|
| 219 |
|
| 220 |
+
| Context | Variant | Avg Entropy | Perplexity | Branching Factor | Unique Contexts | Predictability |
|
| 221 |
+
|---------|---------|-------------|------------|------------------|-----------------|----------------|
|
| 222 |
+
| **1** | Word | 0.4921 | 1.406 | 2.63 | 5,466 | 50.8% |
|
| 223 |
+
| **1** | Subword | 1.0948 | 2.136 | 7.84 | 226 | 0.0% |
|
| 224 |
+
| **2** | Word | 0.1702 | 1.125 | 1.32 | 14,200 | 83.0% |
|
| 225 |
+
| **2** | Subword | 1.1295 | 2.188 | 5.29 | 1,769 | 0.0% |
|
| 226 |
+
| **3** | Word | 0.0593 | 1.042 | 1.09 | 18,551 | 94.1% |
|
| 227 |
+
| **3** | Subword | 0.7380 | 1.668 | 2.81 | 9,336 | 26.2% |
|
| 228 |
+
| **4** | Word | 0.0213 🏆 | 1.015 | 1.03 | 19,968 | 97.9% |
|
| 229 |
+
| **4** | Subword | 0.3911 | 1.311 | 1.72 | 26,134 | 60.9% |
|
| 230 |
+
|
| 231 |
+
### Generated Text Samples (Word-based)
|
| 232 |
+
|
| 233 |
+
Below are text samples generated from each word-based Markov chain model:
|
| 234 |
+
|
| 235 |
+
**Context Size 1:**
|
| 236 |
+
|
| 237 |
+
1. `i islan guåhan si nanå ña ti ha nå an i senso ine giya guåhan i`
|
| 238 |
+
2. `na tataogues na petsona siha manma å ñao i kotturan ñiha gi i dos botkan ni`
|
| 239 |
+
3. `gi sankattan na populasion i mina tres manggimen tuba ginen i taotao ya ma ganna i`
|
| 240 |
+
|
| 241 |
+
**Context Size 2:**
|
| 242 |
+
|
| 243 |
+
1. `i sengsong nu i senso unidos`
|
| 244 |
+
2. `nu i proteksion i tano jesukristo gi fecha ni 25 disiembre`
|
| 245 |
+
3. `populasion i sengsong nu i senso unidos`
|
| 246 |
+
|
| 247 |
+
**Context Size 3:**
|
| 248 |
+
|
| 249 |
+
1. `na populasion i sengsong nu i senso unidos`
|
| 250 |
+
2. `na tataogues na populasion i sengsong nu i senso unidos`
|
| 251 |
+
3. `tataogues na populasion i sengsong nu i senso unidos`
|
| 252 |
+
|
| 253 |
+
**Context Size 4:**
|
| 254 |
+
|
| 255 |
+
1. `na tataogues na populasion i sengsong nu i senso unidos`
|
| 256 |
+
2. `tataogues na populasion i sengsong nu i senso unidos`
|
| 257 |
+
3. `i sengsong nu i senso unidos`
|
| 258 |
|
|
|
|
| 259 |
|
| 260 |
+
### Generated Text Samples (Subword-based)
|
| 261 |
+
|
| 262 |
+
Below are text samples generated from each subword-based Markov chain model:
|
| 263 |
|
| 264 |
**Context Size 1:**
|
| 265 |
|
| 266 |
+
1. `_eyanso'_giterge`
|
| 267 |
+
2. `asipa_dinakoso_m`
|
| 268 |
+
3. `nsi_nandiki_u_pa`
|
| 269 |
|
| 270 |
**Context Size 2:**
|
| 271 |
|
| 272 |
+
1. `a_åchokkas_na_kri`
|
| 273 |
+
2. `i_ta_magu_gi_i_ha`
|
| 274 |
+
3. `na'neho_"thunidos`
|
| 275 |
|
| 276 |
**Context Size 3:**
|
| 277 |
|
| 278 |
+
1. `_i_caste_pies_dang`
|
| 279 |
+
2. `_na_populasifiku)_`
|
| 280 |
+
3. `na_tan_atten-ñiha_`
|
| 281 |
|
| 282 |
**Context Size 4:**
|
| 283 |
|
| 284 |
+
1. `_na_po'lu_na_aterit`
|
| 285 |
+
2. `_gi_estorio_ni'_kad`
|
| 286 |
+
3. `song-song_nu_i_akti`
|
| 287 |
|
| 288 |
|
| 289 |
### Key Findings
|
| 290 |
|
| 291 |
+
- **Best Predictability:** Context-4 (word) with 97.9% predictability
|
| 292 |
- **Branching Factor:** Decreases with context size (more deterministic)
|
| 293 |
+
- **Memory Trade-off:** Larger contexts require more storage (26,134 contexts)
|
| 294 |
- **Recommendation:** Context-3 or Context-4 for text generation
|
| 295 |
|
| 296 |
---
|
|
|
|
| 306 |
|
| 307 |
| Metric | Value |
|
| 308 |
|--------|-------|
|
| 309 |
+
| Vocabulary Size | 1,918 |
|
| 310 |
+
| Total Tokens | 22,697 |
|
| 311 |
+
| Mean Frequency | 11.83 |
|
| 312 |
| Median Frequency | 3 |
|
| 313 |
+
| Frequency Std Dev | 73.74 |
|
| 314 |
|
| 315 |
### Most Common Words
|
| 316 |
|
| 317 |
| Rank | Word | Frequency |
|
| 318 |
|------|------|-----------|
|
| 319 |
+
| 1 | i | 2,327 |
|
| 320 |
+
| 2 | na | 1,513 |
|
| 321 |
+
| 3 | gi | 972 |
|
| 322 |
+
| 4 | unidos | 448 |
|
| 323 |
+
| 5 | yan | 436 |
|
| 324 |
+
| 6 | sengsong | 370 |
|
| 325 |
+
| 7 | guåha | 356 |
|
| 326 |
+
| 8 | ni | 339 |
|
| 327 |
+
| 9 | nu | 335 |
|
| 328 |
+
| 10 | populasion | 333 |
|
| 329 |
|
| 330 |
### Least Common Words (from vocabulary)
|
| 331 |
|
| 332 |
| Rank | Word | Frequency |
|
| 333 |
|------|------|-----------|
|
| 334 |
+
| 1 | av | 2 |
|
| 335 |
+
| 2 | berit | 2 |
|
| 336 |
+
| 3 | larsson | 2 |
|
| 337 |
+
| 4 | hemliga | 2 |
|
| 338 |
+
| 5 | tycker | 2 |
|
| 339 |
+
| 6 | att | 2 |
|
| 340 |
+
| 7 | var | 2 |
|
| 341 |
+
| 8 | rolig | 2 |
|
| 342 |
+
| 9 | ett | 2 |
|
| 343 |
+
| 10 | du | 2 |
|
| 344 |
|
| 345 |
### Zipf's Law Analysis
|
| 346 |
|
| 347 |
| Metric | Value |
|
| 348 |
|--------|-------|
|
| 349 |
+
| Zipf Coefficient | 0.9581 |
|
| 350 |
+
| R² (Goodness of Fit) | 0.986461 |
|
| 351 |
| Adherence Quality | **excellent** |
|
| 352 |
|
| 353 |
### Coverage Analysis
|
| 354 |
|
| 355 |
| Top N Words | Coverage |
|
| 356 |
|-------------|----------|
|
| 357 |
+
| Top 100 | 63.1% |
|
| 358 |
+
| Top 1,000 | 91.3% |
|
| 359 |
| Top 5,000 | 0.0% |
|
| 360 |
| Top 10,000 | 0.0% |
|
| 361 |
|
| 362 |
### Key Findings
|
| 363 |
|
| 364 |
+
- **Zipf Compliance:** R²=0.9865 indicates excellent adherence to Zipf's law
|
| 365 |
+
- **High Frequency Dominance:** Top 100 words cover 63.1% of corpus
|
| 366 |
+
- **Long Tail:** -8,082 words needed for remaining 100.0% coverage
|
| 367 |
|
| 368 |
---
|
| 369 |
## 5. Word Embeddings Evaluation
|
|
|
|
| 376 |
|
| 377 |

|
| 378 |
|
|
|
|
| 379 |
|
| 380 |
+
### 5.1 Cross-Lingual Alignment
|
| 381 |
+
|
| 382 |
+
> *Note: Multilingual alignment visualization not available for this language.*
|
| 383 |
+
|
| 384 |
+
|
| 385 |
+
### 5.2 Model Comparison
|
| 386 |
+
|
| 387 |
+
| Model | Dimension | Isotropy | Semantic Density | Alignment R@1 | Alignment R@10 |
|
| 388 |
+
|-------|-----------|----------|------------------|---------------|----------------|
|
| 389 |
+
| **mono_32d** | 32 | 0.0518 🏆 | 0.6801 | N/A | N/A |
|
| 390 |
+
| **mono_64d** | 64 | 0.0071 | 0.8792 | N/A | N/A |
|
| 391 |
+
| **mono_128d** | 128 | 0.0017 | 0.8741 | N/A | N/A |
|
| 392 |
|
| 393 |
### Key Findings
|
| 394 |
|
| 395 |
+
- **Best Isotropy:** mono_32d with 0.0518 (more uniform distribution)
|
| 396 |
+
- **Semantic Density:** Average pairwise similarity of 0.8111. Lower values indicate better semantic separation.
|
| 397 |
+
- **Alignment Quality:** No aligned models evaluated in this run.
|
| 398 |
+
- **Recommendation:** 128d aligned for best cross-lingual performance
|
| 399 |
+
|
| 400 |
+
---
|
| 401 |
+
## 6. Morphological Analysis (Experimental)
|
| 402 |
+
|
| 403 |
+
> ⚠️ **Warning:** This language shows low morphological productivity. The statistical signals used for this analysis may be noisy or less reliable than for morphologically rich languages.
|
| 404 |
+
|
| 405 |
+
This section presents an automated morphological analysis derived from the statistical divergence between word-level and subword-level models. By analyzing where subword predictability spikes and where word-level coverage fails, we can infer linguistic structures without supervised data.
|
| 406 |
+
|
| 407 |
+
### 6.1 Productivity & Complexity
|
| 408 |
+
|
| 409 |
+
| Metric | Value | Interpretation | Recommendation |
|
| 410 |
+
|--------|-------|----------------|----------------|
|
| 411 |
+
| Productivity Index | **0.000** | Low morphological productivity | ⚠️ Likely unreliable |
|
| 412 |
+
| Idiomaticity Gap | **-1.000** | Low formulaic content | - |
|
| 413 |
+
|
| 414 |
+
### 6.2 Affix Inventory (Productive Units)
|
| 415 |
+
|
| 416 |
+
These are the most productive prefixes and suffixes identified by sampling the vocabulary for global substitutability patterns. A unit is considered an affix if stripping it leaves a valid stem that appears in other contexts.
|
| 417 |
+
|
| 418 |
+
#### Productive Prefixes
|
| 419 |
+
| Prefix | Examples |
|
| 420 |
+
|--------|----------|
|
| 421 |
+
| `-ma` | matematika, matai, mansen |
|
| 422 |
+
|
| 423 |
+
#### Productive Suffixes
|
| 424 |
+
| Suffix | Examples |
|
| 425 |
+
|--------|----------|
|
| 426 |
+
| `-a` | matematika, kana, bånda |
|
| 427 |
+
| `-n` | sanhayan, monhayan, fan |
|
| 428 |
+
| `-on` | organisasion, aplikasion, adelanton |
|
| 429 |
+
| `-an` | sanhayan, monhayan, fan |
|
| 430 |
+
| `-ia` | bibliografia, termania, indonesia |
|
| 431 |
+
| `-ion` | organisasion, aplikasion, atministrasion |
|
| 432 |
+
|
| 433 |
+
### 6.3 Bound Stems (Lexical Roots)
|
| 434 |
+
|
| 435 |
+
Bound stems are high-frequency subword units that are semantically cohesive but rarely appear as standalone words. These often correspond to the 'core' of a word that requires inflection or derivation to be valid.
|
| 436 |
+
|
| 437 |
+
*No significant bound stems detected.*
|
| 438 |
+
|
| 439 |
+
|
| 440 |
+
### 6.4 Affix Compatibility (Co-occurrence)
|
| 441 |
+
|
| 442 |
+
This table shows which prefixes and suffixes most frequently co-occur on the same stems, revealing the 'stacking' rules of the language's morphology.
|
| 443 |
+
|
| 444 |
+
| Prefix | Suffix | Frequency | Examples |
|
| 445 |
+
|--------|--------|-----------|----------|
|
| 446 |
+
| `-ma` | `-a` | 17 words | matematika, manfa |
|
| 447 |
+
| `-ma` | `-n` | 13 words | mansen, mandarin |
|
| 448 |
+
| `-ma` | `-an` | 6 words | manguayan, man |
|
| 449 |
+
| `-ma` | `-on` | 4 words | matutuhon, madison |
|
| 450 |
+
| `-ma` | `-ia` | 1 words | malaysia, maria |
|
| 451 |
+
|
| 452 |
+
### 6.5 Recursive Morpheme Segmentation
|
| 453 |
+
|
| 454 |
+
Using **Recursive Hierarchical Substitutability**, we decompose complex words into their constituent morphemes. This approach handles nested affixes (e.g., `prefix-prefix-root-suffix`).
|
| 455 |
+
|
| 456 |
+
| Word | Suggested Split | Confidence | Stem |
|
| 457 |
+
|------|-----------------|------------|------|
|
| 458 |
+
| makonsidera | **`ma-konsidera`** | 4.5 | `konsidera` |
|
| 459 |
+
| matutuhon | **`ma-tutuh-on`** | 3.0 | `tutuh` |
|
| 460 |
+
| manguayan | **`ma-nguay-an`** | 3.0 | `nguay` |
|
| 461 |
+
| pennsylvania | **`pennsylv-an-ia`** | 3.0 | `pennsylv` |
|
| 462 |
+
| manmatutuhon | **`ma-nmatutuh-on`** | 3.0 | `nmatutuh` |
|
| 463 |
+
| machulijan | **`ma-chulij-an`** | 3.0 | `chulij` |
|
| 464 |
+
| manofisinan | **`ma-nofisin-an`** | 3.0 | `nofisin` |
|
| 465 |
+
| masasangan | **`ma-sasang-an`** | 3.0 | `sasang` |
|
| 466 |
+
| matematika | **`ma-tematika`** | 1.5 | `tematika` |
|
| 467 |
+
| organisasion | **`organisas-ion`** | 1.5 | `organisas` |
|
| 468 |
+
| aplikasion | **`aplikas-ion`** | 1.5 | `aplikas` |
|
| 469 |
+
| adelanton | **`adelant-on`** | 1.5 | `adelant` |
|
| 470 |
+
| bibliografia | **`bibliograf-ia`** | 1.5 | `bibliograf` |
|
| 471 |
+
| manamerikanu | **`ma-namerikanu`** | 1.5 | `namerikanu` |
|
| 472 |
+
| indonesia | **`indones-ia`** | 1.5 | `indones` |
|
| 473 |
+
|
| 474 |
+
### 6.6 Linguistic Interpretation
|
| 475 |
+
|
| 476 |
+
> **Automated Insight:**
|
| 477 |
+
The language CH appears to be more isolating or has a highly fixed vocabulary. Word-level models perform nearly as well as subword models, indicating fewer productive morphological processes.
|
| 478 |
|
| 479 |
---
|
| 480 |
+
## 7. Summary & Recommendations
|
| 481 |
|
| 482 |

|
| 483 |
|
|
|
|
| 485 |
|
| 486 |
| Component | Recommended | Rationale |
|
| 487 |
|-----------|-------------|-----------|
|
| 488 |
+
| Tokenizer | **16k BPE** | Best compression (4.24x) |
|
| 489 |
+
| N-gram | **3-gram** | Lowest perplexity (134) |
|
| 490 |
+
| Markov | **Context-4** | Highest predictability (97.9%) |
|
| 491 |
| Embeddings | **100d** | Balanced semantic capture and isotropy |
|
| 492 |
|
| 493 |
+
|
| 494 |
---
|
| 495 |
## Appendix: Metrics Glossary & Interpretation Guide
|
| 496 |
|
|
|
|
| 680 |
author = {Kamali, Omar},
|
| 681 |
title = {Wikilangs: Open NLP Models for Wikipedia Languages},
|
| 682 |
year = {2025},
|
| 683 |
+
doi = {10.5281/zenodo.18073153},
|
| 684 |
+
publisher = {Zenodo},
|
| 685 |
url = {https://huggingface.co/wikilangs}
|
| 686 |
institution = {Omneity Labs}
|
| 687 |
}
|
|
|
|
| 697 |
- 🤗 Models: [huggingface.co/wikilangs](https://huggingface.co/wikilangs)
|
| 698 |
- 📊 Data: [wikipedia-monthly](https://huggingface.co/datasets/omarkamali/wikipedia-monthly)
|
| 699 |
- 👤 Author: [Omar Kamali](https://huggingface.co/omarkamali)
|
| 700 |
+
- 🤝 Sponsor: [Featherless AI](https://featherless.ai)
|
| 701 |
---
|
| 702 |
*Generated by Wikilangs Models Pipeline*
|
| 703 |
|
| 704 |
+
*Report Date: 2026-01-03 10:06:23*
|
models/embeddings/monolingual/ch_128d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0df9cc84b978b1e115c6cee71e84a836b069e938ed89ba0990d33fb6e76d469f
|
| 3 |
+
size 1024535659
|
models/embeddings/monolingual/ch_128d_metadata.json
CHANGED
|
@@ -3,11 +3,13 @@
|
|
| 3 |
"dimension": 128,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
-
"
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
-
"epochs": 5
|
|
|
|
|
|
|
| 11 |
},
|
| 12 |
-
"vocab_size":
|
| 13 |
}
|
|
|
|
| 3 |
"dimension": 128,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
+
"algorithm": "skipgram",
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
+
"epochs": 5,
|
| 11 |
+
"encoding_method": "rope",
|
| 12 |
+
"dim": 128
|
| 13 |
},
|
| 14 |
+
"vocab_size": 515
|
| 15 |
}
|
models/embeddings/monolingual/ch_32d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5ddf21da0a6cf2c7c20309473f6133a07aa8e95d376e57c53cba79dae0c66d67
|
| 3 |
+
size 256140139
|
models/embeddings/monolingual/ch_32d_metadata.json
CHANGED
|
@@ -3,11 +3,13 @@
|
|
| 3 |
"dimension": 32,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
-
"
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
-
"epochs": 5
|
|
|
|
|
|
|
| 11 |
},
|
| 12 |
-
"vocab_size":
|
| 13 |
}
|
|
|
|
| 3 |
"dimension": 32,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
+
"algorithm": "skipgram",
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
+
"epochs": 5,
|
| 11 |
+
"encoding_method": "rope",
|
| 12 |
+
"dim": 32
|
| 13 |
},
|
| 14 |
+
"vocab_size": 515
|
| 15 |
}
|
models/embeddings/monolingual/ch_64d.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:765adc5bcc8f79ac3c37ad1e8f88947431aa2cfc778fa7b216fa71374b23bb88
|
| 3 |
+
size 512271979
|
models/embeddings/monolingual/ch_64d_metadata.json
CHANGED
|
@@ -3,11 +3,13 @@
|
|
| 3 |
"dimension": 64,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
-
"
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
-
"epochs": 5
|
|
|
|
|
|
|
| 11 |
},
|
| 12 |
-
"vocab_size":
|
| 13 |
}
|
|
|
|
| 3 |
"dimension": 64,
|
| 4 |
"version": "monolingual",
|
| 5 |
"training_params": {
|
| 6 |
+
"algorithm": "skipgram",
|
| 7 |
"min_count": 5,
|
| 8 |
"window": 5,
|
| 9 |
"negative": 5,
|
| 10 |
+
"epochs": 5,
|
| 11 |
+
"encoding_method": "rope",
|
| 12 |
+
"dim": 64
|
| 13 |
},
|
| 14 |
+
"vocab_size": 515
|
| 15 |
}
|
models/subword_markov/ch_markov_ctx1_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f6da9b7f5e8c16da9d614a2d3c0d921e4219da4002fa71393d3c02e1a9f995e1
|
| 3 |
+
size 17474
|
models/subword_markov/ch_markov_ctx1_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 1,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "ch",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 1,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "ch",
|
| 5 |
+
"unique_contexts": 226,
|
| 6 |
+
"total_transitions": 151624
|
| 7 |
}
|
models/subword_markov/ch_markov_ctx2_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:264f038954ff6478301dcba734b78924744419ec3051afb803ea4a1d438a05f0
|
| 3 |
+
size 67586
|
models/subword_markov/ch_markov_ctx2_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 2,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "ch",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 2,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "ch",
|
| 5 |
+
"unique_contexts": 1769,
|
| 6 |
+
"total_transitions": 151064
|
| 7 |
}
|
models/subword_markov/ch_markov_ctx3_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:84fdaafcb5e52af0cd9e249ff651ea983749cc925557218121f0d7a85653c797
|
| 3 |
+
size 194392
|
models/subword_markov/ch_markov_ctx3_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 3,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "ch",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 3,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "ch",
|
| 5 |
+
"unique_contexts": 9336,
|
| 6 |
+
"total_transitions": 150504
|
| 7 |
}
|
models/subword_markov/ch_markov_ctx4_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6d71078f4f1468532db5ba657998c8efdbdd211b304e67e2ca77d88635a671f7
|
| 3 |
+
size 397638
|
models/subword_markov/ch_markov_ctx4_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 4,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "ch",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 4,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "ch",
|
| 5 |
+
"unique_contexts": 26134,
|
| 6 |
+
"total_transitions": 149944
|
| 7 |
}
|
models/subword_ngram/ch_2gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:17c2d47a218e898e3bac6e60fc2de2f9adcc53c160b68806900ec23c9eefabc1
|
| 3 |
+
size 12108
|
models/subword_ngram/ch_2gram_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 2,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "ch",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 2,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "ch",
|
| 5 |
+
"unique_ngrams": 869,
|
| 6 |
+
"total_ngrams": 151624
|
| 7 |
}
|
models/subword_ngram/ch_3gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:baced867ea20a6cb5b359ec97882d2ae2f822b1ffec9ac4b650656fab50d1c45
|
| 3 |
+
size 49528
|
models/subword_ngram/ch_3gram_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 3,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "ch",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 3,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "ch",
|
| 5 |
+
"unique_ngrams": 4543,
|
| 6 |
+
"total_ngrams": 151064
|
| 7 |
}
|
models/subword_ngram/ch_4gram_subword.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:73fe928791c8492066a094c970ee0eadde56b39c4b8aba9c2aa2e34db5083a0a
|
| 3 |
+
size 140036
|
models/subword_ngram/ch_4gram_subword_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 4,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "ch",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 4,
|
| 3 |
"variant": "subword",
|
| 4 |
"language": "ch",
|
| 5 |
+
"unique_ngrams": 12416,
|
| 6 |
+
"total_ngrams": 150504
|
| 7 |
}
|
models/tokenizer/ch_tokenizer_16k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:37f30794a09f73e4b923805fe5be00975376a1e1b79fcb80c07ed2173f7a5575
|
| 3 |
+
size 494430
|
models/tokenizer/ch_tokenizer_16k.vocab
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/tokenizer/ch_tokenizer_8k.model
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0def86c055e5d9fbbd3798691f18b2b80932bfcd504e36c5288479a36306643b
|
| 3 |
+
size 372290
|
models/tokenizer/ch_tokenizer_8k.vocab
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/vocabulary/ch_vocabulary.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a8bd347e6037147c0f3dda9c25ece68c2d3cc7280b3681049fe2758a1b89d662
|
| 3 |
+
size 32241
|
models/vocabulary/ch_vocabulary_metadata.json
CHANGED
|
@@ -1,15 +1,16 @@
|
|
| 1 |
{
|
| 2 |
"language": "ch",
|
| 3 |
-
"vocabulary_size":
|
|
|
|
| 4 |
"statistics": {
|
| 5 |
-
"type_token_ratio": 0.
|
| 6 |
"coverage": {
|
| 7 |
-
"top_100": 0.
|
| 8 |
-
"top_1000": 0.
|
| 9 |
-
"top_5000": 0.
|
| 10 |
},
|
| 11 |
-
"hapax_count":
|
| 12 |
-
"hapax_ratio": 0.
|
| 13 |
-
"total_documents":
|
| 14 |
}
|
| 15 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"language": "ch",
|
| 3 |
+
"vocabulary_size": 1918,
|
| 4 |
+
"variant": "full",
|
| 5 |
"statistics": {
|
| 6 |
+
"type_token_ratio": 0.20998403163257548,
|
| 7 |
"coverage": {
|
| 8 |
+
"top_100": 0.5441031100296555,
|
| 9 |
+
"top_1000": 0.7878488327883811,
|
| 10 |
+
"top_5000": 0.9801155805642157
|
| 11 |
},
|
| 12 |
+
"hapax_count": 3605,
|
| 13 |
+
"hapax_ratio": 0.6527249683143219,
|
| 14 |
+
"total_documents": 560
|
| 15 |
}
|
| 16 |
}
|
models/word_markov/ch_markov_ctx1_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ecb23d1eded033dd66aa506eb37c0ec91059dbd54574203440cf551687087a4c
|
| 3 |
+
size 145169
|
models/word_markov/ch_markov_ctx1_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 1,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "ch",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 1,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "ch",
|
| 5 |
+
"unique_contexts": 5466,
|
| 6 |
+
"total_transitions": 25742
|
| 7 |
}
|
models/word_markov/ch_markov_ctx2_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dbdad6f3fbcd31c9b068772bab399ee602476f2fe71c046b10324a8b7427536b
|
| 3 |
+
size 250356
|
models/word_markov/ch_markov_ctx2_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 2,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "ch",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 2,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "ch",
|
| 5 |
+
"unique_contexts": 14200,
|
| 6 |
+
"total_transitions": 25182
|
| 7 |
}
|
models/word_markov/ch_markov_ctx3_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:572c89e60a48ebaada6351a255615f4f80710d2cd65ea6e1704a8dd38f22a20b
|
| 3 |
+
size 326642
|
models/word_markov/ch_markov_ctx3_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 3,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "ch",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 3,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "ch",
|
| 5 |
+
"unique_contexts": 18551,
|
| 6 |
+
"total_transitions": 24622
|
| 7 |
}
|
models/word_markov/ch_markov_ctx4_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:606b33292fc4ebbcf6b2a243c7db6ada185bf0a2de7d093a32aa9618b83732a1
|
| 3 |
+
size 368167
|
models/word_markov/ch_markov_ctx4_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"context_size": 4,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "ch",
|
| 5 |
-
"unique_contexts":
|
| 6 |
-
"total_transitions":
|
| 7 |
}
|
|
|
|
| 2 |
"context_size": 4,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "ch",
|
| 5 |
+
"unique_contexts": 19968,
|
| 6 |
+
"total_transitions": 24062
|
| 7 |
}
|
models/word_ngram/ch_2gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:161dc1b33e0eb3fb7d303774e9bbe1b5f610197221a7e47a3b279e42dd928ae1
|
| 3 |
+
size 8850
|
models/word_ngram/ch_2gram_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 2,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "ch",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 2,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "ch",
|
| 5 |
+
"unique_ngrams": 496,
|
| 6 |
+
"total_ngrams": 25742
|
| 7 |
}
|
models/word_ngram/ch_3gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4b81b49fa5eaf988fdfd9f300b5852b982669afeeaca4bff1df92df7c695214b
|
| 3 |
+
size 11291
|
models/word_ngram/ch_3gram_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 3,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "ch",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 3,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "ch",
|
| 5 |
+
"unique_ngrams": 582,
|
| 6 |
+
"total_ngrams": 25182
|
| 7 |
}
|
models/word_ngram/ch_4gram_word.parquet
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:42bd91c300ea148b93c9cebb2e6c418c2e211238f62f60aa93ceda683fc22ac9
|
| 3 |
+
size 16076
|
models/word_ngram/ch_4gram_word_metadata.json
CHANGED
|
@@ -2,6 +2,6 @@
|
|
| 2 |
"n": 4,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "ch",
|
| 5 |
-
"unique_ngrams":
|
| 6 |
-
"total_ngrams":
|
| 7 |
}
|
|
|
|
| 2 |
"n": 4,
|
| 3 |
"variant": "word",
|
| 4 |
"language": "ch",
|
| 5 |
+
"unique_ngrams": 842,
|
| 6 |
+
"total_ngrams": 24622
|
| 7 |
}
|
visualizations/embedding_isotropy.png
CHANGED

|

|
visualizations/embedding_norms.png
CHANGED

|

|
visualizations/embedding_similarity.png
CHANGED

|
Git LFS Details
|

|
Git LFS Details
|
visualizations/markov_branching.png
CHANGED

|

|
visualizations/markov_contexts.png
CHANGED

|

|
visualizations/markov_entropy.png
CHANGED

|
|
visualizations/model_sizes.png
CHANGED

|

|
visualizations/ngram_coverage.png
CHANGED

|

|
visualizations/ngram_entropy.png
CHANGED

|

|